Do Zero a 9 Serviços no Kubernetes Com OrbStack
Três dias atrás, eu não conseguiria te dizer a diferença entre um Pod e um Deployment. Não honestamente. Tinha lido sobre Kubernetes talvez uma dúzia de vezes, acenado com a cabeça para diagramas de arquitetura, e discretamente fechado a aba toda vez que um tutorial chegava na seção de kubectl apply. Parecia conhecimento de infraestrutura destinado a outra pessoa — engenheiros de plataforma, especialistas em DevOps, pessoas que sonham em YAML.
Então eu precisei colocar o InfraWhisper no ar.
InfraWhisper é uma plataforma de monitoramento e analytics que venho construindo — dashboard, servidor API, motor de IA, coletor de dados, processador de streams, mais os bancos de dados e message brokers que sustentam tudo. Nove serviços no total. Executá-los com docker-compose up funcionava bem no meu notebook. Mas no momento em que comecei a pensar em produção — sobre o que acontece quando o servidor API cai às 3 da manhã, sobre escalar o processador de streams durante picos de tráfego, sobre fazer deploy de atualizações sem derrubar o dashboard — o Docker Compose começou a parecer uma bicicleta numa rodovia.
Então sentei com Kubernetes. E OrbStack. E três dias de persistência teimosa.
O que saiu do outro lado foi um cluster local totalmente orquestrado com todos os nove serviços do InfraWhisper rodando, se auto-reparando e acessíveis através de um único ponto de entrada ingress. Este post é tudo que aprendi fazendo isso — os modelos mentais que realmente fizeram sentido, os comandos que importam e os erros que me custaram horas para que não custem o mesmo a você.
Por Que Parei de Tratar Kubernetes Como Opcional
Eis o que finalmente me fez dar o passo. Eu tinha o InfraWhisper rodando em Docker Compose num servidor de staging. Cinco serviços, quatro bancos de dados, tudo se comunicando através de uma rede Docker. Funcionava. Então o contêiner do Kafka ficou sem memória e morreu.
Nada o reiniciou. O processador de streams, que depende do Kafka, começou a lançar erros de conexão. O coletor, que envia eventos para o Kafka, começou a descartar dados silenciosamente. O dashboard continuava carregando — tudo parecia bem — mas todo o pipeline de analytics estava morto. Não percebi por seis horas.
Com Docker sozinho, um contêiner que cai permanece caído. Você precisa de ferramentas externas — systemd, supervisord, scripts de health check customizados — para adicionar a confiabilidade que deveria vir embutida. Você está montando um Frankenstein de scripts bash e rezando para que cubram cada modo de falha.
Kubernetes lida com isso nativamente. Um contêiner morre, Kubernetes o reinicia. Um nó cai, Kubernetes reagenda pods em nós saudáveis. Você faz deploy de uma atualização com problema, executa um comando e volta para a versão anterior. Isso não é resiliência teórica — é como a infraestrutura de produção realmente funciona em empresas com cargas de trabalho reais.
A distância entre "eu entendo por que Kubernetes importa" e "eu realmente consigo fazer deploy no Kubernetes" parecia enorme vista de fora. Não era. E o OrbStack tornou essa distância ainda menor.
Mas antes de entrar na configuração, você precisa do modelo mental. Porque os comandos do Kubernetes não fazem nenhum sentido até você entender os seis conceitos sobre os quais eles operam.
Os Seis Conceitos de Kubernetes Que Realmente Importam
Já li documentação de Kubernetes que introduz quarenta conceitos no primeiro capítulo. Isso é avassalador e, honestamente, contraproducente. Quando estava aprendendo, apenas seis conceitos importaram para fazer deploy de uma aplicação real. Todo o resto é otimização que você pode aprender depois.
Container. Docker empacota seu código de aplicação, dependências e runtime em uma única unidade portátil. Você o constrói uma vez, e ele roda de forma idêntica no seu notebook, num servidor CI ou numa VM na nuvem. Se você já usou Docker, já conhece este. O contêiner é o átomo.
Pod. Kubernetes não executa contêineres diretamente. Ele os envolve num Pod — a menor unidade implantável no K8s. Um Pod geralmente é um contêiner, às vezes dois se você precisa de um sidecar (como um encaminhador de logs rodando junto à sua app). Pense no Pod como um contêiner com um endereço postal.
Deployment. É aqui que Kubernetes começa a justificar sua complexidade. Um Deployment define quantas cópias (réplicas) de um Pod devem estar rodando a qualquer momento. Se você diz "quero 3 réplicas do servidor API" e uma cai, Kubernetes percebe a lacuna e levanta um substituto automaticamente. Você declara o estado desejado. Kubernetes faz a realidade corresponder.
Service. Pods recebem endereços IP aleatórios que mudam toda vez que reiniciam. Um Service dá ao seu Pod um nome DNS estável — para que o dashboard possa alcançar o servidor API em api-server:8080 em vez de ficar caçando qual IP o Pod recebeu dessa vez. Services são a lista telefônica interna do seu cluster.
Ingress. Services lidam com tráfego dentro do cluster. Ingress lida com tráfego vindo de fora — requisições do navegador, chamadas de API, webhooks. É a porta de entrada, roteando app.local/api para o service do servidor API e app.local/dashboard para o service do dashboard.
Namespace. Um limite lógico que agrupa recursos relacionados. Todos os nove serviços do InfraWhisper vivem no namespace infrawhisper. Isso os mantém isolados dos serviços do sistema e de qualquer outra coisa rodando no cluster. Também é por isso que quase todo comando kubectl que vou mostrar termina com -n infrawhisper.
É isso. Contêiner vai dentro de um Pod. Deployment gerencia quantos Pods rodam. Service dá a eles nomes estáveis. Ingress roteia tráfego externo. Namespace mantém tudo organizado.
Com esse modelo mental carregado, os comandos começam a fazer sentido intuitivo. E falando em comandos — deixe-me contar sobre a ferramenta que fez rodar tudo isso localmente parecer quase sem esforço.
Por Que OrbStack Mudou Toda Minha Experiência
Já tinha tentado Docker Desktop antes. Funcionava, mas "funcionava" está fazendo muito trabalho nessa frase. O uso de memória era brutal — 4 a 6 GB só parado. A integração Kubernetes parecia grudada, frequentemente ficando para trás ou se comportando diferente de clusters reais. Iniciar levava tempo suficiente para eu abrir o Twitter enquanto esperava, que é como você perde vinte minutos antes de escrever uma única linha de código.
OrbStack é diferente de formas que genuinamente importam para aprender Kubernetes.
É leve. Iniciar leva segundos, não minutos. O uso de memória se mantém razoável — em torno de 1.5 a 2 GB mesmo com um cluster Kubernetes completo rodando. Num Mac com chip M, parece nativo de uma forma que Docker Desktop nunca conseguiu.
A integração Kubernetes vem embutida e simplesmente funciona. Um toggle nas configurações, e você tem um cluster de nó único rodando localmente. Sem minikube. Sem kind. Sem configurar drivers de VM. OrbStack te dá um cluster Kubernetes real apoiado por containerd, acessível através dos comandos padrão kubectl e helm. Seu kubeconfig é atualizado automaticamente.
Mas a funcionalidade que me economizou mais tempo — e eu não esperava isso — é a interface visual. OrbStack mostra seus contêineres em execução, pods, uso de recursos e logs numa GUI limpa. Quando você está aprendendo Kubernetes e um pod fica em crash-loop, poder ver o que está acontecendo nos nove serviços simultaneamente vale mais que qualquer saída de terminal. Eu ficava com o dashboard do OrbStack num monitor e meu terminal no outro, vendo pods subir em tempo real enquanto aplicava configurações.
Quero ser claro: OrbStack não é um brinquedo nem um atalho. O cluster que ele roda se comporta como um cluster Kubernetes real. Tudo que aprendi e fiz deploy localmente se transferiu diretamente quando depois apontei o kubectl para um cluster remoto. OrbStack simplesmente removeu a fricção que não estava me ensinando nada útil.
Colocá-lo para rodar levou cerca de cinco minutos. Instale OrbStack de orbstack.dev, abra-o, habilite Kubernetes nas configurações, e verifique com:
kubectl cluster-info
kubectl get nodes
Se ambos os comandos retornam uma saída limpa, você tem um cluster funcionando. Hora de fazer deploy de algo real.
Como a Arquitetura do Kubernetes Realmente Funciona Por Baixo dos Panos?
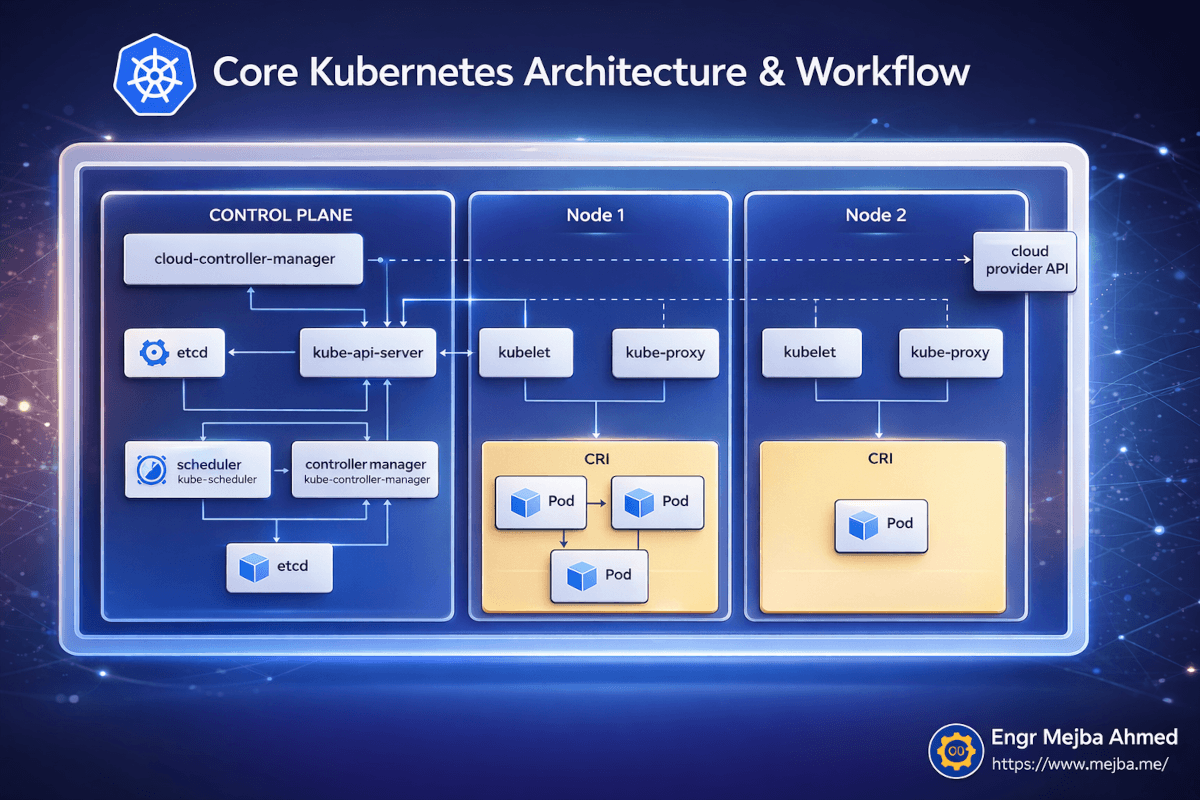
Antes de começar a fazer deploy de serviços, passei uma hora entendendo o que realmente estava rodando na minha máquina. Isso se pagou enormemente quando as coisas quebraram depois, porque eu conseguia raciocinar sobre onde no sistema o problema estava.
Kubernetes segue uma arquitetura de plano de controle e nós worker. Mesmo num cluster local de nó único como o que OrbStack fornece, ambos os papéis rodam na mesma máquina.
O Plano de Controle é o cérebro. Ele tem cinco componentes que importam:
O kube-api-server é a porta de entrada para tudo. Cada comando kubectl que você executa fala com este servidor API. Ele valida suas requisições, atualiza o estado do cluster e diz aos nós o que fazer. Quando executo kubectl apply -f deployment.yaml, estou enviando esse YAML para o servidor API, que armazena o estado desejado e orquestra sua materialização.
etcd é o banco de dados que armazena todo o estado do cluster. Cada deployment, cada service, cada status de pod — tudo está no etcd. Nunca o toquei diretamente, mas saber que ele existe explica por que Kubernetes consegue se recuperar de quase qualquer coisa. O estado desejado está sempre persistido.
O scheduler decide qual nó deve rodar cada novo pod. Num cluster multi-nó, é aqui que acontece o bin-packing e a otimização de recursos. Na minha configuração OrbStack de nó único, cada pod vai para o mesmo nó — mas o scheduler continua rodando, e entendê-lo ajudou quando migrei para multi-nó depois.
O controller manager executa os loops de reconciliação que tornam Kubernetes auto-reparável. Ele constantemente compara "o que deveria estar rodando" (o estado desejado no etcd) contra "o que realmente está rodando" (o estado atual dos relatórios dos nós). Quando há um descompasso, ele age. Pod caiu? O controller manager percebe e diz ao scheduler para criar um substituto.
O cloud-controller-manager lida com integrações com provedores de nuvem — balanceadores de carga, volumes de armazenamento, ciclo de vida de nós. Num cluster local OrbStack, isso está quase sempre inativo, mas é bom saber que existe para quando você fizer deploy na AWS ou GCP.
No lado do Nó, três coisas rodam:
kubelet é o agente em cada nó que recebe instruções do servidor API e gerencia pods naquele nó. Ele baixa imagens de contêiner, inicia contêineres, reporta saúde ao plano de controle.
kube-proxy lida com o roteamento de rede dentro do nó, garantindo que o tráfego direcionado a um Service chegue ao Pod correto.
CRI (Container Runtime Interface) é o runtime de contêiner real — containerd no caso do OrbStack — que executa seus contêineres.
Eis por que essa visão geral da arquitetura não é apenas acadêmica: quando meu pod do servidor API ficava em crash-loop, eu sabia verificar kubectl describe pod (que consulta o servidor API por eventos do pod) em vez de só ficar olhando logs. A saída do describe me disse que o contêiner estava sendo OOM-killed — um problema de limite de recursos, não um problema de código. Sem o modelo mental de como os componentes do Kubernetes interagem, teria perdido horas debugando código de aplicação que na verdade estava bem.
Agora — deixe-me guiá-lo pelo deploy de todos os nove serviços do InfraWhisper. É aqui que a teoria vira prática.
Fazendo Deploy do InfraWhisper: 9 Serviços, Um Cluster, Zero Orações
O stack do InfraWhisper tem nove serviços que precisam subir numa ordem específica e se comunicar entre si de forma confiável:
Camada de infraestrutura: Postgres (banco de dados principal), Redis (cache e sessões), Kafka (streaming de eventos), ClickHouse (banco de dados analítico)
Camada de aplicação: API Server (endpoints REST), AI Engine (inferência ML), Collector (ingestão de eventos), Stream Processor (pipeline de dados em tempo real), Dashboard (UI frontend)
No Docker Compose, eu definiria todos os nove num arquivo com diretivas depends_on e cruzaria os dedos. No Kubernetes, cada serviço ganha seu próprio Deployment e definição de Service, e a orquestração é tratada adequadamente.
Passo 1: Criar o namespace.
Tudo do InfraWhisper vive no seu próprio namespace. Foi a primeira coisa que criei:
kubectl create namespace infrawhisper
Um comando, e agora tenho um espaço isolado para toda a aplicação. Todo comando daqui pra frente usa -n infrawhisper para apontar para este namespace.
Passo 2: Fazer deploy dos serviços de infraestrutura primeiro.
Bancos de dados e message brokers precisam estar rodando antes dos serviços de aplicação que dependem deles. Escrevi manifestos Kubernetes (arquivos YAML) para cada um — um Deployment definindo a imagem do contêiner e limites de recursos, e um Service definindo como outros pods podem alcançá-lo.
Aqui está um exemplo simplificado para Postgres:
# deploy/k8s/postgres-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: postgres
namespace: infrawhisper
spec:
replicas: 1
selector:
matchLabels:
app: postgres
template:
metadata:
labels:
app: postgres
spec:
containers:
- name: postgres
image: postgres:16.2
ports:
- containerPort: 5432
env:
- name: POSTGRES_DB
value: "infrawhisper"
- name: POSTGRES_USER
valueFrom:
secretKeyRef:
name: db-credentials
key: username
- name: POSTGRES_PASSWORD
valueFrom:
secretKeyRef:
name: db-credentials
key: password
resources:
requests:
memory: "256Mi"
cpu: "250m"
limits:
memory: "512Mi"
cpu: "500m"
volumeMounts:
- name: postgres-storage
mountPath: /var/lib/postgresql/data
volumes:
- name: postgres-storage
persistentVolumeClaim:
claimName: postgres-pvc
---
apiVersion: v1
kind: Service
metadata:
name: postgres
namespace: infrawhisper
spec:
selector:
app: postgres
ports:
- port: 5432
targetPort: 5432
Observe algumas coisas. O bloco resources define limites de memória e CPU — isso é o que impede um serviço de matar de fome os outros. O secretKeyRef obtém credenciais de um Secret do Kubernetes em vez de codificá-las no YAML. O PersistentVolumeClaim garante que os dados sobrevivam a reinícios de pods.
Criei manifestos similares para Redis, Kafka e ClickHouse. Depois fiz deploy de todos de uma vez:
kubectl apply -f ./deploy/k8s/
Este comando lê cada arquivo YAML no diretório e os aplica ao cluster. Em trinta segundos, a interface visual do OrbStack mostrava quatro pods subindo — vi o status passar de ContainerCreating para Running um por um.
Passo 3: Verificar que a infraestrutura está saudável antes de fazer deploy das apps.
kubectl get pods -n infrawhisper
A saída era algo assim:
NAME READY STATUS RESTARTS AGE
postgres-7d4f8b6c9-x2k1p 1/1 Running 0 45s
redis-5c8f9d7b2-m9n3q 1/1 Running 0 44s
kafka-6b2e8c4d1-k7p2r 1/1 Running 0 43s
clickhouse-8a1d3f5e6-j4w8t 1/1 Running 0 42s
Todos Running, todos 1/1 prontos. Se algum pod mostrasse CrashLoopBackOff — e acredite, vários mostraram durante minhas tentativas anteriores — eu usava:
kubectl describe pod postgres-7d4f8b6c9-x2k1p -n infrawhisper
kubectl logs -n infrawhisper deployment/postgres
O comando describe mostra eventos — falhas no pull da imagem, OOM kills, erros de montagem. O comando logs mostra o stdout do contêiner. Entre esses dois, diagnostiquei cada problema que encontrei.
Passo 4: Fazer deploy dos serviços de aplicação.
Com a infraestrutura rodando, fiz deploy dos cinco serviços de aplicação — API Server, AI Engine, Collector, Stream Processor e Dashboard. Mesmo padrão: manifestos de Deployment + Service, aplicados com kubectl apply.
O API Server precisava saber como alcançar Postgres e Redis. No Docker Compose, você usaria o nome do serviço do arquivo compose. No Kubernetes, você usa o nome do Service — que eu tinha configurado como postgres e redis. Então as strings de conexão ficaram assim:
DATABASE_URL=postgresql://user:pass@postgres:5432/infrawhisper
REDIS_URL=redis://redis:6379
KAFKA_BROKERS=kafka:9092
Mesmo conceito, orquestrador diferente. A abstração do Service significa que meu código de aplicação não se importava se estava rodando no Docker Compose ou Kubernetes. Ele simplesmente conectava em postgres:5432 de qualquer jeito.
Passo 5: Configurar Ingress para acesso externo.
Com todos os nove serviços rodando dentro do cluster, eu precisava de uma forma de alcançar o dashboard e o servidor API pelo meu navegador. É para isso que serve o Ingress:
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: infrawhisper-ingress
namespace: infrawhisper
spec:
rules:
- host: infrawhisper.local
http:
paths:
- path: /api
pathType: Prefix
backend:
service:
name: api-server
port:
number: 8080
- path: /
pathType: Prefix
backend:
service:
name: dashboard
port:
number: 3000
Depois de aplicar isso, infrawhisper.local/api roteava para o servidor API e infrawhisper.local carregava o dashboard. OrbStack lida com a resolução DNS para domínios .local automaticamente no Mac — sem necessidade de editar /etc/hosts.
Fiquei sentado olhando o dashboard carregando de um cluster Kubernetes rodando no meu notebook. Nove serviços. Todos saudáveis. Todos se comunicando. Tinha ido de "eu realmente não entendo Pods" para isso em três dias.
Se você prefere que alguém construa e faça deploy desse tipo de configuração de infraestrutura do zero, eu aceito projetos de DevOps e arquitetura cloud. Você pode ver o que já construí em fiverr.com/s/EgxYmWD.
Mas o deploy foi só o começo. O verdadeiro poder apareceu quando precisei atualizar, debugar e escalar serviços sem downtime.
O Fluxo de Trabalho Deploy-Update-Rollback Que Me Fez Confiar no Kubernetes
Aqui está o fluxo de trabalho que agora se repete constantemente toda vez que envio mudanças para qualquer serviço do InfraWhisper:
1. Escrever a mudança de código.
2. Construir uma nova imagem Docker com uma tag de versão:
docker build -t api-server:v2 .
3. Enviar para um registro de contêineres:
docker push ghcr.io/yourname/api-server:v2
4. Fazer deploy via Helm (ou atualizar a imagem diretamente):
Usando Helm — que gerencia todos os manifestos Kubernetes como um único pacote:
helm upgrade --install infrawhisper ./deploy/helm/infrawhisper -n infrawhisper
Ou atualizar apenas a imagem de um serviço:
kubectl set image deployment/api-server api-server=ghcr.io/yourname/api-server:v2 -n infrawhisper
5. Assistir o rollout acontecer em tempo real:
kubectl rollout status deployment/api-server -n infrawhisper
Este comando bloqueia até que os novos pods estejam rodando e os antigos tenham sido terminados. Você vê uma saída como:
Waiting for deployment "api-server" rollout to finish: 1 old replicas are pending termination...
deployment "api-server" successfully rolled out
6. Se algo quebrar — reverter instantaneamente:
kubectl rollout undo deployment/api-server -n infrawhisper
Um comando. A versão anterior está rodando de novo em segundos. Sem downtime. Sem pânico. Sem conectar por SSH num servidor e rodar git revert e rezar.
Você também pode consultar o histórico de rollout para ver todas as versões anteriores:
kubectl rollout history deployment/api-server -n infrawhisper
Esse fluxo de trabalho é o que me converteu. A rede de segurança do rollback instantâneo mudou como penso sobre deploys. Estou mais disposto a entregar atualizações pequenas e frequentes porque o custo de um deploy ruim caiu de "trinta minutos de pânico" para "rodar um comando."
Dito isso, encontrei bastantes problemas no caminho. Aqui está o que quebrou e como corrigi.
O Que Deu Errado (E os Comandos Que Me Salvaram)
Kubernetes tem reputação de ser complexo. Honestamente? A complexidade não está nos conceitos — está no debugging. Quando algo não funciona, as mensagens de erro podem ser crípticas, e saber qual comando rodar em qual situação requer prática.
Aqui estão os padrões de debugging que realmente usei, organizados por tipo de problema.
Quando pods não iniciam — verifique eventos primeiro, logs depois.
kubectl describe pod api-server-xxxx -n infrawhisper
A seção de Events no final da saída do describe te diz por que um pod não está iniciando. Os culpados comuns que encontrei:
ImagePullBackOff— a tag da imagem não existia no registro. Geralmente um erro de digitação na tag de versão.CrashLoopBackOff— o contêiner inicia mas cai imediatamente. Hora de verificar logs.Pendingsem eventos — geralmente um problema de recursos. O scheduler não consegue encontrar um nó com CPU ou memória suficiente.
Uma vez que eu sabia que o pod estava iniciando mas caindo, logs eram a próxima parada:
kubectl logs -n infrawhisper deployment/api-server
Para um crash que já aconteceu (o pod reiniciou e os logs são da nova instância):
kubectl logs -n infrawhisper deployment/api-server --previous
Essa flag --previous me salvou pelo menos duas vezes. Os logs da instância atual diziam "inicialização saudável." Os logs da instância anterior mostravam o segfault real. Sem --previous, eu estaria caçando fantasmas.
Quando você precisa assistir logs em tempo real:
kubectl logs -n infrawhisper deployment/api-server -f
A flag -f transmite logs ao vivo. Mantive isso rodando num terminal enquanto testava a conexão do processador de streams com o Kafka. Assistir o handshake de conexão ter sucesso em tempo real pareceu como assistir o lançamento de um foguete.
Quando você quer uma visão mais ampla de tudo no namespace:
kubectl get all -n infrawhisper
Isso mostra todos os deployments, services, pods e replica sets de uma vez. É meu comando "qual é o estado do mundo." Provavelmente rodei umas cem vezes em três dias.
Para um deployment específico com detalhes extras:
kubectl get deployment api-server -n infrawhisper -o wide
A flag -o wide mostra a imagem do contêiner e informações do nó — útil para confirmar que a versão certa realmente está rodando.
Quando você precisa assistir mudanças de status de pods ao vivo:
kubectl get pods -n infrawhisper -w
A flag -w monitora mudanças. Quando eu fazia deploy de uma atualização, rodava isso num terminal e kubectl rollout status em outro, assistindo pods antigos serem terminados e novos subirem.
Quando você precisa forçar o reinício de um serviço:
Às vezes um serviço entra num estado estranho. Em vez de deletar e recriar o deployment, um rollout restart reinicia os pods de forma elegante:
kubectl rollout restart deployment/api-server -n infrawhisper
Isso cria novos pods antes de terminar os antigos, então não há downtime. Se você precisa matar um pod específico (talvez ele esteja travado e você quer que Kubernetes o recrie):
kubectl delete pod api-server-xxxx -n infrawhisper
O controlador do Deployment imediatamente percebe o pod faltando e cria um substituto. Auto-reparação em ação.
Quando você precisa escalar sob carga:
kubectl scale deployment/api-server --replicas=3 -n infrawhisper
Três instâncias do servidor API, com balanceamento de carga automático pelo Service. Testei isso rodando um gerador de carga contra a API e vendo no OrbStack três pods compartilhando o tráfego uniformemente. Escalar para baixo é o mesmo comando com --replicas=1.
Cada um desses comandos se tornou memória muscular até o final do terceiro dia. No primeiro dia, eu pesquisava cada flag no Google. No terceiro dia, eu os encadeava sem pensar.
As Partes Honestas Que Ninguém Escreve
Aqui é onde me separo da típica narrativa "aprendi Kubernetes e foi mágico." Porque parte não foi mágico. Parte foi frustrante de maneiras que me fizeram questionar se o investimento valia a pena.
YAML é doloroso. Não tem como contornar. Manifestos Kubernetes são verbosos, sensíveis a indentação e fáceis de configurar errado silenciosamente. Passei quarenta e cinco minutos debugando um deployment que não criava pods porque eu tinha colocado containerPort no nível de aninhamento errado. Linters de YAML ajudam — comecei a rodar kubeval em cada manifesto antes de aplicar — mas a experiência de desenvolvedor ao escrever YAML para Kubernetes é o elo mais fraco de todo o ecossistema.
Helm ajuda mas adiciona sua própria complexidade. Charts Helm empacotam seus manifestos Kubernetes em templates reutilizáveis e parametrizáveis. Para o InfraWhisper, criei um chart Helm que me permitia fazer deploy de todo o stack com um comando:
helm upgrade --install infrawhisper ./deploy/helm/infrawhisper -n infrawhisper
Grande melhoria em relação a aplicar quinze arquivos YAML individualmente. Mas templates Helm usam sintaxe de Go templating, que é sua própria curva de aprendizado. Agora eu tinha três camadas para debugar: meu código de aplicação, meus manifestos Kubernetes, e meus templates Helm envolvendo esses manifestos. Em duas ocasiões, um erro de renderização num template Helm produziu YAML válido que configurava a coisa errada. Tempos divertidos.
Limites de recursos são um jogo de adivinhação no começo. Quanta memória um broker Kafka precisa? Quanta CPU o motor de IA deveria ter? Não fazia ideia. Minha primeira tentativa deu a cada serviço os mesmos limites — 256Mi de memória, 250m de CPU — e o motor de IA foi imediatamente OOM-killed porque inferência ML precisa de mais de 256 megabytes de RAM. Obviamente.
Acabei fazendo profiling de cada serviço no Docker primeiro, anotando o uso pico de memória e CPU, e definindo limites em aproximadamente 2x o pico com alguma margem. Não é científico, mas funcionou. Kubernetes te dá kubectl top pods -n infrawhisper para monitorar o uso real uma vez que as coisas estão rodando, e ajustei limites ao longo de alguns dias baseado em dados reais.
A curva de aprendizado é concentrada no início. O dia um foi brutal. O dia dois foi produtivo. O dia três foi rápido. Os conceitos não são inerentemente difíceis — são apenas desconhecidos. Uma vez que o modelo mental faz clique (e espero que o que apresentei antes ajude), os comandos se tornam extensões lógicas do que você está tentando fazer. "Quero três réplicas" mapeia diretamente para kubectl scale. "Quero ver logs" mapeia para kubectl logs. Os nomes dos comandos são os conceitos.
Se eu tivesse que fazer isso de novo, mudaria uma coisa: começaria com dois ou três serviços em vez de nove. Fazer deploy de tudo de uma vez significou que quando algo quebrava, a falha poderia estar em qualquer um dos nove lugares. Começar pequeno, verificar o fluxo de trabalho com um app simples e um banco de dados, depois adicionar serviços incrementalmente — essa é a abordagem que eu recomendaria.
Esta é também uma daquelas situações onde Kubernetes nem sempre é a resposta certa. Se sua aplicação é um único contêiner com um banco de dados, Docker Compose provavelmente é suficiente. A sobrecarga do Kubernetes só se paga quando você tem múltiplos serviços que precisam de escalamento independente, auto-reparação e deploys sem downtime. Para os nove serviços do InfraWhisper, esse limiar foi claramente atingido. Para um side project de dois contêineres, talvez não.
O Cheat Sheet de kubectl do InfraWhisper
Depois de três dias fazendo deploy, debugando, atualizando e ocasionalmente xingando arquivos YAML, estes são os comandos que uso constantemente. Mantenho essa lista fixada nas minhas notas de terminal.
Antes de fazer deploy — verifique que seu cluster está pronto:
kubectl cluster-info
kubectl get nodes
kubectl get all -n infrawhisper
Deploy e aplicar configurações:
kubectl apply -f deployment.yaml
kubectl apply -f ./deploy/k8s/
helm upgrade --install infrawhisper ./deploy/helm/infrawhisper -n infrawhisper
Atualizar a imagem de um serviço:
kubectl set image deployment/api-server api-server=ghcr.io/yourname/api-server:v2 -n infrawhisper
kubectl rollout status deployment/api-server -n infrawhisper
Verificar o que está rodando:
kubectl get pods -n infrawhisper
kubectl get pods -n infrawhisper -w
kubectl describe pod api-server-xxxx -n infrawhisper
kubectl get deployment api-server -n infrawhisper -o wide
Ler logs e debugar:
kubectl logs -n infrawhisper deployment/api-server
kubectl logs -n infrawhisper deployment/api-server -f
kubectl logs -n infrawhisper deployment/api-server --previous
Reverter quando as coisas dão errado:
kubectl rollout undo deployment/api-server -n infrawhisper
kubectl rollout history deployment/api-server -n infrawhisper
Escalar para cima ou para baixo:
kubectl scale deployment/api-server --replicas=3 -n infrawhisper
Reiniciar ou deletar:
kubectl rollout restart deployment/api-server -n infrawhisper
kubectl delete pod api-server-xxxx -n infrawhisper
O ciclo completo de build a deploy:
docker build -t api-server:v2 .
docker push ghcr.io/yourname/api-server:v2
helm upgrade infrawhisper ./deploy/helm/infrawhisper -n infrawhisper
kubectl get pods -n infrawhisper
kubectl logs -n infrawhisper deployment/api-server -f
kubectl rollout undo deployment/api-server -n infrawhisper # if needed
Imprima isso. Fixe. Você vai usar cada um desses na sua primeira semana.
O Que Isso Muda Daqui Pra Frente
Três dias atrás, a ideia de rodar nove serviços num cluster orquestrado parecia algo que exigia meses de treinamento em DevOps e uma equipe de engenheiros de infraestrutura.
Não exige. Exige um Mac, OrbStack, alguns arquivos YAML e a disposição de atravessar umas oito horas de confusão antes das coisas começarem a fazer sentido. As ferramentas ficaram boas o suficiente para que um engenheiro de software — não um especialista em DevOps, um engenheiro de software — possa ir do zero a um cluster local de nível produção num fim de semana longo.
O que levo comigo não é apenas uma configuração Kubernetes funcionando. É uma mudança mental. Penso sobre aplicações de forma diferente agora. Penso em serviços e pods e deployments. Penso sobre o que acontece quando as coisas falham, não apenas quando funcionam. Penso sobre escalar como um controle deslizante que posso ajustar, não como uma crise que preciso resolver com engenharia.
O deploy do InfraWhisper continua rodando no meu cluster local OrbStack enquanto escrevo isso. Nove pods, todos verdes, todos saudáveis. Kafka processando eventos, ClickHouse armazenando analytics, o dashboard renderizando dados em tempo real. E se algum deles cair agora — Kubernetes vai trazê-lo de volta antes de eu terminar esta frase.
Se você vem adiando Kubernetes como eu — tratando-o como conhecimento de infraestrutura destinado a outra pessoa — aqui está seu sinal. Instale OrbStack hoje à noite. Faça deploy de um serviço amanhã. Adicione um segundo no dia seguinte. No terceiro dia, você vai se perguntar por que esperou tanto.
Qual é aquele serviço no seu stack que vive caindo e ninguém reinicia? Comece por aí.
Perguntas Frequentes
Posso rodar Kubernetes localmente no Mac sem Docker Desktop?
Sim. OrbStack fornece um cluster Kubernetes completo no Mac sem Docker Desktop. Inclui tanto Docker quanto Kubernetes, usa significativamente menos memória (cerca de 1.5-2 GB versus 4-6 GB) e inicia em segundos. Instale de orbstack.dev e habilite Kubernetes nas configurações.
Quantos serviços OrbStack consegue rodar num cluster Kubernetes local?
OrbStack lida confortavelmente com 10 a 15 serviços num Mac com chip M e 16 GB de RAM. Rodei 9 serviços incluindo Postgres, Redis, Kafka e ClickHouse simultaneamente sem problemas de performance. Limites de recursos em cada deployment impedem que um único serviço consuma os recursos dos outros.
Qual é a diferença entre kubectl apply e helm upgrade?
kubectl apply -f faz deploy de arquivos de manifesto YAML individuais diretamente. helm upgrade --install faz deploy de um chart Helm — um pacote de manifestos parametrizados com valores configuráveis. Helm é melhor para aplicações multi-serviço complexas; kubectl direto funciona bem para deploys simples. Veja a seção de Implementação acima para ambas as abordagens.
Como debugar um pod preso em CrashLoopBackOff?
Execute kubectl describe pod [nome-pod] -n [namespace] para verificar Events e a razão do crash, depois kubectl logs -n [namespace] deployment/[nome] --previous para ver os logs da instância que caiu. A flag --previous é crítica — ela mostra a saída do último contêiner, não da tentativa de reinício atual.
Kubernetes é exagero para projetos pequenos?
Para um único contêiner com um banco de dados, sim — Docker Compose é mais simples e suficiente. Kubernetes se paga quando você roda 3+ serviços que precisam de escalamento independente, reinícios auto-reparáveis e deploys sem downtime. O ponto de equilíbrio é aproximadamente onde docker-compose começa a precisar de ferramentas externas para confiabilidade.
Let's Work Together
Looking to build AI systems, automate workflows, or scale your tech infrastructure? I'd love to help.
- Fiverr (custom builds & integrations): fiverr.com/s/EgxYmWD
- Portfolio: mejba.me
- Ramlit Limited (enterprise solutions): ramlit.com
- ColorPark (design & branding): colorpark.io
- xCyberSecurity (security services): xcybersecurity.io