De Zéro à 9 Services sur Kubernetes Avec OrbStack
Il y a trois jours, je n'aurais pas pu vous expliquer la différence entre un Pod et un Deployment. Pas honnêtement. J'avais lu sur Kubernetes une bonne douzaine de fois, hoché la tête devant des diagrammes d'architecture, et discrètement fermé l'onglet chaque fois qu'un tutoriel arrivait à la section kubectl apply. Ça ressemblait à du savoir d'infrastructure réservé à d'autres — des ingénieurs plateforme, des spécialistes DevOps, des gens qui rêvent en YAML.
Puis j'ai eu besoin de déployer InfraWhisper.
InfraWhisper est une plateforme de monitoring et d'analytics que je construis — dashboard, serveur API, moteur IA, collecteur de données, processeur de streams, plus les bases de données et les message brokers qui maintiennent le tout. Neuf services au total. Les lancer avec docker-compose up fonctionnait bien sur mon portable. Mais dès que j'ai commencé à penser à la production — à ce qui se passe quand le serveur API plante à 3h du matin, à la montée en charge du processeur de streams pendant les pics de trafic, au déploiement de mises à jour sans faire tomber le dashboard — Docker Compose a commencé à ressembler à un vélo sur une autoroute.
Alors je me suis assis avec Kubernetes. Et OrbStack. Et trois jours d'obstination tenace.
Ce qui en est sorti de l'autre côté était un cluster local entièrement orchestré avec les neuf services InfraWhisper en fonctionnement, en auto-réparation et accessibles via un seul point d'entrée ingress. Ce post est tout ce que j'ai appris en le faisant — les modèles mentaux qui ont vraiment fait tilt, les commandes qui comptent, et les erreurs qui m'ont coûté des heures pour qu'elles ne vous coûtent pas autant.
Pourquoi J'ai Arrêté de Traiter Kubernetes Comme Optionnel
Voici ce qui m'a finalement fait sauter le pas. J'avais InfraWhisper qui tournait en Docker Compose sur un serveur de staging. Cinq services, quatre bases de données, tout communiquant à travers un réseau Docker. Ça marchait. Puis le conteneur Kafka est tombé à court de mémoire et a planté.
Rien ne l'a redémarré. Le processeur de streams, qui dépend de Kafka, a commencé à lancer des erreurs de connexion. Le collecteur, qui pousse des événements dans Kafka, a commencé à perdre des données silencieusement. Le dashboard chargeait toujours — tout semblait bien — mais le pipeline d'analytics entier était mort. Je ne m'en suis pas rendu compte pendant six heures.
Avec Docker seul, un conteneur planté reste planté. Vous avez besoin d'outils externes — systemd, supervisord, des scripts de health check personnalisés — pour y boulonner la fiabilité qui devrait être intégrée. Vous assemblez un Frankenstein de scripts bash en priant pour qu'ils couvrent chaque mode de défaillance.
Kubernetes gère ça nativement. Un conteneur meurt, Kubernetes le redémarre. Un nœud tombe, Kubernetes replanifie les pods sur des nœuds sains. Vous poussez une mise à jour défectueuse, vous lancez une commande et vous revenez à la version précédente. Ce n'est pas de la résilience théorique — c'est comme ça que l'infrastructure de production fonctionne réellement dans les entreprises avec de vraies charges de travail.
L'écart entre "je comprends pourquoi Kubernetes est important" et "je sais réellement déployer sur Kubernetes" semblait énorme vu de l'extérieur. Il ne l'était pas. Et OrbStack a rendu cet écart encore plus petit.
Mais avant d'entrer dans la configuration, vous avez besoin du modèle mental. Parce que les commandes Kubernetes n'ont aucun sens tant que vous ne comprenez pas les six concepts sur lesquels elles opèrent.
Les Six Concepts Kubernetes Qui Comptent Vraiment
J'ai lu de la documentation Kubernetes qui introduit quarante concepts dans le premier chapitre. C'est accablant et, honnêtement, contre-productif. Quand j'apprenais, seuls six concepts comptaient pour déployer une vraie application. Tout le reste est de l'optimisation que vous pouvez apprendre plus tard.
Container. Docker empaquète votre code applicatif, ses dépendances et son runtime dans une seule unité portable. Vous le construisez une fois, et il tourne de manière identique sur votre portable, un serveur CI ou une VM cloud. Si vous avez déjà utilisé Docker, vous connaissez déjà celui-ci. Le conteneur est l'atome.
Pod. Kubernetes n'exécute pas les conteneurs directement. Il les enveloppe dans un Pod — la plus petite unité déployable en K8s. Un Pod est généralement un conteneur, parfois deux si vous avez besoin d'un sidecar (comme un forwarder de logs qui tourne à côté de votre app). Pensez au Pod comme un conteneur avec une adresse postale.
Deployment. C'est là que Kubernetes commence à justifier sa complexité. Un Deployment définit combien de copies (réplicas) d'un Pod doivent tourner à tout moment. Si vous dites "je veux 3 réplicas du serveur API" et qu'une plante, Kubernetes remarque le manque et lance un remplacement automatiquement. Vous déclarez l'état souhaité. Kubernetes aligne la réalité.
Service. Les Pods reçoivent des adresses IP aléatoires qui changent à chaque redémarrage. Un Service donne à votre Pod un nom DNS stable — pour que le dashboard puisse atteindre le serveur API à api-server:8080 au lieu de chercher quelle IP le Pod a reçue cette fois. Les Services sont l'annuaire interne de votre cluster.
Ingress. Les Services gèrent le trafic à l'intérieur du cluster. L'Ingress gère le trafic venant de l'extérieur — requêtes du navigateur, appels API, webhooks. C'est la porte d'entrée, routant app.local/api vers le service du serveur API et app.local/dashboard vers le service du dashboard.
Namespace. Une frontière logique qui regroupe les ressources liées. Les neuf services InfraWhisper vivent dans le namespace infrawhisper. Ça les garde isolés des services système et de tout ce qui tourne sur le cluster. C'est aussi pourquoi presque chaque commande kubectl que je vous montrerai se termine par -n infrawhisper.
C'est tout. Le conteneur va dans un Pod. Le Deployment gère combien de Pods tournent. Le Service leur donne des noms stables. L'Ingress route le trafic externe. Le Namespace garde tout organisé.
Avec ce modèle mental chargé, les commandes commencent à faire sens intuitivement. Et en parlant de commandes — laissez-moi vous parler de l'outil qui a rendu l'exécution de tout ça en local presque sans effort.
Pourquoi OrbStack a Changé Toute Mon Expérience
J'avais essayé Docker Desktop avant. Ça marchait, mais "marchait" fait beaucoup de travail dans cette phrase. L'utilisation mémoire était brutale — 4 à 6 Go juste au repos. L'intégration Kubernetes semblait boulonnée, souvent en retard ou se comportant différemment des vrais clusters. Le démarrage prenait assez de temps pour que j'ouvre Twitter en attendant, ce qui est comme ça qu'on perd vingt minutes avant d'écrire une seule ligne de code.
OrbStack est différent de manières qui comptent vraiment pour apprendre Kubernetes.
Il est léger. Le démarrage prend des secondes, pas des minutes. L'utilisation mémoire reste raisonnable — autour de 1.5 à 2 Go même avec un cluster Kubernetes complet qui tourne. Sur un Mac série M, ça semble natif d'une manière que Docker Desktop n'a jamais atteinte.
L'intégration Kubernetes est intégrée et fonctionne tout simplement. Un toggle dans les paramètres, et vous avez un cluster à nœud unique qui tourne en local. Pas de minikube. Pas de kind. Pas de configuration de drivers VM. OrbStack vous donne un vrai cluster Kubernetes soutenu par containerd, accessible via les commandes standard kubectl et helm. Votre kubeconfig est mis à jour automatiquement.
Mais la fonctionnalité qui m'a fait gagner le plus de temps — et je ne m'y attendais pas — c'est l'interface visuelle. OrbStack vous montre vos conteneurs en cours d'exécution, pods, utilisation des ressources et logs dans une GUI propre. Quand vous apprenez Kubernetes et qu'un pod boucle en crash, pouvoir voir ce qui se passe sur les neuf services simultanément vaut plus que n'importe quelle sortie terminal. J'avais le dashboard OrbStack sur un écran et mon terminal sur l'autre, regardant les pods monter en temps réel pendant que j'appliquais des configurations.
Je veux être clair : OrbStack n'est pas un jouet ni un raccourci. Le cluster qu'il fait tourner se comporte comme un vrai cluster Kubernetes. Tout ce que j'ai appris et déployé en local s'est transféré directement quand j'ai ensuite pointé kubectl vers un cluster distant. OrbStack a simplement supprimé la friction qui ne m'apprenait rien d'utile.
Le mettre en route a pris environ cinq minutes. Installez OrbStack depuis orbstack.dev, ouvrez-le, activez Kubernetes dans les paramètres, et vérifiez avec :
kubectl cluster-info
kubectl get nodes
Si les deux commandes renvoient une sortie propre, vous avez un cluster fonctionnel. C'est l'heure de déployer quelque chose de réel.
Comment l'Architecture Kubernetes Fonctionne-t-elle Réellement Sous le Capot ?
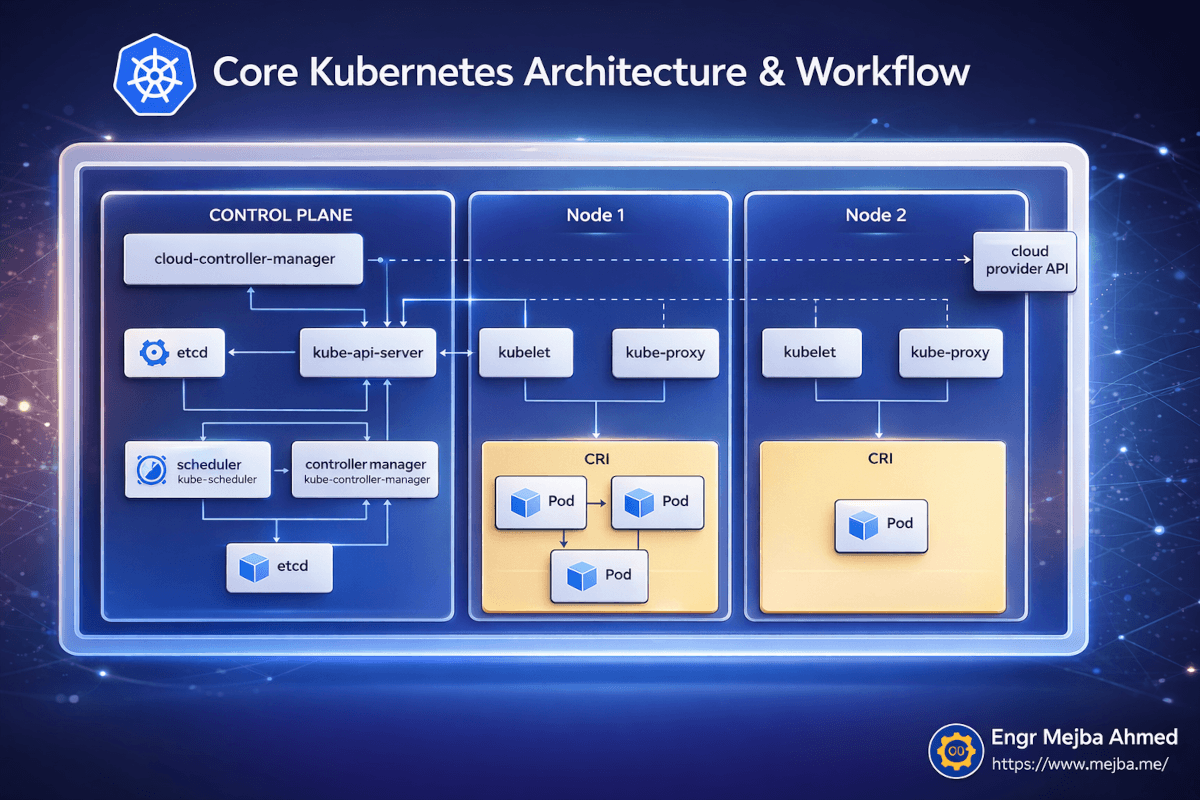
Avant de commencer à déployer des services, j'ai passé une heure à comprendre ce qui tournait réellement sur ma machine. Ça m'a énormément servi quand les choses ont cassé plus tard, parce que je pouvais raisonner sur où dans le système le problème se trouvait.
Kubernetes suit une architecture de plan de contrôle et de nœuds worker. Même sur un cluster local à nœud unique comme celui fourni par OrbStack, les deux rôles tournent sur la même machine.
Le Plan de Contrôle est le cerveau. Il a cinq composants qui comptent :
Le kube-api-server est la porte d'entrée de tout. Chaque commande kubectl que vous lancez parle à ce serveur API. Il valide vos requêtes, met à jour l'état du cluster et dit aux nœuds quoi faire. Quand je lance kubectl apply -f deployment.yaml, j'envoie ce YAML au serveur API, qui stocke l'état souhaité et orchestre sa réalisation.
etcd est la base de données qui stocke tout l'état du cluster. Chaque deployment, chaque service, chaque statut de pod — tout est dans etcd. Je ne l'ai jamais touché directement, mais savoir qu'il existe explique pourquoi Kubernetes peut se remettre de presque tout. L'état souhaité est toujours persisté.
Le scheduler décide quel nœud doit exécuter chaque nouveau pod. Sur un cluster multi-nœuds, c'est là que se passent le bin-packing et l'optimisation des ressources. Sur ma config OrbStack à nœud unique, chaque pod va sur le même nœud — mais le scheduler tourne quand même, et le comprendre m'a aidé quand j'ai migré vers du multi-nœuds après.
Le controller manager exécute les boucles de réconciliation qui rendent Kubernetes auto-réparant. Il compare constamment "ce qui devrait tourner" (l'état souhaité dans etcd) contre "ce qui tourne réellement" (l'état actuel d'après les rapports des nœuds). Quand il y a un décalage, il agit. Un pod a planté ? Le controller manager le remarque et dit au scheduler de créer un remplacement.
Le cloud-controller-manager gère les intégrations avec les fournisseurs cloud — load balancers, volumes de stockage, cycle de vie des nœuds. Sur un cluster local OrbStack, il est quasiment inactif, mais c'est bien de savoir qu'il existe pour quand vous déploierez sur AWS ou GCP.
Côté Nœud, trois choses tournent :
kubelet est l'agent sur chaque nœud qui reçoit les instructions du serveur API et gère les pods sur ce nœud. Il tire les images de conteneurs, démarre les conteneurs, rapporte la santé au plan de contrôle.
kube-proxy gère le routage réseau au sein du nœud, s'assurant que le trafic dirigé vers un Service atteint le bon Pod.
CRI (Container Runtime Interface) est le runtime de conteneurs réel — containerd dans le cas d'OrbStack — qui exécute vos conteneurs.
Voici pourquoi cette vue d'ensemble architecturale n'est pas juste académique : quand mon pod du serveur API bouclait en crash, je savais vérifier kubectl describe pod (qui interroge le serveur API pour les événements du pod) plutôt que de juste fixer les logs. La sortie du describe m'a dit que le conteneur se faisait OOM-kill — un problème de limite de ressources, pas un problème de code. Sans le modèle mental de comment les composants Kubernetes interagissent, j'aurais perdu des heures à déboguer du code applicatif qui allait très bien.
Maintenant — laissez-moi vous guider à travers le déploiement des neuf services InfraWhisper. C'est là que la théorie devient pratique.
Déployer InfraWhisper : 9 Services, Un Cluster, Zéro Prières
Le stack InfraWhisper comprend neuf services qui doivent démarrer dans un ordre spécifique et communiquer entre eux de manière fiable :
Couche infrastructure : Postgres (base de données principale), Redis (cache et sessions), Kafka (streaming d'événements), ClickHouse (base de données analytique)
Couche application : API Server (endpoints REST), AI Engine (inférence ML), Collector (ingestion d'événements), Stream Processor (pipeline de données temps réel), Dashboard (UI frontend)
En Docker Compose, je définirais les neuf dans un fichier avec des directives depends_on en croisant les doigts. En Kubernetes, chaque service a son propre Deployment et sa propre définition de Service, et l'orchestration est gérée correctement.
Étape 1 : Créer le namespace.
Tout ce qui concerne InfraWhisper vit dans son propre namespace. C'est la première chose que j'ai créée :
kubectl create namespace infrawhisper
Une commande, et j'ai maintenant un espace isolé pour toute l'application. Chaque commande à partir de maintenant utilise -n infrawhisper pour cibler ce namespace.
Étape 2 : Déployer les services d'infrastructure en premier.
Les bases de données et message brokers doivent tourner avant les services applicatifs qui en dépendent. J'ai écrit des manifestes Kubernetes (fichiers YAML) pour chacun — un Deployment définissant l'image du conteneur et les limites de ressources, et un Service définissant comment les autres pods peuvent l'atteindre.
Voici un exemple simplifié pour Postgres :
# deploy/k8s/postgres-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: postgres
namespace: infrawhisper
spec:
replicas: 1
selector:
matchLabels:
app: postgres
template:
metadata:
labels:
app: postgres
spec:
containers:
- name: postgres
image: postgres:16.2
ports:
- containerPort: 5432
env:
- name: POSTGRES_DB
value: "infrawhisper"
- name: POSTGRES_USER
valueFrom:
secretKeyRef:
name: db-credentials
key: username
- name: POSTGRES_PASSWORD
valueFrom:
secretKeyRef:
name: db-credentials
key: password
resources:
requests:
memory: "256Mi"
cpu: "250m"
limits:
memory: "512Mi"
cpu: "500m"
volumeMounts:
- name: postgres-storage
mountPath: /var/lib/postgresql/data
volumes:
- name: postgres-storage
persistentVolumeClaim:
claimName: postgres-pvc
---
apiVersion: v1
kind: Service
metadata:
name: postgres
namespace: infrawhisper
spec:
selector:
app: postgres
ports:
- port: 5432
targetPort: 5432
Remarquez plusieurs choses. Le bloc resources définit les limites de mémoire et CPU — c'est ce qui empêche un service d'affamer les autres. Le secretKeyRef tire les identifiants d'un Secret Kubernetes au lieu de les coder en dur dans le YAML. Le PersistentVolumeClaim garantit que les données survivent aux redémarrages de pods.
J'ai créé des manifestes similaires pour Redis, Kafka et ClickHouse. Puis je les ai tous déployés d'un coup :
kubectl apply -f ./deploy/k8s/
Cette commande lit chaque fichier YAML du répertoire et les applique au cluster. En trente secondes, l'interface visuelle d'OrbStack montrait quatre pods en train de démarrer — j'ai regardé le statut passer de ContainerCreating à Running un par un.
Étape 3 : Vérifier que l'infrastructure est saine avant de déployer les apps.
kubectl get pods -n infrawhisper
La sortie ressemblait à quelque chose comme :
NAME READY STATUS RESTARTS AGE
postgres-7d4f8b6c9-x2k1p 1/1 Running 0 45s
redis-5c8f9d7b2-m9n3q 1/1 Running 0 44s
kafka-6b2e8c4d1-k7p2r 1/1 Running 0 43s
clickhouse-8a1d3f5e6-j4w8t 1/1 Running 0 42s
Tous Running, tous 1/1 prêts. Si un pod affichait CrashLoopBackOff — et croyez-moi, plusieurs l'ont fait lors de mes tentatives précédentes — j'utilisais :
kubectl describe pod postgres-7d4f8b6c9-x2k1p -n infrawhisper
kubectl logs -n infrawhisper deployment/postgres
La commande describe montre les événements — échecs de pull d'image, OOM kills, erreurs de montage. La commande logs montre le stdout du conteneur. Entre ces deux-là, j'ai diagnostiqué chaque problème que j'ai rencontré.
Étape 4 : Déployer les services applicatifs.
Avec l'infrastructure qui tourne, j'ai déployé les cinq services applicatifs — API Server, AI Engine, Collector, Stream Processor et Dashboard. Même pattern : manifestes Deployment + Service, appliqués avec kubectl apply.
Le serveur API avait besoin de savoir comment atteindre Postgres et Redis. En Docker Compose, vous utiliseriez le nom du service du fichier compose. En Kubernetes, vous utilisez le nom du Service — que j'avais défini comme postgres et redis. Les chaînes de connexion ressemblaient donc à :
DATABASE_URL=postgresql://user:pass@postgres:5432/infrawhisper
REDIS_URL=redis://redis:6379
KAFKA_BROKERS=kafka:9092
Même concept, orchestrateur différent. L'abstraction du Service signifie que mon code applicatif ne se souciait pas de tourner dans Docker Compose ou Kubernetes. Il se connectait simplement à postgres:5432 dans les deux cas.
Étape 5 : Configurer l'Ingress pour l'accès externe.
Avec les neuf services tournant à l'intérieur du cluster, j'avais besoin d'un moyen d'atteindre le dashboard et le serveur API depuis mon navigateur. C'est l'Ingress :
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: infrawhisper-ingress
namespace: infrawhisper
spec:
rules:
- host: infrawhisper.local
http:
paths:
- path: /api
pathType: Prefix
backend:
service:
name: api-server
port:
number: 8080
- path: /
pathType: Prefix
backend:
service:
name: dashboard
port:
number: 3000
Après avoir appliqué ça, infrawhisper.local/api routait vers le serveur API et infrawhisper.local chargeait le dashboard. OrbStack gère la résolution DNS pour les domaines .local automatiquement sur Mac — pas besoin d'éditer /etc/hosts.
Je suis resté assis à regarder le dashboard se charger depuis un cluster Kubernetes tournant sur mon portable. Neuf services. Tous sains. Tous communiquant entre eux. J'étais passé de "je ne comprends pas vraiment les Pods" à ça en trois jours.
Si vous préférez que quelqu'un construise et déploie ce genre de configuration d'infrastructure de zéro, j'accepte des missions DevOps et architecture cloud. Vous pouvez voir ce que j'ai construit sur fiverr.com/s/EgxYmWD.
Mais le déploiement n'était que le début. La vraie puissance est apparue quand j'ai eu besoin de mettre à jour, déboguer et faire monter en charge des services sans temps d'arrêt.
Le Workflow Deploy-Update-Rollback Qui M'a Fait Confiance en Kubernetes
Voici le workflow qui tourne maintenant en boucle chaque fois que je pousse des changements sur n'importe quel service InfraWhisper :
1. Écrire le changement de code.
2. Construire une nouvelle image Docker avec un tag de version :
docker build -t api-server:v2 .
3. La pousser vers un registre de conteneurs :
docker push ghcr.io/yourname/api-server:v2
4. Déployer via Helm (ou mettre à jour l'image directement) :
En utilisant Helm — qui gère tous les manifestes Kubernetes comme un seul package :
helm upgrade --install infrawhisper ./deploy/helm/infrawhisper -n infrawhisper
Ou mettre à jour juste l'image d'un service :
kubectl set image deployment/api-server api-server=ghcr.io/yourname/api-server:v2 -n infrawhisper
5. Regarder le rollout se dérouler en temps réel :
kubectl rollout status deployment/api-server -n infrawhisper
Cette commande bloque jusqu'à ce que les nouveaux pods tournent et que les anciens soient terminés. Vous voyez une sortie comme :
Waiting for deployment "api-server" rollout to finish: 1 old replicas are pending termination...
deployment "api-server" successfully rolled out
6. Si quelque chose casse — revenez en arrière instantanément :
kubectl rollout undo deployment/api-server -n infrawhisper
Une commande. La version précédente tourne à nouveau en quelques secondes. Pas de temps d'arrêt. Pas de panique. Pas de SSH sur un serveur pour lancer git revert en priant.
Vous pouvez aussi consulter l'historique des rollouts pour voir toutes les versions précédentes :
kubectl rollout history deployment/api-server -n infrawhisper
C'est ce workflow qui m'a converti. Le filet de sécurité du rollback instantané a changé ma façon de penser les déploiements. Je suis plus enclin à livrer des mises à jour petites et fréquentes parce que le coût d'un mauvais déploiement est passé de "trente minutes de panique" à "lancer une commande."
Cela dit, j'ai rencontré pas mal de problèmes en chemin. Voici ce qui a cassé et comment j'ai corrigé.
Ce Qui a Mal Tourné (Et les Commandes Qui M'ont Sauvé)
Kubernetes a la réputation d'être complexe. Honnêtement ? La complexité n'est pas dans les concepts — elle est dans le débogage. Quand quelque chose ne marche pas, les messages d'erreur peuvent être cryptiques, et savoir quelle commande lancer dans quelle situation demande de la pratique.
Voici les patterns de débogage que j'ai réellement utilisés, organisés par type de problème.
Quand les pods ne démarrent pas — vérifiez les événements d'abord, les logs ensuite.
kubectl describe pod api-server-xxxx -n infrawhisper
La section Events en bas de la sortie describe vous dit pourquoi un pod ne démarre pas. Les coupables fréquents que j'ai rencontrés :
ImagePullBackOff— le tag de l'image n'existait pas dans le registre. Généralement une faute de frappe dans le tag de version.CrashLoopBackOff— le conteneur démarre mais plante immédiatement. C'est l'heure de vérifier les logs.Pendingsans événements — généralement un problème de ressources. Le scheduler ne trouve pas de nœud avec assez de CPU ou de mémoire.
Une fois que je savais que le pod démarrait mais plantait, les logs étaient l'étape suivante :
kubectl logs -n infrawhisper deployment/api-server
Pour un crash qui s'est déjà produit (le pod a redémarré et les logs sont ceux de la nouvelle instance) :
kubectl logs -n infrawhisper deployment/api-server --previous
Ce flag --previous m'a sauvé au moins deux fois. Les logs de l'instance actuelle disaient "démarrage sain." Les logs de l'instance précédente montraient le vrai segfault. Sans --previous, j'aurais chassé des fantômes.
Quand vous devez suivre les logs en temps réel :
kubectl logs -n infrawhisper deployment/api-server -f
Le flag -f diffuse les logs en direct. Je gardais ça en route dans un terminal pendant que je testais la connexion du processeur de streams avec Kafka. Regarder le handshake de connexion réussir en temps réel, c'était comme regarder un lancement de fusée.
Quand vous voulez une vue plus large de tout dans le namespace :
kubectl get all -n infrawhisper
Ça montre tous les deployments, services, pods et replica sets en une fois. C'est ma commande "quel est l'état du monde." Je l'ai probablement lancée une centaine de fois en trois jours.
Pour un deployment spécifique avec plus de détails :
kubectl get deployment api-server -n infrawhisper -o wide
Le flag -o wide montre l'image du conteneur et les informations du nœud — utile pour confirmer que la bonne version tourne vraiment.
Quand vous devez surveiller les changements de statut des pods en direct :
kubectl get pods -n infrawhisper -w
Le flag -w surveille les changements. Quand je déployais une mise à jour, je lançais ça dans un terminal et kubectl rollout status dans un autre, regardant les anciens pods se terminer et les nouveaux monter.
Quand vous devez forcer le redémarrage d'un service :
Parfois un service entre dans un état bizarre. Plutôt que de supprimer et recréer le deployment, un rollout restart redémarre les pods en douceur :
kubectl rollout restart deployment/api-server -n infrawhisper
Ça crée de nouveaux pods avant de terminer les anciens, donc pas de temps d'arrêt. Si vous devez tuer un pod spécifique (peut-être qu'il est coincé et vous voulez que Kubernetes le recrée) :
kubectl delete pod api-server-xxxx -n infrawhisper
Le contrôleur du Deployment remarque immédiatement le pod manquant et crée un remplacement. L'auto-réparation en action.
Quand vous devez monter en charge :
kubectl scale deployment/api-server --replicas=3 -n infrawhisper
Trois instances du serveur API, avec équilibrage de charge automatique à travers le Service. J'ai testé ça en lançant un générateur de charge contre l'API et en regardant OrbStack montrer trois pods se partageant le trafic équitablement. Redescendre en charge, c'est la même commande avec --replicas=1.
Chacune de ces commandes est devenue un réflexe à la fin du troisième jour. Le premier jour, je googlais chaque flag. Le troisième jour, je les enchaînais sans réfléchir.
Les Parties Honnêtes Que Personne N'Écrit
C'est là que je m'éloigne du typique récit "j'ai appris Kubernetes et c'était magique." Parce qu'une partie ne l'était pas. Une partie était frustrante d'une manière qui m'a fait questionner si ça valait l'investissement.
Le YAML est pénible. Il n'y a pas moyen d'y échapper. Les manifestes Kubernetes sont verbeux, sensibles à l'indentation et faciles à mal configurer silencieusement. J'ai passé quarante-cinq minutes à déboguer un deployment qui ne créait pas de pods parce que j'avais mis containerPort au mauvais niveau d'imbrication. Les linters YAML aident — j'ai commencé à lancer kubeval sur chaque manifeste avant d'appliquer — mais l'expérience développeur de l'écriture de YAML Kubernetes est le maillon le plus faible de tout l'écosystème.
Helm aide mais ajoute sa propre complexité. Les charts Helm empaquettent vos manifestes Kubernetes en templates réutilisables et paramétrables. Pour InfraWhisper, j'ai créé un chart Helm qui me permettait de déployer tout le stack en une commande :
helm upgrade --install infrawhisper ./deploy/helm/infrawhisper -n infrawhisper
Grande amélioration par rapport à l'application de quinze fichiers YAML individuellement. Mais les templates Helm utilisent la syntaxe de Go templating, qui est sa propre courbe d'apprentissage. J'avais maintenant trois couches à déboguer : mon code applicatif, mes manifestes Kubernetes, et mes templates Helm enveloppant ces manifestes. À deux reprises, une erreur de rendu dans un template Helm a produit du YAML valide qui configurait la mauvaise chose. Moments joyeux.
Les limites de ressources sont un jeu de devinettes au début. Combien de mémoire a besoin un broker Kafka ? Combien de CPU le moteur IA devrait-il avoir ? Aucune idée. Ma première tentative donnait à chaque service les mêmes limites — 256Mi de mémoire, 250m de CPU — et le moteur IA s'est immédiatement fait OOM-kill parce que l'inférence ML a besoin de plus de 256 mégaoctets de RAM. Évidemment.
J'ai fini par profiler chaque service dans Docker d'abord, en notant les pics de mémoire et CPU, et en fixant les limites à environ 2x le pic avec une marge. Pas scientifique, mais ça a marché. Kubernetes vous donne kubectl top pods -n infrawhisper pour surveiller l'utilisation réelle une fois que les choses tournent, et j'ai ajusté les limites sur quelques jours en me basant sur des données réelles.
La courbe d'apprentissage est concentrée au début. Le jour un était brutal. Le jour deux productif. Le jour trois rapide. Les concepts ne sont pas intrinsèquement difficiles — ils sont juste inconnus. Une fois que le modèle mental fait tilt (et j'espère que celui que j'ai présenté plus tôt aide), les commandes deviennent des extensions logiques de ce que vous essayez de faire. "Je veux trois réplicas" se mappe directement à kubectl scale. "Je veux voir les logs" se mappe à kubectl logs. Les noms des commandes sont les concepts.
Si je devais recommencer, je changerais une chose : je commencerais avec deux ou trois services au lieu de neuf. Tout déployer d'un coup signifiait que quand quelque chose cassait, la panne pouvait être dans n'importe lequel des neuf endroits. Commencer petit, vérifier le workflow avec une app simple et une base de données, puis ajouter des services progressivement — c'est l'approche que je recommanderais.
C'est aussi une de ces situations où Kubernetes n'est pas toujours la bonne réponse. Si votre application est un seul conteneur avec une base de données, Docker Compose est probablement suffisant. La surcharge de Kubernetes ne se rentabilise que quand vous avez plusieurs services qui nécessitent un scaling indépendant, de l'auto-réparation et des déploiements sans temps d'arrêt. Pour les neuf services d'InfraWhisper, ce seuil était clairement atteint. Pour un side project à deux conteneurs, peut-être pas.
Le Cheat Sheet kubectl d'InfraWhisper
Après trois jours de déploiements, débogage, mises à jour et jurons occasionnels devant des fichiers YAML, voici les commandes que j'utilise constamment. Je garde cette liste épinglée dans mes notes de terminal.
Avant de déployer — vérifiez que votre cluster est prêt :
kubectl cluster-info
kubectl get nodes
kubectl get all -n infrawhisper
Déployer et appliquer des configurations :
kubectl apply -f deployment.yaml
kubectl apply -f ./deploy/k8s/
helm upgrade --install infrawhisper ./deploy/helm/infrawhisper -n infrawhisper
Mettre à jour l'image d'un service :
kubectl set image deployment/api-server api-server=ghcr.io/yourname/api-server:v2 -n infrawhisper
kubectl rollout status deployment/api-server -n infrawhisper
Vérifier ce qui tourne :
kubectl get pods -n infrawhisper
kubectl get pods -n infrawhisper -w
kubectl describe pod api-server-xxxx -n infrawhisper
kubectl get deployment api-server -n infrawhisper -o wide
Lire les logs et déboguer :
kubectl logs -n infrawhisper deployment/api-server
kubectl logs -n infrawhisper deployment/api-server -f
kubectl logs -n infrawhisper deployment/api-server --previous
Revenir en arrière quand ça tourne mal :
kubectl rollout undo deployment/api-server -n infrawhisper
kubectl rollout history deployment/api-server -n infrawhisper
Monter ou descendre en charge :
kubectl scale deployment/api-server --replicas=3 -n infrawhisper
Redémarrer ou supprimer :
kubectl rollout restart deployment/api-server -n infrawhisper
kubectl delete pod api-server-xxxx -n infrawhisper
Le cycle complet du build au deploy :
docker build -t api-server:v2 .
docker push ghcr.io/yourname/api-server:v2
helm upgrade infrawhisper ./deploy/helm/infrawhisper -n infrawhisper
kubectl get pods -n infrawhisper
kubectl logs -n infrawhisper deployment/api-server -f
kubectl rollout undo deployment/api-server -n infrawhisper # if needed
Imprimez ça. Épinglez-le. Vous utiliserez chacune de ces commandes dans votre première semaine.
Ce Que Ça Change Pour la Suite
Il y a trois jours, l'idée de faire tourner neuf services dans un cluster orchestré semblait nécessiter des mois de formation DevOps et une équipe d'ingénieurs infrastructure.
Ce n'est pas le cas. Ça nécessite un Mac, OrbStack, quelques fichiers YAML, et la volonté de traverser environ huit heures de confusion avant que les choses ne commencent à faire sens. Les outils sont devenus assez bons pour qu'un ingénieur logiciel — pas un spécialiste DevOps, un ingénieur logiciel — puisse passer de zéro à un cluster local de qualité production en un long week-end.
Ce que j'emporte avec moi n'est pas juste une configuration Kubernetes fonctionnelle. C'est un changement de mentalité. Je pense aux applications différemment maintenant. Je pense en services, en pods et en deployments. Je pense à ce qui se passe quand les choses échouent, pas seulement quand elles marchent. Je pense au scaling comme un curseur que je peux ajuster, pas comme une crise que je dois résoudre par de l'ingénierie.
Le déploiement InfraWhisper tourne toujours sur mon cluster local OrbStack pendant que j'écris ceci. Neuf pods, tous au vert, tous en bonne santé. Kafka traite des événements, ClickHouse stocke des analytics, le dashboard affiche des données en temps réel. Et si l'un d'eux plante maintenant — Kubernetes le remettra debout avant que je finisse cette phrase.
Si vous avez repoussé Kubernetes comme je le faisais — le traitant comme du savoir infrastructure destiné à quelqu'un d'autre — voici votre signal. Installez OrbStack ce soir. Déployez un service demain. Ajoutez-en un deuxième le jour suivant. Au troisième jour, vous vous demanderez pourquoi vous avez attendu si longtemps.
C'est quoi ce service dans votre stack qui plante tout le temps et que personne ne redémarre ? Commencez par là.
Foire Aux Questions
Peut-on faire tourner Kubernetes en local sur Mac sans Docker Desktop ?
Oui. OrbStack fournit un cluster Kubernetes complet sur Mac sans Docker Desktop. Il inclut à la fois Docker et Kubernetes, utilise significativement moins de mémoire (environ 1.5 à 2 Go contre 4 à 6 Go), et démarre en secondes. Installez depuis orbstack.dev et activez Kubernetes dans les paramètres.
Combien de services OrbStack peut-il gérer sur un cluster Kubernetes local ?
OrbStack gère confortablement 10 à 15 services sur un Mac série M avec 16 Go de RAM. J'ai fait tourner 9 services dont Postgres, Redis, Kafka et ClickHouse simultanément sans problèmes de performance. Les limites de ressources sur chaque deployment empêchent un seul service d'affamer les autres.
Quelle est la différence entre kubectl apply et helm upgrade ?
kubectl apply -f déploie des fichiers de manifeste YAML individuels directement. helm upgrade --install déploie un chart Helm — un package de manifestes paramétrés avec des valeurs configurables. Helm est meilleur pour les applications multi-services complexes ; kubectl brut fonctionne bien pour les déploiements simples. Consultez la section Implémentation ci-dessus pour les deux approches.
Comment déboguer un pod coincé en CrashLoopBackOff ?
Lancez kubectl describe pod [nom-pod] -n [namespace] pour vérifier les Events et la raison du crash, puis kubectl logs -n [namespace] deployment/[nom] --previous pour voir les logs de l'instance plantée. Le flag --previous est critique — il montre la sortie du dernier conteneur, pas la tentative de redémarrage actuelle.
Kubernetes est-il excessif pour les petits projets ?
Pour un seul conteneur avec une base de données, oui — Docker Compose est plus simple et suffisant. Kubernetes se rentabilise quand vous faites tourner 3+ services nécessitant un scaling indépendant, des redémarrages auto-réparants et des déploiements sans temps d'arrêt. Le point d'équilibre se situe à peu près là où docker-compose commence à nécessiter des outils externes pour la fiabilité.
Let's Work Together
Looking to build AI systems, automate workflows, or scale your tech infrastructure? I'd love to help.
- Fiverr (custom builds & integrations): fiverr.com/s/EgxYmWD
- Portfolio: mejba.me
- Ramlit Limited (enterprise solutions): ramlit.com
- ColorPark (design & branding): colorpark.io
- xCyberSecurity (security services): xcybersecurity.io