De Cero a 9 Servicios en Kubernetes Con OrbStack
Hace tres días, no podía decirte la diferencia entre un Pod y un Deployment. No honestamente. Había leído sobre Kubernetes quizás una docena de veces, asentido frente a diagramas de arquitectura, y cerrado discretamente la pestaña cada vez que un tutorial llegaba a la sección de kubectl apply. Se sentía como conocimiento de infraestructura destinado a otra persona — ingenieros de plataforma, especialistas en DevOps, personas que sueñan en YAML.
Luego necesité desplegar InfraWhisper.
InfraWhisper es una plataforma de monitoreo y analíticas que he estado construyendo — dashboard, servidor API, motor de IA, recolector de datos, procesador de streams, más las bases de datos y message brokers que sostienen todo. Nueve servicios en total. Ejecutarlos con docker-compose up funcionaba bien en mi portátil. Pero en el momento en que empecé a pensar en producción — en qué pasa cuando el servidor API se cae a las 3 AM, en escalar el procesador de streams durante picos de tráfico, en desplegar actualizaciones sin tumbar el dashboard — Docker Compose empezó a sentirse como una bicicleta en una autopista.
Así que me senté con Kubernetes. Y OrbStack. Y tres días de persistencia obstinada.
Lo que salió del otro lado fue un cluster local completamente orquestado con los nueve servicios de InfraWhisper ejecutándose, auto-reparándose y accesibles a través de un único punto de entrada ingress. Este post es todo lo que aprendí haciéndolo — los modelos mentales que realmente hicieron clic, los comandos que importan y los errores que me costaron horas para que no te cuesten lo mismo a ti.
Por Qué Dejé de Tratar a Kubernetes Como Opcional
Esto es lo que finalmente me hizo dar el paso. Tenía InfraWhisper ejecutándose en Docker Compose en un servidor de staging. Cinco servicios, cuatro bases de datos, todo comunicándose a través de una red Docker. Funcionaba. Luego el contenedor de Kafka se quedó sin memoria y murió.
Nada lo reinició. El procesador de streams, que depende de Kafka, empezó a lanzar errores de conexión. El recolector, que envía eventos a Kafka, comenzó a descartar datos silenciosamente. El dashboard seguía cargando — todo parecía bien — pero todo el pipeline de analíticas estaba muerto. No me di cuenta durante seis horas.
Con Docker solo, un contenedor que se cae permanece caído. Necesitas herramientas externas — systemd, supervisord, scripts de health check personalizados — para añadirle la fiabilidad que debería venir incorporada. Estás ensamblando un Frankenstein de scripts bash y rezando para que cubran cada modo de fallo.
Kubernetes maneja esto de forma nativa. Un contenedor muere, Kubernetes lo reinicia. Un nodo se cae, Kubernetes reprograma pods en nodos saludables. Lanzas una actualización defectuosa, ejecutas un comando y vuelves a la versión anterior. Esto no es resiliencia teórica — así es como funciona realmente la infraestructura de producción en empresas con cargas de trabajo reales.
La brecha entre "entiendo por qué Kubernetes importa" y "realmente puedo desplegar en Kubernetes" parecía enorme desde afuera. No lo era. Y OrbStack hizo esa brecha aún más pequeña.
Pero antes de entrar en la configuración, necesitas el modelo mental. Porque los comandos de Kubernetes no tienen ningún sentido hasta que entiendes los seis conceptos sobre los que operan.
Los Seis Conceptos de Kubernetes Que Realmente Importan
He leído documentación de Kubernetes que introduce cuarenta conceptos en el primer capítulo. Es abrumador y, honestamente, contraproducente. Cuando estaba aprendiendo, solo seis conceptos importaron para desplegar una aplicación real. Todo lo demás es optimización que puedes aprender después.
Container. Docker empaqueta tu código de aplicación, dependencias y runtime en una sola unidad portable. Lo construyes una vez y se ejecuta de forma idéntica en tu portátil, un servidor CI o una VM en la nube. Si alguna vez has usado Docker, ya conoces este. El contenedor es el átomo.
Pod. Kubernetes no ejecuta contenedores directamente. Los envuelve en un Pod — la unidad desplegable más pequeña en K8s. Un Pod usualmente es un contenedor, a veces dos si necesitas un sidecar (como un reenviador de logs ejecutándose junto a tu app). Piensa en el Pod como un contenedor con una dirección postal.
Deployment. Aquí es donde Kubernetes empieza a justificar su complejidad. Un Deployment define cuántas copias (réplicas) de un Pod deberían estar ejecutándose en todo momento. Si dices "quiero 3 réplicas del servidor API" y una se cae, Kubernetes nota la brecha y levanta un reemplazo automáticamente. Declaras el estado deseado. Kubernetes hace que la realidad coincida.
Service. Los Pods obtienen direcciones IP aleatorias que cambian cada vez que se reinician. Un Service le da a tu Pod un nombre DNS estable — para que el dashboard pueda alcanzar el servidor API en api-server:8080 en lugar de buscar la IP que le tocó al Pod esta vez. Los Services son la guía telefónica interna de tu cluster.
Ingress. Los Services manejan tráfico dentro del cluster. Ingress maneja tráfico que viene desde afuera — peticiones del navegador, llamadas API, webhooks. Es la puerta de entrada, enrutando app.local/api al servicio del servidor API y app.local/dashboard al servicio del dashboard.
Namespace. Un límite lógico que agrupa recursos relacionados. Los nueve servicios de InfraWhisper viven en el namespace infrawhisper. Esto los mantiene aislados de los servicios del sistema y cualquier otra cosa ejecutándose en el cluster. También es por eso que casi todos los comandos kubectl que te mostraré terminan con -n infrawhisper.
Eso es todo. El contenedor va dentro de un Pod. El Deployment gestiona cuántos Pods se ejecutan. El Service les da nombres estables. El Ingress enruta el tráfico externo. El Namespace mantiene todo organizado.
Con ese modelo mental cargado, los comandos empiezan a tener sentido intuitivo. Y hablando de comandos — déjame contarte sobre la herramienta que hizo que ejecutar todo esto localmente se sintiera casi sin esfuerzo.
Por Qué OrbStack Cambió Toda Mi Experiencia
Ya había probado Docker Desktop antes. Funcionaba, pero "funcionaba" está haciendo mucho trabajo en esa frase. El uso de memoria era brutal — 4 a 6 GB solo estando inactivo. La integración de Kubernetes se sentía añadida a la fuerza, a menudo quedándose atrás o comportándose diferente a los clusters reales. Arrancar tomaba suficiente tiempo como para abrir Twitter mientras esperaba, que es como pierdes veinte minutos antes de escribir una sola línea de código.
OrbStack es diferente en formas que genuinamente importan para aprender Kubernetes.
Es ligero. Arrancar toma segundos, no minutos. El uso de memoria se mantiene razonable — rondando 1.5 a 2 GB incluso con un cluster Kubernetes completo ejecutándose. En un Mac con chip M, se siente nativo de una manera que Docker Desktop nunca logró.
La integración de Kubernetes viene incorporada y simplemente funciona. Un toggle en los ajustes, y tienes un cluster de un solo nodo ejecutándose localmente. Sin minikube. Sin kind. Sin configurar drivers de VM. OrbStack te da un cluster Kubernetes real respaldado por containerd, accesible a través de los comandos estándar kubectl y helm. Tu kubeconfig se actualiza automáticamente.
Pero la funcionalidad que me ahorró más tiempo — y no lo esperaba — es la interfaz visual. OrbStack te muestra tus contenedores en ejecución, pods, uso de recursos y logs en una GUI limpia. Cuando estás aprendiendo Kubernetes y un pod sigue en crash-loop, poder ver qué está pasando en los nueve servicios simultáneamente vale más que cualquier salida de terminal. Tenía el dashboard de OrbStack en un monitor y mi terminal en el otro, viendo pods levantarse en tiempo real mientras aplicaba configuraciones.
Quiero ser claro: OrbStack no es un juguete ni un atajo. El cluster que ejecuta se comporta como un cluster Kubernetes real. Todo lo que aprendí y desplegué localmente se transfirió directamente cuando luego apunté kubectl a un cluster remoto. OrbStack simplemente eliminó la fricción que no me estaba enseñando nada útil.
Ponerlo en marcha tomó unos cinco minutos. Instala OrbStack desde orbstack.dev, ábrelo, habilita Kubernetes en ajustes, y verifica con:
kubectl cluster-info
kubectl get nodes
Si ambos comandos devuelven una salida limpia, tienes un cluster funcionando. Es hora de desplegar algo real.
¿Cómo Funciona Realmente la Arquitectura de Kubernetes Bajo el Capó?
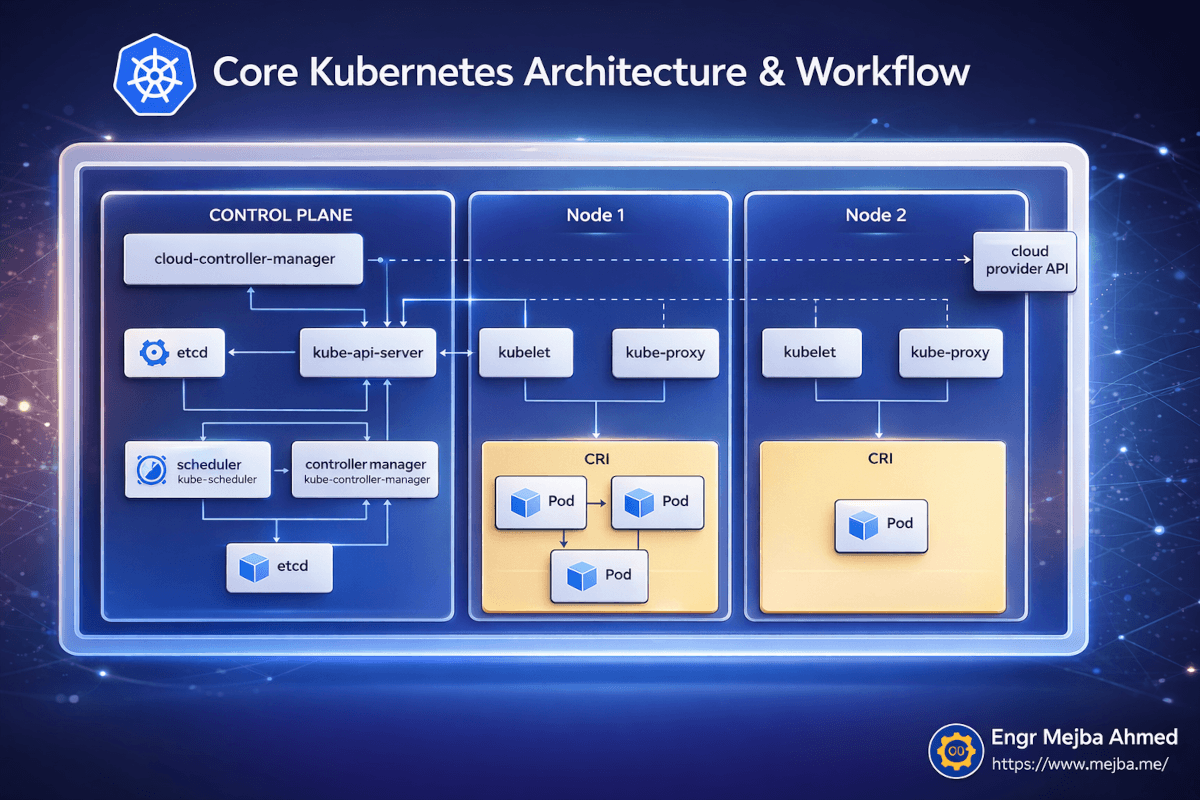
Antes de empezar a desplegar servicios, pasé una hora entendiendo qué estaba realmente ejecutándose en mi máquina. Esto se pagó enormemente cuando las cosas se rompieron después, porque podía razonar sobre dónde en el sistema estaba el problema.
Kubernetes sigue una arquitectura de plano de control y nodos worker. Incluso en un cluster local de un solo nodo como el que proporciona OrbStack, ambos roles se ejecutan en la misma máquina.
El Plano de Control es el cerebro. Tiene cinco componentes que importan:
El kube-api-server es la puerta de entrada a todo. Cada comando kubectl que ejecutas habla con este servidor API. Valida tus peticiones, actualiza el estado del cluster y le dice a los nodos qué hacer. Cuando ejecuto kubectl apply -f deployment.yaml, estoy enviando ese YAML al servidor API, que almacena el estado deseado y orquesta su materialización.
etcd es la base de datos que almacena todo el estado del cluster. Cada deployment, cada service, cada estado de pod — todo está en etcd. Nunca lo toqué directamente, pero saber que existe explica por qué Kubernetes puede recuperarse de casi cualquier cosa. El estado deseado siempre está persistido.
El scheduler decide qué nodo debe ejecutar cada nuevo pod. En un cluster multi-nodo, aquí es donde ocurre el bin-packing y la optimización de recursos. En mi configuración OrbStack de un solo nodo, cada pod va al mismo nodo — pero el scheduler sigue ejecutándose, y entenderlo ayudó cuando me mudé a multi-nodo después.
El controller manager ejecuta los bucles de reconciliación que hacen a Kubernetes auto-reparable. Constantemente compara "qué debería estar ejecutándose" (el estado deseado en etcd) contra "qué está realmente ejecutándose" (el estado actual de los reportes de nodos). Cuando hay un desajuste, toma acción. ¿Un pod se cayó? El controller manager lo nota y le dice al scheduler que cree un reemplazo.
El cloud-controller-manager maneja integraciones con proveedores de nube — balanceadores de carga, volúmenes de almacenamiento, ciclo de vida de nodos. En un cluster local de OrbStack, esto está mayormente inactivo, pero es bueno saber que existe para cuando despliegues en AWS o GCP.
En el lado del Nodo, tres cosas se ejecutan:
kubelet es el agente en cada nodo que recibe instrucciones del servidor API y gestiona pods en ese nodo. Descarga imágenes de contenedores, inicia contenedores, reporta salud al plano de control.
kube-proxy maneja el enrutamiento de red dentro del nodo, asegurándose de que el tráfico dirigido a un Service llegue al Pod correcto.
CRI (Container Runtime Interface) es el runtime de contenedores real — containerd en el caso de OrbStack — que ejecuta tus contenedores.
Aquí está por qué esta visión general de la arquitectura no es solo académica: cuando mi pod del servidor API seguía en crash-loop, sabía que debía verificar kubectl describe pod (que consulta al servidor API por eventos del pod) en lugar de solo mirar logs. La salida de describe me dijo que el contenedor estaba siendo OOM-killed — un problema de límites de recursos, no un problema de código. Sin el modelo mental de cómo interactúan los componentes de Kubernetes, habría perdido horas depurando código de aplicación que en realidad estaba bien.
Ahora — déjame guiarte a través del despliegue de los nueve servicios de InfraWhisper. Aquí es donde la teoría se convierte en práctica.
Desplegando InfraWhisper: 9 Servicios, Un Cluster, Cero Plegarias
El stack de InfraWhisper tiene nueve servicios que necesitan levantarse en un orden específico y comunicarse entre sí de forma confiable:
Capa de infraestructura: Postgres (base de datos principal), Redis (caché y sesiones), Kafka (streaming de eventos), ClickHouse (base de datos analítica)
Capa de aplicación: API Server (endpoints REST), AI Engine (inferencia ML), Collector (ingesta de eventos), Stream Processor (pipeline de datos en tiempo real), Dashboard (UI frontend)
En Docker Compose, definiría los nueve en un archivo con directivas depends_on y cruzaría los dedos. En Kubernetes, cada servicio obtiene su propio Deployment y definición de Service, y la orquestación se maneja correctamente.
Paso 1: Crear el namespace.
Todo lo de InfraWhisper vive en su propio namespace. Esto fue lo primero que creé:
kubectl create namespace infrawhisper
Un comando, y ahora tengo un espacio aislado para toda la aplicación. Cada comando de aquí en adelante usa -n infrawhisper para apuntar a este namespace.
Paso 2: Desplegar los servicios de infraestructura primero.
Las bases de datos y message brokers necesitan estar ejecutándose antes de los servicios de aplicación que dependen de ellos. Escribí manifiestos Kubernetes (archivos YAML) para cada uno — un Deployment definiendo la imagen del contenedor y límites de recursos, y un Service definiendo cómo otros pods pueden alcanzarlo.
Aquí hay un ejemplo simplificado para Postgres:
# deploy/k8s/postgres-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: postgres
namespace: infrawhisper
spec:
replicas: 1
selector:
matchLabels:
app: postgres
template:
metadata:
labels:
app: postgres
spec:
containers:
- name: postgres
image: postgres:16.2
ports:
- containerPort: 5432
env:
- name: POSTGRES_DB
value: "infrawhisper"
- name: POSTGRES_USER
valueFrom:
secretKeyRef:
name: db-credentials
key: username
- name: POSTGRES_PASSWORD
valueFrom:
secretKeyRef:
name: db-credentials
key: password
resources:
requests:
memory: "256Mi"
cpu: "250m"
limits:
memory: "512Mi"
cpu: "500m"
volumeMounts:
- name: postgres-storage
mountPath: /var/lib/postgresql/data
volumes:
- name: postgres-storage
persistentVolumeClaim:
claimName: postgres-pvc
---
apiVersion: v1
kind: Service
metadata:
name: postgres
namespace: infrawhisper
spec:
selector:
app: postgres
ports:
- port: 5432
targetPort: 5432
Observa algunas cosas. El bloque resources establece límites de memoria y CPU — esto es lo que evita que un servicio muera de hambre a los demás. El secretKeyRef obtiene credenciales de un Secret de Kubernetes en lugar de codificarlas en el YAML. El PersistentVolumeClaim asegura que los datos sobrevivan a reinicios de pods.
Creé manifiestos similares para Redis, Kafka y ClickHouse. Luego los desplegué todos de una vez:
kubectl apply -f ./deploy/k8s/
Este comando lee cada archivo YAML en el directorio y los aplica al cluster. En treinta segundos, la interfaz visual de OrbStack mostraba cuatro pods levantándose — vi el estado pasar de ContainerCreating a Running uno por uno.
Paso 3: Verificar que la infraestructura está saludable antes de desplegar las apps.
kubectl get pods -n infrawhisper
La salida se veía algo así:
NAME READY STATUS RESTARTS AGE
postgres-7d4f8b6c9-x2k1p 1/1 Running 0 45s
redis-5c8f9d7b2-m9n3q 1/1 Running 0 44s
kafka-6b2e8c4d1-k7p2r 1/1 Running 0 43s
clickhouse-8a1d3f5e6-j4w8t 1/1 Running 0 42s
Todos Running, todos 1/1 listos. Si algún pod mostraba CrashLoopBackOff — y créeme, varios lo hicieron durante mis intentos anteriores — usaba:
kubectl describe pod postgres-7d4f8b6c9-x2k1p -n infrawhisper
kubectl logs -n infrawhisper deployment/postgres
El comando describe muestra eventos — fallos al descargar imagen, OOM kills, errores de montaje. El comando logs muestra el stdout del contenedor. Entre estos dos, diagnostiqué cada problema que encontré.
Paso 4: Desplegar los servicios de aplicación.
Con la infraestructura ejecutándose, desplegué los cinco servicios de aplicación — API Server, AI Engine, Collector, Stream Processor y Dashboard. Mismo patrón: manifiestos de Deployment + Service, aplicados con kubectl apply.
El API Server necesitaba saber cómo alcanzar Postgres y Redis. En Docker Compose, usarías el nombre del servicio del archivo compose. En Kubernetes, usas el nombre del Service — que yo había configurado como postgres y redis. Así que las cadenas de conexión se veían así:
DATABASE_URL=postgresql://user:pass@postgres:5432/infrawhisper
REDIS_URL=redis://redis:6379
KAFKA_BROKERS=kafka:9092
Mismo concepto, diferente orquestador. La abstracción del Service significa que a mi código de aplicación no le importaba si estaba ejecutándose en Docker Compose o Kubernetes. Simplemente se conectaba a postgres:5432 de cualquier manera.
Paso 5: Configurar Ingress para acceso externo.
Con los nueve servicios ejecutándose dentro del cluster, necesitaba una forma de acceder al dashboard y al servidor API desde mi navegador. Para eso está el Ingress:
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: infrawhisper-ingress
namespace: infrawhisper
spec:
rules:
- host: infrawhisper.local
http:
paths:
- path: /api
pathType: Prefix
backend:
service:
name: api-server
port:
number: 8080
- path: /
pathType: Prefix
backend:
service:
name: dashboard
port:
number: 3000
Después de aplicar esto, infrawhisper.local/api enrutaba al servidor API e infrawhisper.local cargaba el dashboard. OrbStack maneja la resolución DNS para dominios .local automáticamente en Mac — no se necesita editar /etc/hosts.
Me quedé sentado mirando el dashboard cargándose desde un cluster Kubernetes ejecutándose en mi portátil. Nueve servicios. Todos saludables. Todos comunicándose entre sí. Había pasado de "realmente no entiendo los Pods" a esto en tres días.
Si prefieres que alguien construya y despliegue este tipo de configuración de infraestructura desde cero, acepto proyectos de DevOps y arquitectura cloud. Puedes ver lo que he construido en fiverr.com/s/EgxYmWD.
Pero el despliegue fue solo el comienzo. El verdadero poder apareció cuando necesité actualizar, depurar y escalar servicios sin tiempo de inactividad.
El Flujo de Trabajo Deploy-Update-Rollback Que Me Hizo Confiar en Kubernetes
Este es el flujo de trabajo que ahora se repite constantemente cada vez que envío cambios a cualquier servicio de InfraWhisper:
1. Escribir el cambio de código.
2. Construir una nueva imagen Docker con una etiqueta de versión:
docker build -t api-server:v2 .
3. Subirla a un registro de contenedores:
docker push ghcr.io/yourname/api-server:v2
4. Desplegar vía Helm (o actualizar la imagen directamente):
Usando Helm — que gestiona todos los manifiestos Kubernetes como un solo paquete:
helm upgrade --install infrawhisper ./deploy/helm/infrawhisper -n infrawhisper
O actualizar solo la imagen de un servicio:
kubectl set image deployment/api-server api-server=ghcr.io/yourname/api-server:v2 -n infrawhisper
5. Ver el rollout suceder en tiempo real:
kubectl rollout status deployment/api-server -n infrawhisper
Este comando bloquea hasta que los nuevos pods estén ejecutándose y los antiguos estén terminados. Ves una salida como:
Waiting for deployment "api-server" rollout to finish: 1 old replicas are pending termination...
deployment "api-server" successfully rolled out
6. Si algo se rompe — revertir instantáneamente:
kubectl rollout undo deployment/api-server -n infrawhisper
Un comando. La versión anterior está ejecutándose de nuevo en segundos. Sin tiempo de inactividad. Sin pánico. Sin conectarte por SSH a un servidor y ejecutar git revert y rezar.
También puedes consultar el historial de rollout para ver todas las versiones anteriores:
kubectl rollout history deployment/api-server -n infrawhisper
Este flujo de trabajo es lo que me convenció. La red de seguridad del rollback instantáneo cambió cómo pienso sobre los despliegues. Estoy más dispuesto a lanzar actualizaciones pequeñas y frecuentes porque el costo de un deploy fallido bajó de "treinta minutos de pánico" a "ejecutar un comando."
Dicho esto, encontré bastantes problemas en el camino. Esto es lo que se rompió y cómo lo arreglé.
Lo Que Salió Mal (Y los Comandos Que Me Salvaron)
Kubernetes tiene reputación de ser complejo. Honestamente, la complejidad no está en los conceptos — está en la depuración. Cuando algo no funciona, los mensajes de error pueden ser crípticos, y saber qué comando ejecutar en qué situación requiere práctica.
Aquí están los patrones de depuración que realmente usé, organizados por tipo de problema.
Cuando los pods no arrancan — revisa eventos primero, logs después.
kubectl describe pod api-server-xxxx -n infrawhisper
La sección de Events al final de la salida de describe te dice por qué un pod no está arrancando. Los culpables comunes que encontré:
ImagePullBackOff— la etiqueta de imagen no existía en el registro. Usualmente un error tipográfico en la etiqueta de versión.CrashLoopBackOff— el contenedor arranca pero se cae inmediatamente. Hora de revisar logs.Pendingsin eventos — usualmente un problema de recursos. El scheduler no puede encontrar un nodo con suficiente CPU o memoria.
Una vez que sabía que el pod estaba arrancando pero cayéndose, los logs eran la siguiente parada:
kubectl logs -n infrawhisper deployment/api-server
Para un crash que ya ocurrió (el pod se reinició y los logs son de la nueva instancia):
kubectl logs -n infrawhisper deployment/api-server --previous
Ese flag --previous me salvó al menos dos veces. Los logs de la instancia actual decían "arranque saludable." Los logs de la instancia anterior mostraban el segfault real. Sin --previous, habría estado persiguiendo fantasmas.
Cuando necesitas ver logs en tiempo real:
kubectl logs -n infrawhisper deployment/api-server -f
El flag -f transmite los logs en vivo. Mantuve esto ejecutándose en una terminal mientras probaba la conexión del procesador de streams con Kafka. Ver el handshake de conexión tener éxito en tiempo real se sintió como ver el lanzamiento de un cohete.
Cuando quieres una vista más amplia de todo en el namespace:
kubectl get all -n infrawhisper
Esto muestra todos los deployments, services, pods y replica sets de una vez. Es mi comando de "cuál es el estado del mundo." Probablemente lo ejecuté cien veces en tres días.
Para un deployment específico con detalle extra:
kubectl get deployment api-server -n infrawhisper -o wide
El flag -o wide muestra la imagen del contenedor e información del nodo — útil para confirmar que la versión correcta realmente está ejecutándose.
Cuando necesitas ver cambios de estado de pods en vivo:
kubectl get pods -n infrawhisper -w
El flag -w vigila cambios. Cuando desplegaba una actualización, ejecutaba esto en una terminal y kubectl rollout status en otra, viendo pods antiguos terminar y nuevos levantarse.
Cuando necesitas forzar el reinicio de un servicio:
A veces un servicio entra en un estado extraño. En lugar de eliminar y recrear el deployment, un rollout restart reinicia los pods de forma elegante:
kubectl rollout restart deployment/api-server -n infrawhisper
Esto crea nuevos pods antes de terminar los antiguos, así que no hay tiempo de inactividad. Si necesitas matar un pod específico (quizás está atascado y quieres que Kubernetes lo recree):
kubectl delete pod api-server-xxxx -n infrawhisper
El controlador del Deployment inmediatamente nota el pod faltante y crea un reemplazo. Auto-reparación en acción.
Cuando necesitas escalar bajo carga:
kubectl scale deployment/api-server --replicas=3 -n infrawhisper
Tres instancias del servidor API, con balanceo de carga automático a través del Service. Probé esto ejecutando un generador de carga contra la API y viendo en OrbStack cómo tres pods compartían el tráfico de manera uniforme. Escalar hacia abajo es el mismo comando con --replicas=1.
Cada uno de estos comandos se convirtió en memoria muscular para el final del tercer día. El primer día, buscaba en Google cada flag. Para el tercer día, los encadenaba sin pensar.
Las Partes Honestas Que Nadie Escribe
Aquí es donde me separo de la típica narrativa de "aprendí Kubernetes y fue mágico." Porque parte no fue mágico. Parte fue frustrante de maneras que me hicieron cuestionar si la inversión valía la pena.
YAML es doloroso. No hay forma de evitarlo. Los manifiestos de Kubernetes son verbosos, sensibles a la indentación y fáciles de configurar mal silenciosamente. Pasé cuarenta y cinco minutos depurando un deployment que no creaba pods porque había puesto containerPort en el nivel de anidamiento equivocado. Los linters de YAML ayudan — empecé a ejecutar kubeval en cada manifiesto antes de aplicar — pero la experiencia de desarrollador al escribir YAML para Kubernetes es el eslabón más débil de todo el ecosistema.
Helm ayuda pero añade su propia complejidad. Los charts de Helm empaquetan tus manifiestos Kubernetes en plantillas reutilizables y parametrizables. Para InfraWhisper, creé un chart de Helm que me permitía desplegar todo el stack con un comando:
helm upgrade --install infrawhisper ./deploy/helm/infrawhisper -n infrawhisper
Gran mejora respecto a aplicar quince archivos YAML individualmente. Pero las plantillas Helm usan sintaxis de Go templating, que es su propia curva de aprendizaje. Ahora tenía tres capas para depurar: mi código de aplicación, mis manifiestos Kubernetes, y mis plantillas Helm envolviendo esos manifiestos. En dos ocasiones, un error de renderizado en una plantilla Helm produjo YAML válido que configuraba lo incorrecto. Tiempos divertidos.
Los límites de recursos son un juego de adivinanzas al principio. ¿Cuánta memoria necesita un broker de Kafka? ¿Cuánta CPU debería tener el motor de IA? No tenía idea. Mi primer intento le dio a cada servicio los mismos límites — 256Mi de memoria, 250m de CPU — y el motor de IA inmediatamente fue OOM-killed porque la inferencia ML necesita más de 256 megabytes de RAM. Obviamente.
Terminé perfilando cada servicio en Docker primero, anotando el uso pico de memoria y CPU, y estableciendo límites en aproximadamente 2x el pico con algo de margen. No es científico, pero funcionó. Kubernetes te da kubectl top pods -n infrawhisper para monitorear el uso real una vez que las cosas están ejecutándose, y ajusté los límites durante un par de días basándome en datos reales.
La curva de aprendizaje está cargada al frente. El día uno fue brutal. El día dos fue productivo. El día tres fue rápido. Los conceptos no son inherentemente difíciles — simplemente son desconocidos. Una vez que el modelo mental hace clic (y espero que el que presenté antes ayude), los comandos se convierten en extensiones lógicas de lo que estás intentando hacer. "Quiero tres réplicas" se mapea directamente a kubectl scale. "Quiero ver logs" se mapea a kubectl logs. Los nombres de los comandos son los conceptos.
Si tuviera que hacer esto de nuevo, cambiaría una cosa: empezaría con dos o tres servicios en lugar de nueve. Desplegar todo a la vez significó que cuando algo se rompía, el fallo podía estar en cualquiera de nueve lugares. Empezar pequeño, verificar el flujo de trabajo con una app simple y una base de datos, luego agregar servicios incrementalmente — ese es el enfoque que recomendaría.
Esta es también una de esas situaciones donde Kubernetes no siempre es la respuesta correcta. Si tu aplicación es un solo contenedor con una base de datos, Docker Compose probablemente es suficiente. La sobrecarga de Kubernetes solo se justifica cuando tienes múltiples servicios que necesitan escalado independiente, auto-reparación y despliegues sin tiempo de inactividad. Para los nueve servicios de InfraWhisper, ese umbral claramente se cumplía. Para un side project de dos contenedores, quizás no.
El Cheat Sheet de kubectl para InfraWhisper
Después de tres días de desplegar, depurar, actualizar y ocasionalmente maldecir archivos YAML, estos son los comandos a los que recurro constantemente. Mantengo esta lista fijada en mis notas de terminal.
Antes de desplegar — verifica que tu cluster está listo:
kubectl cluster-info
kubectl get nodes
kubectl get all -n infrawhisper
Desplegar y aplicar configuraciones:
kubectl apply -f deployment.yaml
kubectl apply -f ./deploy/k8s/
helm upgrade --install infrawhisper ./deploy/helm/infrawhisper -n infrawhisper
Actualizar la imagen de un servicio:
kubectl set image deployment/api-server api-server=ghcr.io/yourname/api-server:v2 -n infrawhisper
kubectl rollout status deployment/api-server -n infrawhisper
Verificar qué está ejecutándose:
kubectl get pods -n infrawhisper
kubectl get pods -n infrawhisper -w
kubectl describe pod api-server-xxxx -n infrawhisper
kubectl get deployment api-server -n infrawhisper -o wide
Leer logs y depurar:
kubectl logs -n infrawhisper deployment/api-server
kubectl logs -n infrawhisper deployment/api-server -f
kubectl logs -n infrawhisper deployment/api-server --previous
Revertir cuando las cosas salen mal:
kubectl rollout undo deployment/api-server -n infrawhisper
kubectl rollout history deployment/api-server -n infrawhisper
Escalar hacia arriba o abajo:
kubectl scale deployment/api-server --replicas=3 -n infrawhisper
Reiniciar o eliminar:
kubectl rollout restart deployment/api-server -n infrawhisper
kubectl delete pod api-server-xxxx -n infrawhisper
El ciclo completo de build a deploy:
docker build -t api-server:v2 .
docker push ghcr.io/yourname/api-server:v2
helm upgrade infrawhisper ./deploy/helm/infrawhisper -n infrawhisper
kubectl get pods -n infrawhisper
kubectl logs -n infrawhisper deployment/api-server -f
kubectl rollout undo deployment/api-server -n infrawhisper # if needed
Imprímelo. Fíjalo. Usarás cada uno de estos durante tu primera semana.
Lo Que Esto Cambia de Aquí en Adelante
Hace tres días, la idea de ejecutar nueve servicios en un cluster orquestado se sentía como algo que requería meses de capacitación en DevOps y un equipo de ingenieros de infraestructura.
No es así. Requiere un Mac, OrbStack, algunos archivos YAML, y la voluntad de atravesar unas ocho horas de confusión antes de que las cosas empiecen a hacer clic. Las herramientas se han vuelto suficientemente buenas para que un ingeniero de software — no un especialista en DevOps, un ingeniero de software — pueda pasar de cero a un cluster local de grado producción en un fin de semana largo.
Lo que me llevo no es solo una configuración de Kubernetes funcionando. Es un cambio mental. Pienso en las aplicaciones de forma diferente ahora. Pienso en servicios y pods y deployments. Pienso en qué pasa cuando las cosas fallan, no solo cuando funcionan. Pienso en escalar como un control deslizante que puedo ajustar, no como una crisis que tengo que solucionar con ingeniería.
El despliegue de InfraWhisper sigue ejecutándose en mi cluster local de OrbStack mientras escribo esto. Nueve pods, todos verdes, todos saludables. Kafka procesando eventos, ClickHouse almacenando analíticas, el dashboard renderizando datos en tiempo real. Y si alguno de ellos se cae ahora mismo — Kubernetes lo levantará antes de que termine esta frase.
Si has estado posponiendo Kubernetes como yo — tratándolo como conocimiento de infraestructura destinado a otra persona — aquí está tu señal. Instala OrbStack esta noche. Despliega un servicio mañana. Añade un segundo al día siguiente. Para el tercer día, te preguntarás por qué esperaste tanto.
¿Cuál es ese servicio en tu stack que se cae constantemente y nadie lo reinicia? Empieza por ahí.
Preguntas Frecuentes
¿Puedo ejecutar Kubernetes localmente en Mac sin Docker Desktop?
Sí. OrbStack proporciona un cluster Kubernetes completo en Mac sin Docker Desktop. Incluye tanto Docker como Kubernetes, usa significativamente menos memoria (alrededor de 1.5-2 GB versus 4-6 GB), y arranca en segundos. Instálalo desde orbstack.dev y habilita Kubernetes en los ajustes.
¿Cuántos servicios puede manejar OrbStack en un cluster Kubernetes local?
OrbStack maneja cómodamente de 10 a 15 servicios en un Mac con chip M y 16 GB de RAM. Ejecuté 9 servicios incluyendo Postgres, Redis, Kafka y ClickHouse simultáneamente sin problemas de rendimiento. Los límites de recursos en cada deployment evitan que un solo servicio acapare los recursos de los demás.
¿Cuál es la diferencia entre kubectl apply y helm upgrade?
kubectl apply -f despliega archivos de manifiesto YAML individuales directamente. helm upgrade --install despliega un chart de Helm — un paquete de manifiestos parametrizados con valores configurables. Helm es mejor para aplicaciones multi-servicio complejas; kubectl directo funciona bien para despliegues simples. Consulta la sección de Implementación arriba para ambos enfoques.
¿Cómo depuro un pod atascado en CrashLoopBackOff?
Ejecuta kubectl describe pod [nombre-pod] -n [namespace] para verificar Events y la razón del crash, luego kubectl logs -n [namespace] deployment/[nombre] --previous para ver los logs de la instancia que se cayó. El flag --previous es crítico — muestra la salida del último contenedor, no el intento de reinicio actual.
¿Es Kubernetes excesivo para proyectos pequeños?
Para un solo contenedor con una base de datos, sí — Docker Compose es más simple y suficiente. Kubernetes se justifica cuando ejecutas 3+ servicios que necesitan escalado independiente, reinicios auto-reparables y despliegues sin tiempo de inactividad. El punto de equilibrio es aproximadamente donde docker-compose empieza a necesitar herramientas externas para la fiabilidad.
Let's Work Together
Looking to build AI systems, automate workflows, or scale your tech infrastructure? I'd love to help.
- Fiverr (custom builds & integrations): fiverr.com/s/EgxYmWD
- Portfolio: mejba.me
- Ramlit Limited (enterprise solutions): ramlit.com
- ColorPark (design & branding): colorpark.io
- xCyberSecurity (security services): xcybersecurity.io