Van nul naar 9 services op Kubernetes met OrbStack
Drie dagen geleden kon ik je niet eerlijk vertellen wat het verschil was tussen een Pod en een Deployment. Ik had misschien wel twaalf keer over Kubernetes gelezen, meegeknikt bij architectuurdiagrammen en stilletjes het tabblad gesloten telkens als een tutorial bij het kubectl apply-gedeelte kwam. Het voelde als infrastructuurkennis bedoeld voor iemand anders — platform-engineers, DevOps-specialisten, mensen die in YAML dromen.
Toen moest ik InfraWhisper uitleveren.
InfraWhisper is een monitoring- en analyseplatform dat ik aan het bouwen ben — dashboard, API-server, AI-engine, datacollector, streamprocessor, plus de databases en message brokers die het allemaal bij elkaar houden. Negen services in totaal. Ze draaien met docker-compose up werkte prima op mijn laptop. Maar het moment dat ik begon na te denken over productie — over wat er gebeurt als de API-server om 3 uur 's nachts crasht, over het opschalen van de streamprocessor tijdens verkeerspieken, over het deployen van updates zonder het dashboard neer te halen — begon Docker Compose te voelen als een fiets op de snelweg.
Dus ging ik aan de slag met Kubernetes. En OrbStack. En drie dagen van hardnekkig doorzettingsvermogen.
Wat er aan de andere kant uitkwam was een volledig georkestreerd lokaal cluster met alle negen InfraWhisper-services draaiend, zelfherstellend en bereikbaar via één enkel ingress-endpoint. Deze post is alles wat ik daarbij leerde — de mentale modellen die echt klikten, de commando's die ertoe doen, en de fouten die mij uren kostten zodat ze jou niet hetzelfde kosten.
Waarom ik stopte met Kubernetes als optioneel te beschouwen
Dit is wat mij uiteindelijk over de streep trok. Ik had InfraWhisper draaien in Docker Compose op een staging-server. Vijf services, vier databases, alles communicerend via een Docker-netwerk. Het werkte. Toen liep de Kafka-container uit geheugen en ging dood.
Niets herstartte hem. De streamprocessor, die afhankelijk is van Kafka, begon verbindingsfouten te gooien. De collector, die events naar Kafka pusht, begon stilletjes data te verliezen. Het dashboard laadde nog steeds — alles zag er prima uit — maar de volledige analysepipeline was dood. Ik merkte het pas na zes uur.
Met Docker alleen blijft een gecrashte container gecrashed. Je hebt externe tools nodig — systemd, supervisord, aangepaste health-check-scripts — om de betrouwbaarheid erop te schroeven die ingebouwd zou moeten zijn. Je stelt een Frankenstein samen van bash-scripts en bidt dat ze elke faalmodus dekken.
Kubernetes handelt dit native af. Een container gaat dood, Kubernetes herstart hem. Een node valt uit, Kubernetes herplant pods naar gezonde nodes. Je pusht een kapotte update, je voert één commando uit en je bent terug bij de vorige versie. Dit is geen theoretische veerkracht — het is hoe productie-infrastructuur daadwerkelijk werkt bij bedrijven met echte workloads.
De kloof tussen "Ik begrijp waarom Kubernetes belangrijk is" en "Ik kan daadwerkelijk deployen naar Kubernetes" voelde enorm van buitenaf. Dat was het niet. En OrbStack maakte die kloof nog kleiner.
Maar voordat ik in de setup duik, heb je het mentale model nodig. Want Kubernetes-commando's slaan nergens op totdat je de zes concepten begrijpt waarop ze opereren.
De zes Kubernetes-concepten die er echt toe doen
Ik heb Kubernetes-documentatie gelezen die veertig concepten introduceert in het eerste hoofdstuk. Dat is overweldigend en, eerlijk gezegd, contraproductief. Toen ik aan het leren was, deden slechts zes concepten ertoe om een echte applicatie te deployen. Al het andere is optimalisatie die je later kunt leren.
Container. Docker verpakt je applicatiecode, dependencies en runtime in één draagbare eenheid. Je bouwt het één keer, en het draait identiek op je laptop, een CI-server of een cloud-VM. Als je ooit Docker hebt gebruikt, ken je dit al. De container is het atoom.
Pod. Kubernetes draait containers niet direct. Het wikkelt ze in een Pod — de kleinste deploybare eenheid in K8s. Een Pod is meestal één container, soms twee als je een sidecar nodig hebt (zoals een log-forwarder die naast je app draait). Zie de Pod als een container met een postadres.
Deployment. Dit is waar Kubernetes zijn complexiteit begint te verdienen. Een Deployment definieert hoeveel kopieën (replica's) van een Pod er op elk moment moeten draaien. Als je zegt "Ik wil 3 replica's van de API-server" en er één crasht, merkt Kubernetes de lacune op en draait een vervanging op. Je declareert de gewenste toestand. Kubernetes zorgt dat de realiteit overeenkomt.
Service. Pods krijgen willekeurige IP-adressen die bij elke herstart veranderen. Een Service geeft je Pod een stabiele DNS-naam — zodat het dashboard de API-server kan bereiken op api-server:8080 in plaats van te jagen op welk IP de Pod dit keer heeft gekregen. Services zijn het interne telefoonboek van je cluster.
Ingress. Services handelen verkeer binnen het cluster af. Ingress handelt verkeer af dat van buiten komt — browserverzoeken, API-calls, webhooks. Het is de voordeur, die app.local/api routeert naar de API-serverservice en app.local/dashboard naar de dashboardservice.
Namespace. Een logische grens die gerelateerde resources groepeert. Alle negen InfraWhisper-services leven in de infrawhisper-namespace. Dit houdt ze geïsoleerd van systeemservices en alles wat er verder op het cluster draait. Het is ook waarom bijna elk kubectl-commando dat ik je laat zien eindigt met -n infrawhisper.
Dat is het. Container gaat in een Pod. Deployment beheert hoeveel Pods er draaien. Service geeft ze stabiele namen. Ingress routeert extern verkeer naar binnen. Namespace houdt alles georganiseerd.
Met dat mentale model geladen, beginnen de commando's intuïtief te worden. En over commando's gesproken — laat me je vertellen over de tool die het lokaal draaien van dit alles bijna moeiteloos liet voelen.
Waarom OrbStack mijn hele ervaring veranderde
Ik had eerder Docker Desktop geprobeerd. Het werkte, maar "werkte" doet zwaar werk in die zin. Het geheugengebruik was brutaal — 4 tot 6 GB gewoon idle. De Kubernetes-integratie voelde erop geschroefd, vaak achterlopend of zich anders gedragend dan echte clusters. Opstarten duurde lang genoeg dat ik Twitter opende tijdens het wachten, en zo verlies je twintig minuten voordat je één regel code schrijft.
OrbStack is anders op manieren die er echt toe doen voor het leren van Kubernetes.
Het is lichtgewicht. Opstarten duurt seconden, niet minuten. Geheugengebruik blijft redelijk — schommelend rond 1,5 tot 2 GB zelfs met een volledig Kubernetes-cluster draaiend. Op een M-serie Mac voelt het native aan op een manier die Docker Desktop nooit deed.
De Kubernetes-integratie is ingebouwd en werkt gewoon. Één toggle in de instellingen, en je hebt een single-node cluster lokaal draaien. Geen minikube. Geen kind. Geen VM-drivers configureren. OrbStack geeft je een echt Kubernetes-cluster ondersteund door containerd, toegankelijk via de standaard kubectl- en helm-commando's. Je kubeconfig wordt automatisch bijgewerkt.
Maar de functie die me de meeste tijd bespaarde — en dit verwachtte ik niet — is de visuele interface. OrbStack toont je draaiende containers, pods, resourcegebruik en logs in een schone GUI. Wanneer je Kubernetes leert en een pod steeds crash-loopt, is het kunnen zien wat er gebeurt over alle negen services tegelijk meer waard dan welke terminaloutput ook. Ik had het OrbStack-dashboard op het ene scherm en mijn terminal op het andere, kijkend hoe pods in real-time opkwamen terwijl ik configuraties toepaste.
Ik wil duidelijk zijn: OrbStack is geen speelgoed of een shortcut. Het cluster dat het draait, gedraagt zich als een echt Kubernetes-cluster. Alles wat ik lokaal leerde en deployede, was direct overdraagbaar toen ik later kubectl naar een remote cluster richtte. OrbStack verwijderde gewoon de frictie die me niets nuttigs leerde.
Het aan de praat krijgen kostte ongeveer vijf minuten. Installeer OrbStack van orbstack.dev, open het, schakel Kubernetes in bij instellingen, en verifieer met:
kubectl cluster-info
kubectl get nodes
Als beide commando's schone output geven, heb je een werkend cluster. Tijd om iets echts te deployen.
Hoe werkt Kubernetes-architectuur eigenlijk onder de motorkap?
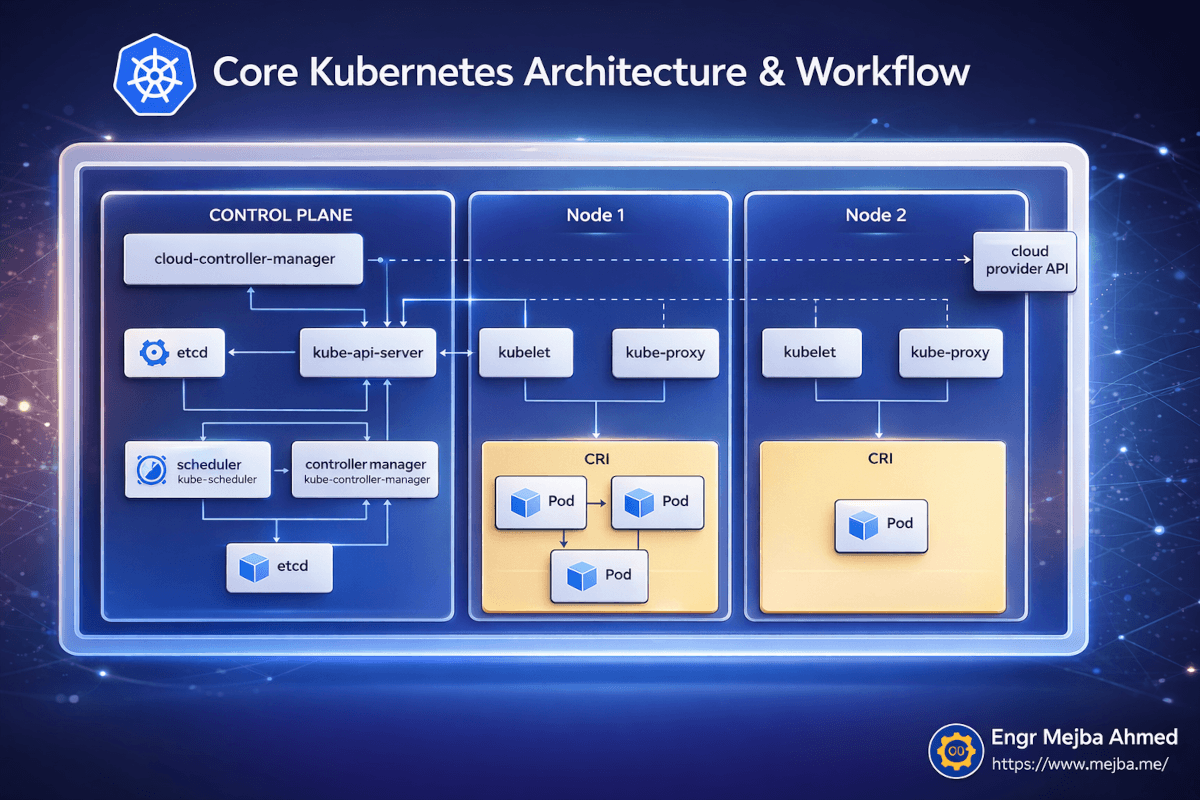
Voordat ik services begon te deployen, besteedde ik een uur aan het begrijpen van wat er daadwerkelijk op mijn machine draaide. Dit betaalde zich enorm uit toen dingen later kapotgingen, omdat ik kon redeneren over waar in het systeem het probleem zat.
Kubernetes volgt een control plane en worker node architectuur. Zelfs op een single-node lokaal cluster zoals OrbStack biedt, draaien beide rollen op dezelfde machine.
Het Control Plane is het brein. Het heeft vijf componenten die ertoe doen:
De kube-api-server is de voordeur naar alles. Elk kubectl-commando dat je uitvoert, praat met deze API-server. Het valideert je verzoeken, werkt de clusterstatus bij en vertelt nodes wat ze moeten doen. Wanneer ik kubectl apply -f deployment.yaml uitvoer, stuur ik die YAML naar de API-server, die de gewenste toestand opslaat en orkestreert om het werkelijkheid te maken.
etcd is de database die alle clusterstatus opslaat. Elke deployment, elke service, elke pod-status — het staat allemaal in etcd. Ik heb het nooit direct aangeraakt, maar weten dat het bestaat verklaart waarom Kubernetes van bijna alles kan herstellen. De gewenste toestand is altijd persistent opgeslagen.
De scheduler beslist welke node elke nieuwe pod moet draaien. Op een multi-node cluster is dit waar bin-packing en resource-optimalisatie plaatsvinden. Op mijn single-node OrbStack-setup gaat elke pod naar dezelfde node — maar de scheduler draait nog steeds, en het begrijpen ervan hielp toen ik later naar multi-node ging.
De controller manager draait de reconciliatie-loops die Kubernetes zelfherstellend maken. Het vergelijkt constant "wat zou er moeten draaien" (de gewenste toestand in etcd) met "wat draait er daadwerkelijk" (de huidige toestand van node-rapportages). Wanneer er een mismatch is, onderneemt het actie. Pod gecrashed? De controller manager merkt het op en vertelt de scheduler een vervanging te maken.
De cloud-controller-manager handelt integraties met cloudproviders af — load balancers, opslagvolumes, node-levenscyclus. Op een lokaal OrbStack-cluster is dit grotendeels slapend, maar het is goed om te weten dat het bestaat voor wanneer je naar AWS of GCP deployt.
Aan de Node-kant draaien drie dingen:
kubelet is de agent op elke node die instructies ontvangt van de API-server en pods op die node beheert. Het haalt containerimages op, start containers, rapporteert gezondheid terug naar het control plane.
kube-proxy handelt netwerkroutering binnen de node af, en zorgt dat verkeer gericht op een Service de juiste Pod bereikt.
CRI (Container Runtime Interface) is de daadwerkelijke containerruntime — containerd in het geval van OrbStack — die je containers draait.
Dit is waarom dit architectuuroverzicht niet alleen academisch is: toen mijn API-server-pod bleef crash-loopen, wist ik dat ik kubectl describe pod moest controleren (wat de API-server bevraagt voor pod-events) in plaats van alleen naar logs te staren. De describe-output vertelde me dat de container OOM-killed werd — een resource-limietprobleem, geen codeprobleem. Zonder het mentale model van hoe Kubernetes-componenten interageren, had ik uren verspild aan het debuggen van applicatiecode die eigenlijk prima was.
Nu — laat me je door het deployen van alle negen InfraWhisper-services leiden. Dit is waar theorie praktijk wordt.
InfraWhisper deployen: 9 services, één cluster, nul gebeden
De InfraWhisper-stack heeft negen services die in een specifieke volgorde moeten opstarten en betrouwbaar met elkaar moeten communiceren:
Infrastructuurlaag: Postgres (primaire database), Redis (caching en sessies), Kafka (event streaming), ClickHouse (analysedatabase)
Applicatielaag: API Server (REST-endpoints), AI Engine (ML-inferentie), Collector (event-ingestie), Stream Processor (real-time datapipeline), Dashboard (frontend-UI)
In Docker Compose zou ik alle negen in één bestand definiëren met depends_on-directieven en het beste hopen. In Kubernetes krijgt elke service zijn eigen Deployment- en Service-definitie, en de orkestratie wordt correct afgehandeld.
Stap 1: Maak de namespace aan.
Alles van InfraWhisper leeft in zijn eigen namespace. Dit is het eerste wat ik maakte:
kubectl create namespace infrawhisper
Eén commando, en nu heb ik een geïsoleerde ruimte voor de volledige applicatie. Elk commando vanaf hier gebruikt -n infrawhisper om deze namespace te targeten.
Stap 2: Deploy eerst de infrastructuurservices.
Databases en message brokers moeten draaien voordat de applicatieservices die ervan afhankelijk zijn. Ik schreef Kubernetes-manifesten (YAML-bestanden) voor elk — een Deployment die de containerimage en resourcelimieten definieert, en een Service die bepaalt hoe andere pods het kunnen bereiken.
Hier is een vereenvoudigd voorbeeld voor Postgres:
# deploy/k8s/postgres-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: postgres
namespace: infrawhisper
spec:
replicas: 1
selector:
matchLabels:
app: postgres
template:
metadata:
labels:
app: postgres
spec:
containers:
- name: postgres
image: postgres:16.2
ports:
- containerPort: 5432
env:
- name: POSTGRES_DB
value: "infrawhisper"
- name: POSTGRES_USER
valueFrom:
secretKeyRef:
name: db-credentials
key: username
- name: POSTGRES_PASSWORD
valueFrom:
secretKeyRef:
name: db-credentials
key: password
resources:
requests:
memory: "256Mi"
cpu: "250m"
limits:
memory: "512Mi"
cpu: "500m"
volumeMounts:
- name: postgres-storage
mountPath: /var/lib/postgresql/data
volumes:
- name: postgres-storage
persistentVolumeClaim:
claimName: postgres-pvc
---
apiVersion: v1
kind: Service
metadata:
name: postgres
namespace: infrawhisper
spec:
selector:
app: postgres
ports:
- port: 5432
targetPort: 5432
Let op een paar dingen. Het resources-blok stelt geheugen- en CPU-limieten in — dit voorkomt dat één service de andere uithongert. De secretKeyRef haalt credentials uit een Kubernetes Secret in plaats van ze hard te coderen in de YAML. De PersistentVolumeClaim zorgt dat data pod-herstarts overleeft.
Ik maakte vergelijkbare manifesten voor Redis, Kafka en ClickHouse. Daarna deployede ik ze allemaal tegelijk:
kubectl apply -f ./deploy/k8s/
Dit commando leest elk YAML-bestand in de map en past ze toe op het cluster. Binnen dertig seconden toonde OrbStack's visuele interface vier pods die opstartten — ik zag de status gaan van ContainerCreating naar Running één voor één.
Stap 3: Verifieer dat de infrastructuur gezond is voordat je apps deployt.
kubectl get pods -n infrawhisper
Output zag er ongeveer zo uit:
NAME READY STATUS RESTARTS AGE
postgres-7d4f8b6c9-x2k1p 1/1 Running 0 45s
redis-5c8f9d7b2-m9n3q 1/1 Running 0 44s
kafka-6b2e8c4d1-k7p2r 1/1 Running 0 43s
clickhouse-8a1d3f5e6-j4w8t 1/1 Running 0 42s
Allemaal Running, allemaal 1/1 gereed. Als een pod CrashLoopBackOff toonde — en geloof me, meerdere deden dat tijdens mijn eerdere pogingen — gebruikte ik:
kubectl describe pod postgres-7d4f8b6c9-x2k1p -n infrawhisper
kubectl logs -n infrawhisper deployment/postgres
Het describe-commando toont events — image pull-fouten, OOM kills, mount-fouten. Het logs-commando toont de stdout van de container. Tussen deze twee diagnosticeerde ik elk probleem dat ik tegenkwam.
Stap 4: Deploy de applicatieservices.
Met de infrastructuur draaiend, deployede ik de vijf applicatieservices — API Server, AI Engine, Collector, Stream Processor en Dashboard. Zelfde patroon: Deployment + Service manifesten, toegepast met kubectl apply.
De API Server moest weten hoe Postgres en Redis te bereiken. In Docker Compose zou je de servicenaam uit het compose-bestand gebruiken. In Kubernetes gebruik je de Service-naam — die ik had ingesteld op postgres en redis. Dus de verbindingsstrings zagen er zo uit:
DATABASE_URL=postgresql://user:pass@postgres:5432/infrawhisper
REDIS_URL=redis://redis:6379
KAFKA_BROKERS=kafka:9092
Zelfde concept, andere orkestrator. De Service-abstractie betekent dat mijn applicatiecode het niet uitmaakt of het in Docker Compose of Kubernetes draait. Het verbond gewoon met postgres:5432 in beide gevallen.
Stap 5: Stel Ingress in voor externe toegang.
Met alle negen services draaiend in het cluster, had ik een manier nodig om het dashboard en de API-server vanuit mijn browser te bereiken. Dat is Ingress:
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: infrawhisper-ingress
namespace: infrawhisper
spec:
rules:
- host: infrawhisper.local
http:
paths:
- path: /api
pathType: Prefix
backend:
service:
name: api-server
port:
number: 8080
- path: /
pathType: Prefix
backend:
service:
name: dashboard
port:
number: 3000
Na dit toe te passen, routeerde infrawhisper.local/api naar de API-server en infrawhisper.local laadde het dashboard. OrbStack handelt de DNS-resolutie voor .local-domeinen automatisch af op Mac — geen /etc/hosts-bewerking nodig.
Ik zat daar te staren naar het dashboard dat laadde vanuit een Kubernetes-cluster draaiend op mijn laptop. Negen services. Allemaal gezond. Allemaal met elkaar communicerend. Ik was gegaan van "Ik begrijp Pods niet echt" naar dit in drie dagen.
Als je liever wilt dat iemand dit soort infrastructuur-setup vanaf nul bouwt en deployt, neem ik DevOps- en cloud-architectuuropdrachten aan. Je kunt zien wat ik heb gebouwd op fiverr.com/s/EgxYmWD.
Maar de deploy was pas het begin. De echte kracht kwam tevoorschijn toen ik services moest updaten, debuggen en schalen zonder downtime.
De deploy-update-rollback workflow die me Kubernetes deed vertrouwen
Dit is de workflow die nu op repeat draait wanneer ik wijzigingen push naar een InfraWhisper-service:
1. Schrijf de codewijziging.
2. Bouw een nieuwe Docker-image met een versie-tag:
docker build -t api-server:v2 .
3. Push het naar een containerregistry:
docker push ghcr.io/yourname/api-server:v2
4. Deploy via Helm (of werk de image direct bij):
Met Helm — dat alle Kubernetes-manifesten beheert als één pakket:
helm upgrade --install infrawhisper ./deploy/helm/infrawhisper -n infrawhisper
Of werk alleen de image van één service bij:
kubectl set image deployment/api-server api-server=ghcr.io/yourname/api-server:v2 -n infrawhisper
5. Bekijk de rollout in real-time:
kubectl rollout status deployment/api-server -n infrawhisper
Dit commando blokkeert totdat de nieuwe pods draaien en de oude zijn beëindigd. Je ziet output als:
Waiting for deployment "api-server" rollout to finish: 1 old replicas are pending termination...
deployment "api-server" successfully rolled out
6. Als iets kapotgaat — rol direct terug:
kubectl rollout undo deployment/api-server -n infrawhisper
Eén commando. De vorige versie draait weer binnen seconden. Geen downtime. Geen paniek. Geen SSH'en naar een server en git revert draaien en bidden.
Je kunt zelfs de rollout-geschiedenis bekijken om alle vorige versies te zien:
kubectl rollout history deployment/api-server -n infrawhisper
Deze workflow heeft mij overtuigd. Het vangnet van directe rollback veranderde hoe ik over deployments denk. Ik ben meer bereid om kleine, frequente updates te versturen omdat de kosten van een slechte deploy daalde van "dertig minuten scramble" naar "voer één commando uit."
Dat gezegd hebbende, ik liep onderweg tegen genoeg problemen aan. Dit is wat er kapotging en hoe ik het oploste.
Wat er misging (en de commando's die me redden)
Kubernetes heeft een reputatie als complex. Eerlijk? De complexiteit zit niet in de concepten — het zit in het debuggen. Wanneer iets niet werkt, kunnen de foutmeldingen cryptisch zijn, en weten welk commando je moet uitvoeren in welke situatie vergt oefening.
Dit zijn de debug-patronen die ik daadwerkelijk gebruikte, georganiseerd per type probleem.
Wanneer pods niet willen starten — controleer eerst events, dan logs.
kubectl describe pod api-server-xxxx -n infrawhisper
De Events-sectie onderaan de describe-output vertelt je waarom een pod niet start. Veelvoorkomende boosdoeners die ik tegenkwam:
ImagePullBackOff— de image-tag bestond niet in het registry. Meestal een typfout in de versie-tag.CrashLoopBackOff— de container start maar crasht meteen. Tijd om logs te checken.Pendingzonder events — meestal een resource-probleem. De scheduler kan geen node vinden met genoeg CPU of geheugen.
Zodra ik wist dat de pod startte maar crashte, waren logs de volgende stap:
kubectl logs -n infrawhisper deployment/api-server
Voor een crash die al is gebeurd (de pod is herstart en de logs zijn van de nieuwe instantie):
kubectl logs -n infrawhisper deployment/api-server --previous
Die --previous-vlag redde me minstens twee keer. De logs van de huidige instantie zeiden "gezonde opstart." De logs van de vorige instantie toonden de werkelijke segfault. Zonder --previous had ik spoken achternagezeten.
Wanneer je logs in real-time moet bekijken:
kubectl logs -n infrawhisper deployment/api-server -f
De -f-vlag streamt logs live. Ik hield dit draaiend in een terminal terwijl ik de verbinding van de streamprocessor met Kafka testte. De verbindingshandshake in real-time zien slagen voelde als het kijken naar een raketlancering.
Wanneer je een breder overzicht wilt van alles in de namespace:
kubectl get all -n infrawhisper
Dit toont alle deployments, services, pods en replica sets in één keer. Het is mijn "wat is de stand van zaken"-commando. Ik heb het waarschijnlijk honderd keer gedraaid in drie dagen.
Voor een specifieke deployment met extra detail:
kubectl get deployment api-server -n infrawhisper -o wide
De -o wide-vlag toont de containerimage en node-informatie — handig om te bevestigen dat de juiste versie daadwerkelijk draait.
Wanneer je pod-statuswijzigingen live wilt volgen:
kubectl get pods -n infrawhisper -w
De -w-vlag kijkt naar wijzigingen. Wanneer ik een update deployede, draaide ik dit in de ene terminal en kubectl rollout status in de andere, kijkend hoe oude pods beëindigden en nieuwe opkwamen.
Wanneer je een service geforceerd moet herstarten:
Soms raakt een service in een vreemde toestand. In plaats van de deployment te verwijderen en opnieuw aan te maken, herstart een rollout restart de pods op een nette manier:
kubectl rollout restart deployment/api-server -n infrawhisper
Dit maakt nieuwe pods aan voordat de oude worden beëindigd, dus er is geen downtime. Als je een specifieke pod moet killen (misschien is hij vast en wil je dat Kubernetes hem opnieuw aanmaakt):
kubectl delete pod api-server-xxxx -n infrawhisper
De Deployment-controller merkt de ontbrekende pod meteen op en maakt een vervanging aan. Zelfherstel in actie.
Wanneer je moet opschalen onder belasting:
kubectl scale deployment/api-server --replicas=3 -n infrawhisper
Drie instanties van de API-server, automatisch load-balanced via de Service. Ik testte dit door een load-generator tegen de API te draaien en te kijken hoe OrbStack drie pods toonde die het verkeer gelijkmatig deelden. Terugschalen is hetzelfde commando met --replicas=1.
Elk van deze commando's werd spiergeheugen tegen het einde van dag drie. De eerste dag googelde ik elke vlag. Op de derde dag ketende ik ze zonder nadenken aan elkaar.
De eerlijke delen waar niemand over schrijft
Hier wijk ik af van het typische "Ik leerde Kubernetes en het was magisch"-verhaal. Want sommige delen waren niet magisch. Sommige waren frustrerend op manieren die me deden afvragen of dit de investering waard was.
YAML is pijnlijk. Daar is geen ontkomen aan. Kubernetes-manifesten zijn omslachtig, inspringinggevoelig en makkelijk stilletjes verkeerd te configureren. Ik besteedde vijfenveertig minuten aan het debuggen van een deployment die geen pods wilde aanmaken omdat ik containerPort op het verkeerde nestingniveau had gezet. YAML-linters helpen — ik begon kubeval te draaien op elk manifest voordat ik het toepaste — maar de ontwikkelaarservaring van Kubernetes YAML schrijven is de zwakste schakel in het hele ecosysteem.
Helm helpt maar voegt zijn eigen complexiteit toe. Helm-charts verpakken je Kubernetes-manifesten in herbruikbare, geparametriseerde templates. Voor InfraWhisper maakte ik een Helm-chart waarmee ik de volledige stack met één commando kon deployen:
helm upgrade --install infrawhisper ./deploy/helm/infrawhisper -n infrawhisper
Enorme verbetering ten opzichte van het individueel toepassen van vijftien YAML-bestanden. Maar Helm-templates gebruiken Go-templating syntax, wat zijn eigen leercurve is. Ik had nu drie lagen om te debuggen: mijn applicatiecode, mijn Kubernetes-manifesten en mijn Helm-templates die die manifesten wrappen. Bij twee gelegenheden produceerde een renderingfout in een Helm-template geldige YAML die het verkeerde configureerde. Leuke tijden.
Resource-limieten zijn in het begin een gokspel. Hoeveel geheugen heeft een Kafka-broker nodig? Hoeveel CPU moet de AI-engine krijgen? Ik had geen idee. Mijn eerste poging gaf elke service dezelfde limieten — 256Mi geheugen, 250m CPU — en de AI-engine werd meteen OOM-killed omdat ML-inferentie meer dan 256 megabyte RAM nodig heeft. Vanzelfsprekend.
Ik profileerde uiteindelijk elke service eerst in Docker, noteerde piek geheugen- en CPU-gebruik en stelde limieten in op ruwweg 2x piek met wat marge. Niet wetenschappelijk, maar het werkte. Kubernetes geeft je kubectl top pods -n infrawhisper om het werkelijke gebruik te monitoren zodra dingen draaien, en ik paste limieten aan over een paar dagen op basis van echte data.
De leercurve is front-loaded. Dag één was brutaal. Dag twee was productief. Dag drie was snel. De concepten zijn niet inherent moeilijk — ze zijn gewoon onbekend. Zodra het mentale model klikt (en ik hoop dat degene die ik eerder uiteenzette helpt), worden de commando's logische extensies van wat je probeert te doen. "Ik wil drie replica's" mapt direct op kubectl scale. "Ik wil logs zien" mapt op kubectl logs. De commandonamen zijn de concepten.
Als ik dit opnieuw zou moeten doen, zou ik één ding veranderen: ik zou beginnen met twee of drie services in plaats van negen. Alles tegelijk deployen betekende dat wanneer iets kapotging, de fout in elk van negen plekken kon zitten. Klein beginnen, de workflow verifiëren met een simpele app en een database, dan services incrementeel toevoegen — dat is de aanpak die ik zou aanbevelen.
Dit is ook een van die situaties waar Kubernetes niet altijd het juiste antwoord is. Als je applicatie één container met een database is, is Docker Compose waarschijnlijk prima. De overhead van Kubernetes betaalt zich alleen uit wanneer je meerdere services hebt die onafhankelijke schaling, zelfherstellende herstarts en zero-downtime deployments nodig hebben. Voor InfraWhisper's negen services was die drempel duidelijk bereikt. Voor een project met twee containers is dat misschien niet zo.
Het InfraWhisper kubectl-spiekbriefje
Na drie dagen deployen, debuggen, updaten en af en toe vloeken op YAML-bestanden, zijn dit de commando's waar ik constant naar grijp. Ik houd deze lijst vastgepind in mijn terminalnotities.
Voordat je deployt — verifieer dat je cluster klaar is:
kubectl cluster-info
kubectl get nodes
kubectl get all -n infrawhisper
Deploy en pas configuraties toe:
kubectl apply -f deployment.yaml
kubectl apply -f ./deploy/k8s/
helm upgrade --install infrawhisper ./deploy/helm/infrawhisper -n infrawhisper
Werk een service-image bij:
kubectl set image deployment/api-server api-server=ghcr.io/yourname/api-server:v2 -n infrawhisper
kubectl rollout status deployment/api-server -n infrawhisper
Controleer wat er draait:
kubectl get pods -n infrawhisper
kubectl get pods -n infrawhisper -w
kubectl describe pod api-server-xxxx -n infrawhisper
kubectl get deployment api-server -n infrawhisper -o wide
Lees logs en debug:
kubectl logs -n infrawhisper deployment/api-server
kubectl logs -n infrawhisper deployment/api-server -f
kubectl logs -n infrawhisper deployment/api-server --previous
Rollback wanneer dingen misgaan:
kubectl rollout undo deployment/api-server -n infrawhisper
kubectl rollout history deployment/api-server -n infrawhisper
Schaal op of af:
kubectl scale deployment/api-server --replicas=3 -n infrawhisper
Herstart of verwijder:
kubectl rollout restart deployment/api-server -n infrawhisper
kubectl delete pod api-server-xxxx -n infrawhisper
De volledige build-to-deploy cyclus:
docker build -t api-server:v2 .
docker push ghcr.io/yourname/api-server:v2
helm upgrade infrawhisper ./deploy/helm/infrawhisper -n infrawhisper
kubectl get pods -n infrawhisper
kubectl logs -n infrawhisper deployment/api-server -f
kubectl rollout undo deployment/api-server -n infrawhisper # if needed
Print dit. Pin het vast. Je zult elk van deze commando's gebruiken in je eerste week.
Wat dit verandert voor de toekomst
Drie dagen geleden voelde het idee om negen services in een georkestreerd cluster te draaien als iets dat maanden DevOps-training en een team van infrastructuur-engineers vereiste.
Dat is niet zo. Het vereist een Mac, OrbStack, wat YAML-bestanden en de bereidheid om door ongeveer acht uur verwarring te duwen voordat dingen beginnen te klikken. De tools zijn goed genoeg geworden dat een software-engineer — geen DevOps-specialist, een software-engineer — in een lang weekend van nul naar een productiewaardig lokaal cluster kan gaan.
Wat ik meeneem is niet alleen een werkende Kubernetes-setup. Het is een mentale verschuiving. Ik denk anders over applicaties nu. Ik denk in services en pods en deployments. Ik denk na over wat er gebeurt als dingen falen, niet alleen wanneer ze werken. Ik denk over schaling als een schuifregelaar die ik kan aanpassen, niet als een crisis waar ik me uit moet engineeren.
De InfraWhisper-deployment draait nog steeds op mijn lokale OrbStack-cluster terwijl ik dit schrijf. Negen pods, allemaal groen, allemaal gezond. Kafka verwerkt events, ClickHouse slaat analyses op, het dashboard rendert data in real-time. En als een van hen nu crasht — brengt Kubernetes ze terug voordat ik deze zin afmaak.
Als je Kubernetes hebt uitgesteld zoals ik deed — het behandelend als infrastructuurkennis bedoeld voor iemand anders — hier is je teken. Installeer vanavond OrbStack. Deploy morgen één service. Voeg de dag erna een tweede toe. Op dag drie vraag je je af waarom je zo lang hebt gewacht.
Wat is de ene service in je stack die steeds crasht en niemand herstart? Begin daar.
Veelgestelde vragen
Kan ik Kubernetes lokaal draaien op Mac zonder Docker Desktop?
Ja. OrbStack biedt een volledig Kubernetes-cluster op Mac zonder Docker Desktop. Het bevat zowel Docker als Kubernetes, gebruikt aanzienlijk minder geheugen (rond 1,5-2 GB versus 4-6 GB) en start in seconden. Installeer vanaf orbstack.dev en schakel Kubernetes in bij instellingen.
Hoeveel services kan OrbStack aan op een lokaal Kubernetes-cluster?
OrbStack verwerkt comfortabel 10-15 services op een M-serie Mac met 16 GB RAM. Ik draaide 9 services waaronder Postgres, Redis, Kafka en ClickHouse tegelijkertijd zonder prestatieproblemen. Resourcelimieten op elke deployment voorkomen dat één service de andere uithongert.
Wat is het verschil tussen kubectl apply en helm upgrade?
kubectl apply -f deployt individuele YAML-manifestbestanden direct. helm upgrade --install deployt een Helm-chart — een pakket van getemplated manifesten met configureerbare waarden. Helm is beter voor complexe multi-service applicaties; rauwe kubectl werkt prima voor eenvoudige deployments. Zie de implementatiesectie hierboven voor beide benaderingen.
Hoe debug ik een pod die vastzit in CrashLoopBackOff?
Draai kubectl describe pod [pod-naam] -n [namespace] om Events te controleren voor de crashreden, daarna kubectl logs -n [namespace] deployment/[naam] --previous om logs van de gecrashte instantie te bekijken. De --previous-vlag is cruciaal — het toont de output van de laatste container, niet de huidige herstartpoging.
Is Kubernetes overkill voor kleine projecten?
Voor één container met een database, ja — Docker Compose is eenvoudiger en voldoende. Kubernetes betaalt zich uit wanneer je 3+ services draait die onafhankelijke schaling, zelfherstellende herstarts en zero-downtime deployments nodig hebben. Het break-evenpunt is ruwweg waar docker-compose externe tools nodig begint te hebben voor betrouwbaarheid.
Let's Work Together
Looking to build AI systems, automate workflows, or scale your tech infrastructure? I'd love to help.
- Fiverr (custom builds & integrations): fiverr.com/s/EgxYmWD
- Portfolio: mejba.me
- Ramlit Limited (enterprise solutions): ramlit.com
- ColorPark (design & branding): colorpark.io
- xCyberSecurity (security services): xcybersecurity.io