Von null auf 9 Services auf Kubernetes mit OrbStack
Vor drei Tagen hätte ich dir nicht ehrlich sagen können, was der Unterschied zwischen einem Pod und einem Deployment ist. Ich hatte vielleicht ein dutzend Mal über Kubernetes gelesen, bei Architekturdiagrammen mitgenickt und leise den Tab geschlossen, jedes Mal wenn ein Tutorial zum kubectl apply-Teil kam. Es fühlte sich an wie Infrastrukturwissen, das für jemand anderen bestimmt war — Platform Engineers, DevOps-Spezialisten, Menschen die in YAML träumen.
Dann musste ich InfraWhisper ausliefern.
InfraWhisper ist eine Monitoring- und Analyseplattform, die ich baue — Dashboard, API-Server, AI-Engine, Datenkollector, Stream-Prozessor, plus die Datenbanken und Message Broker, die alles zusammenhalten. Neun Services insgesamt. Sie mit docker-compose up laufen zu lassen funktionierte gut auf meinem Laptop. Aber in dem Moment, als ich anfing, über Produktion nachzudenken — darüber, was passiert wenn der API-Server um 3 Uhr morgens crasht, über das Skalieren des Stream-Prozessors bei Verkehrsspitzen, über das Deployen von Updates ohne das Dashboard herunterzunehmen — begann Docker Compose sich wie ein Fahrrad auf der Autobahn anzufühlen.
Also setzte ich mich mit Kubernetes hin. Und OrbStack. Und drei Tagen hartnäckiger Ausdauer.
Was auf der anderen Seite herauskam, war ein vollständig orchestriertes lokales Cluster mit allen neun InfraWhisper-Services laufend, selbstheilend und über einen einzigen Ingress-Endpoint erreichbar. Dieser Beitrag ist alles, was ich dabei gelernt habe — die mentalen Modelle, die wirklich geklickt haben, die Befehle, die zählen, und die Fehler, die mich Stunden gekostet haben, damit sie dich nicht dasselbe kosten.
Warum ich aufgehört habe, Kubernetes als optional zu behandeln
Das hat mich endgültig über die Schwelle gebracht. Ich hatte InfraWhisper in Docker Compose auf einem Staging-Server laufen. Fünf Services, vier Datenbanken, alles kommunizierend über ein Docker-Netzwerk. Es funktionierte. Dann lief der Kafka-Container aus dem Speicher und starb.
Nichts startete ihn neu. Der Stream-Prozessor, der von Kafka abhängt, begann Verbindungsfehler zu werfen. Der Collector, der Events in Kafka pusht, begann still Daten zu verlieren. Das Dashboard lud noch — alles sah gut aus — aber die gesamte Analyse-Pipeline war tot. Ich bemerkte es sechs Stunden lang nicht.
Mit Docker allein bleibt ein abgestürzter Container abgestürzt. Du brauchst externe Tools — systemd, supervisord, benutzerdefinierte Health-Check-Scripts — um die Zuverlässigkeit anzuflanschen, die eingebaut sein sollte. Du bastelst einen Frankenstein aus Bash-Scripts zusammen und betest, dass sie jeden Fehlermodus abdecken.
Kubernetes handhabt das nativ. Ein Container stirbt, Kubernetes startet ihn neu. Ein Node fällt aus, Kubernetes verschiebt Pods auf gesunde Nodes. Du pushst ein kaputtes Update, du führst einen Befehl aus und bist zurück bei der vorherigen Version. Das ist keine theoretische Resilienz — so funktioniert Produktionsinfrastruktur tatsächlich bei Unternehmen mit echten Workloads.
Die Kluft zwischen „Ich verstehe, warum Kubernetes wichtig ist" und „Ich kann tatsächlich auf Kubernetes deployen" fühlte sich von außen riesig an. War sie nicht. Und OrbStack machte diese Kluft noch kleiner.
Aber bevor ich in das Setup einsteige, brauchst du das mentale Modell. Denn Kubernetes-Befehle ergeben null Sinn, bis du die sechs Konzepte verstehst, auf denen sie operieren.
Die sechs Kubernetes-Konzepte, die wirklich zählen
Ich habe Kubernetes-Dokumentation gelesen, die vierzig Konzepte im ersten Kapitel einführt. Das ist überwältigend und, ehrlich gesagt, kontraproduktiv. Als ich lernte, waren nur sechs Konzepte wichtig, um eine echte Anwendung zu deployen. Alles andere ist Optimierung, die du später lernen kannst.
Container. Docker verpackt deinen Anwendungscode, Abhängigkeiten und Runtime in eine einzige tragbare Einheit. Du baust es einmal, und es läuft identisch auf deinem Laptop, einem CI-Server oder einer Cloud-VM. Wenn du jemals Docker verwendet hast, kennst du dieses bereits. Der Container ist das Atom.
Pod. Kubernetes führt Container nicht direkt aus. Es wickelt sie in einen Pod — die kleinste deploybare Einheit in K8s. Ein Pod ist normalerweise ein Container, manchmal zwei, wenn du einen Sidecar brauchst (wie einen Log-Forwarder, der neben deiner App läuft). Denke an den Pod als Container mit einer Postadresse.
Deployment. Hier beginnt Kubernetes seine Komplexität zu verdienen. Ein Deployment definiert, wie viele Kopien (Replicas) eines Pods zu jedem Zeitpunkt laufen sollen. Wenn du sagst „Ich will 3 Replicas des API-Servers" und einer crasht, bemerkt Kubernetes die Lücke und startet einen Ersatz. Du deklarierst den gewünschten Zustand. Kubernetes bringt die Realität zum Übereinstimmen.
Service. Pods bekommen zufällige IP-Adressen, die sich bei jedem Neustart ändern. Ein Service gibt deinem Pod einen stabilen DNS-Namen — damit das Dashboard den API-Server unter api-server:8080 erreichen kann, anstatt nach der IP zu jagen, die der Pod diesmal bekommen hat. Services sind das interne Telefonbuch deines Clusters.
Ingress. Services behandeln Verkehr innerhalb des Clusters. Ingress behandelt Verkehr, der von außen kommt — Browser-Anfragen, API-Aufrufe, Webhooks. Es ist die Eingangstür, die app.local/api zum API-Server-Service und app.local/dashboard zum Dashboard-Service routet.
Namespace. Eine logische Grenze, die verwandte Ressourcen gruppiert. Alle neun InfraWhisper-Services leben im infrawhisper-Namespace. Das hält sie isoliert von System-Services und allem anderen, was auf dem Cluster läuft. Es ist auch der Grund, warum fast jeder kubectl-Befehl, den ich dir zeige, mit -n infrawhisper endet.
Das war's. Container geht in einen Pod. Deployment verwaltet, wie viele Pods laufen. Service gibt ihnen stabile Namen. Ingress routet externen Verkehr herein. Namespace hält alles organisiert.
Mit diesem mentalen Modell geladen, beginnen die Befehle intuitiv zu werden. Und apropos Befehle — lass mich dir vom Tool erzählen, das das lokale Ausführen all dessen fast mühelos machte.
Warum OrbStack meine gesamte Erfahrung veränderte
Ich hatte Docker Desktop zuvor versucht. Es funktionierte, aber „funktionierte" leistet schwere Arbeit in diesem Satz. Die Speichernutzung war brutal — 4 bis 6 GB nur im Idle. Die Kubernetes-Integration fühlte sich angeflanscht an, oft hinterherhinkend oder sich anders verhaltend als echte Cluster. Das Starten dauerte lange genug, dass ich Twitter öffnete, während ich wartete, und so verliert man zwanzig Minuten, bevor man eine einzige Zeile Code schreibt.
OrbStack ist anders auf Weisen, die wirklich zählen für das Lernen von Kubernetes.
Es ist leichtgewichtig. Das Starten dauert Sekunden, nicht Minuten. Die Speichernutzung bleibt vernünftig — um 1,5 bis 2 GB, selbst mit einem vollen Kubernetes-Cluster laufend. Auf einem M-Serien Mac fühlt es sich nativ an auf eine Weise, die Docker Desktop nie tat.
Die Kubernetes-Integration ist eingebaut und funktioniert einfach. Ein Schalter in den Einstellungen, und du hast ein Single-Node-Cluster lokal laufen. Kein minikube. Kein kind. Keine VM-Treiber konfigurieren. OrbStack gibt dir ein echtes Kubernetes-Cluster, unterstützt von containerd, zugänglich über die Standard-kubectl- und helm-Befehle. Deine kubeconfig wird automatisch aktualisiert.
Aber die Funktion, die mir am meisten Zeit gespart hat — und das hätte ich nicht erwartet — ist die visuelle Oberfläche. OrbStack zeigt dir laufende Container, Pods, Ressourcennutzung und Logs in einer sauberen GUI. Wenn du Kubernetes lernst und ein Pod ständig in einer Crash-Schleife steckt, ist das Sehen dessen, was über alle neun Services gleichzeitig passiert, mehr wert als jede Terminal-Ausgabe. Ich hatte das OrbStack-Dashboard auf einem Monitor und mein Terminal auf dem anderen, und beobachtete Pods in Echtzeit hochfahren, während ich Konfigurationen anwendete.
Ich möchte klar sein: OrbStack ist kein Spielzeug oder eine Abkürzung. Das Cluster, das es ausführt, verhält sich wie ein echtes Kubernetes-Cluster. Alles, was ich lokal gelernt und deployt habe, ließ sich direkt übertragen, als ich später kubectl auf ein Remote-Cluster richtete. OrbStack entfernte einfach die Reibung, die mir nichts Nützliches beibrachte.
Das Einrichten dauerte etwa fünf Minuten. Installiere OrbStack von orbstack.dev, öffne es, aktiviere Kubernetes in den Einstellungen und verifiziere mit:
kubectl cluster-info
kubectl get nodes
Wenn beide Befehle saubere Ausgabe liefern, hast du ein funktionierendes Cluster. Zeit, etwas Echtes zu deployen.
Wie funktioniert Kubernetes-Architektur eigentlich unter der Haube?
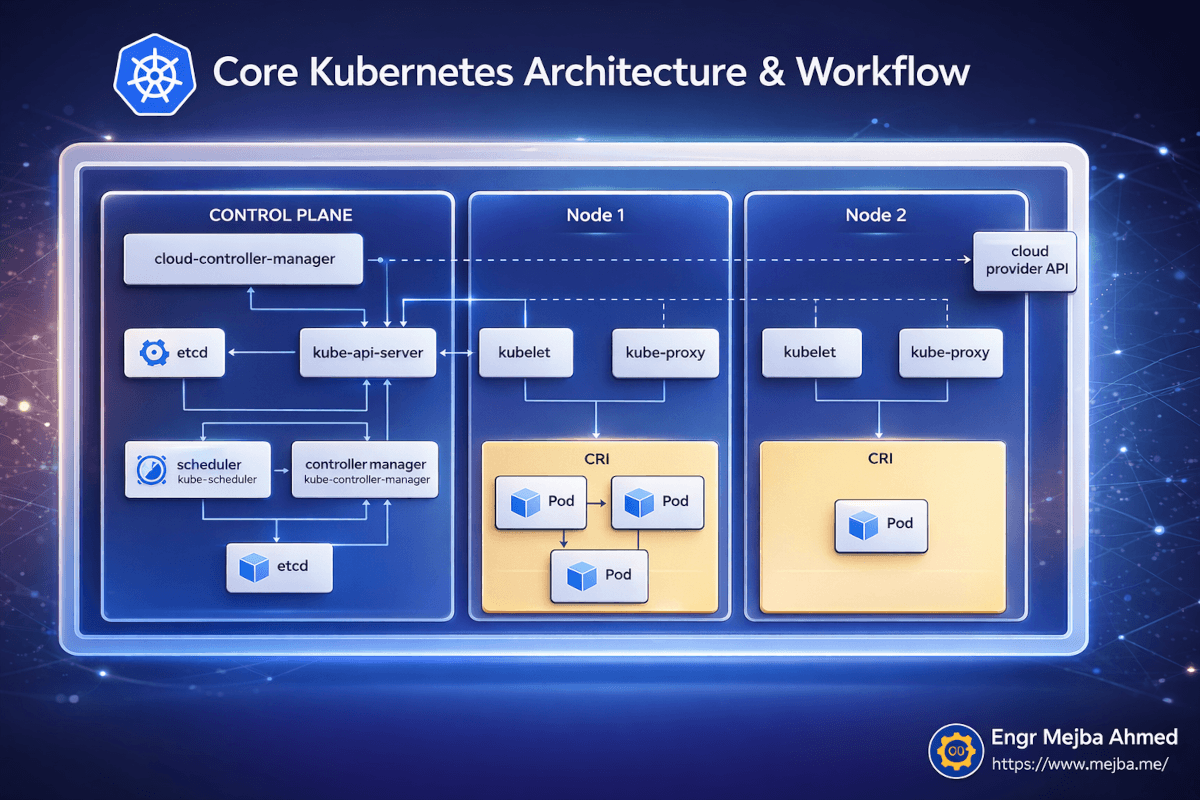
Bevor ich anfing, Services zu deployen, verbrachte ich eine Stunde damit zu verstehen, was tatsächlich auf meiner Maschine lief. Das zahlte sich enorm aus, als Dinge später kaputtgingen, weil ich über wo im System das Problem lag nachdenken konnte.
Kubernetes folgt einer Control Plane und Worker Node-Architektur. Selbst auf einem Single-Node lokalen Cluster wie OrbStack es bietet, laufen beide Rollen auf derselben Maschine.
Das Control Plane ist das Gehirn. Es hat fünf Komponenten, die zählen:
Der kube-api-server ist die Eingangstür zu allem. Jeder kubectl-Befehl, den du ausführst, spricht mit diesem API-Server. Er validiert deine Anfragen, aktualisiert den Cluster-Zustand und sagt Nodes, was sie tun sollen. Wenn ich kubectl apply -f deployment.yaml ausführe, sende ich dieses YAML an den API-Server, der den gewünschten Zustand speichert und orchestriert, um ihn Wirklichkeit werden zu lassen.
etcd ist die Datenbank, die den gesamten Cluster-Zustand speichert. Jedes Deployment, jeder Service, jeder Pod-Status — alles ist in etcd. Ich habe es nie direkt berührt, aber zu wissen, dass es existiert, erklärt, warum Kubernetes sich von fast allem erholen kann. Der gewünschte Zustand ist immer persistent gespeichert.
Der Scheduler entscheidet, welcher Node jeden neuen Pod ausführen soll. Auf einem Multi-Node-Cluster findet hier Bin-Packing und Ressourcenoptimierung statt. Auf meinem Single-Node OrbStack-Setup geht jeder Pod zum selben Node — aber der Scheduler läuft trotzdem, und ihn zu verstehen half, als ich später zu Multi-Node wechselte.
Der Controller Manager führt die Abstimmungsschleifen aus, die Kubernetes selbstheilend machen. Er vergleicht ständig „was sollte laufen" (den gewünschten Zustand in etcd) mit „was läuft tatsächlich" (den aktuellen Zustand aus Node-Berichten). Wenn es eine Diskrepanz gibt, handelt er. Pod abgestürzt? Der Controller Manager bemerkt es und sagt dem Scheduler, einen Ersatz zu erstellen.
Der Cloud-Controller-Manager handhabt Integrationen mit Cloud-Providern — Load Balancer, Storage Volumes, Node-Lebenszyklus. Auf einem lokalen OrbStack-Cluster ist dies weitgehend ruhend, aber es ist gut zu wissen, dass es existiert, für wenn du auf AWS oder GCP deployst.
Auf der Node-Seite laufen drei Dinge:
kubelet ist der Agent auf jedem Node, der Anweisungen vom API-Server empfängt und Pods auf diesem Node verwaltet. Er zieht Container-Images, startet Container, berichtet den Gesundheitszustand zurück an das Control Plane.
kube-proxy handhabt Netzwerk-Routing innerhalb des Nodes und stellt sicher, dass Verkehr, der an einen Service gerichtet ist, den richtigen Pod erreicht.
CRI (Container Runtime Interface) ist die eigentliche Container-Runtime — containerd im Fall von OrbStack — die deine Container ausführt.
Hier ist, warum diese Architekturübersicht nicht nur akademisch ist: Als mein API-Server-Pod ständig in einer Crash-Schleife steckte, wusste ich, dass ich kubectl describe pod prüfen musste (was den API-Server nach Pod-Events abfragt), anstatt nur auf Logs zu starren. Die describe-Ausgabe sagte mir, dass der Container OOM-killed wurde — ein Ressourcenlimit-Problem, kein Code-Problem. Ohne das mentale Modell, wie Kubernetes-Komponenten interagieren, hätte ich Stunden mit dem Debuggen von Anwendungscode verschwendet, der eigentlich in Ordnung war.
Jetzt — lass mich dich durch das Deployen aller neun InfraWhisper-Services führen. Hier wird Theorie zu Praxis.
InfraWhisper deployen: 9 Services, ein Cluster, null Gebete
Der InfraWhisper-Stack hat neun Services, die in einer bestimmten Reihenfolge hochfahren und zuverlässig miteinander kommunizieren müssen:
Infrastrukturschicht: Postgres (primäre Datenbank), Redis (Caching und Sessions), Kafka (Event Streaming), ClickHouse (Analyse-Datenbank)
Anwendungsschicht: API Server (REST-Endpoints), AI Engine (ML-Inferenz), Collector (Event-Ingestion), Stream Processor (Echtzeit-Datenpipeline), Dashboard (Frontend-UI)
In Docker Compose würde ich alle neun in einer Datei definieren mit depends_on-Direktiven und auf das Beste hoffen. In Kubernetes bekommt jeder Service seine eigene Deployment- und Service-Definition, und die Orchestrierung wird korrekt gehandhabt.
Schritt 1: Namespace erstellen.
Alles von InfraWhisper lebt in seinem eigenen Namespace. Das war das Erste, was ich erstellte:
kubectl create namespace infrawhisper
Ein Befehl, und jetzt habe ich einen isolierten Bereich für die gesamte Anwendung. Jeder Befehl von hier an verwendet -n infrawhisper, um diesen Namespace anzuvisieren.
Schritt 2: Infrastruktur-Services zuerst deployen.
Datenbanken und Message Broker müssen laufen, bevor die Anwendungs-Services, die von ihnen abhängen. Ich schrieb Kubernetes-Manifeste (YAML-Dateien) für jeden — ein Deployment, das das Container-Image und Ressourcenlimits definiert, und einen Service, der bestimmt, wie andere Pods ihn erreichen können.
Hier ist ein vereinfachtes Beispiel für Postgres:
# deploy/k8s/postgres-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: postgres
namespace: infrawhisper
spec:
replicas: 1
selector:
matchLabels:
app: postgres
template:
metadata:
labels:
app: postgres
spec:
containers:
- name: postgres
image: postgres:16.2
ports:
- containerPort: 5432
env:
- name: POSTGRES_DB
value: "infrawhisper"
- name: POSTGRES_USER
valueFrom:
secretKeyRef:
name: db-credentials
key: username
- name: POSTGRES_PASSWORD
valueFrom:
secretKeyRef:
name: db-credentials
key: password
resources:
requests:
memory: "256Mi"
cpu: "250m"
limits:
memory: "512Mi"
cpu: "500m"
volumeMounts:
- name: postgres-storage
mountPath: /var/lib/postgresql/data
volumes:
- name: postgres-storage
persistentVolumeClaim:
claimName: postgres-pvc
---
apiVersion: v1
kind: Service
metadata:
name: postgres
namespace: infrawhisper
spec:
selector:
app: postgres
ports:
- port: 5432
targetPort: 5432
Beachte ein paar Dinge. Der resources-Block setzt Speicher- und CPU-Limits — das verhindert, dass ein Service die anderen aushungert. Der secretKeyRef zieht Credentials aus einem Kubernetes Secret, anstatt sie in der YAML hart zu codieren. Der PersistentVolumeClaim stellt sicher, dass Daten Pod-Neustarts überleben.
Ich erstellte ähnliche Manifeste für Redis, Kafka und ClickHouse. Dann deployete ich sie alle auf einmal:
kubectl apply -f ./deploy/k8s/
Dieser Befehl liest jede YAML-Datei im Verzeichnis und wendet sie auf das Cluster an. Innerhalb von dreißig Sekunden zeigte OrbStacks visuelle Oberfläche vier Pods, die hochfuhren — ich beobachtete den Status von ContainerCreating zu Running übergehen, einen nach dem anderen.
Schritt 3: Infrastruktur-Gesundheit verifizieren, bevor Apps deployt werden.
kubectl get pods -n infrawhisper
Die Ausgabe sah ungefähr so aus:
NAME READY STATUS RESTARTS AGE
postgres-7d4f8b6c9-x2k1p 1/1 Running 0 45s
redis-5c8f9d7b2-m9n3q 1/1 Running 0 44s
kafka-6b2e8c4d1-k7p2r 1/1 Running 0 43s
clickhouse-8a1d3f5e6-j4w8t 1/1 Running 0 42s
Alle Running, alle 1/1 bereit. Wenn ein Pod CrashLoopBackOff zeigte — und glaub mir, mehrere taten das bei meinen früheren Versuchen — verwendete ich:
kubectl describe pod postgres-7d4f8b6c9-x2k1p -n infrawhisper
kubectl logs -n infrawhisper deployment/postgres
Der describe-Befehl zeigt Events — Image-Pull-Fehler, OOM-Kills, Mount-Fehler. Der logs-Befehl zeigt die stdout des Containers. Zwischen diesen beiden diagnostizierte ich jedes Problem, auf das ich stieß.
Schritt 4: Anwendungs-Services deployen.
Mit laufender Infrastruktur deployete ich die fünf Anwendungs-Services — API Server, AI Engine, Collector, Stream Processor und Dashboard. Gleiches Muster: Deployment + Service-Manifeste, angewendet mit kubectl apply.
Der API-Server musste wissen, wie er Postgres und Redis erreicht. In Docker Compose würdest du den Servicenamen aus der Compose-Datei verwenden. In Kubernetes verwendest du den Service-Namen — den ich auf postgres und redis gesetzt hatte. Die Verbindungsstrings sahen also so aus:
DATABASE_URL=postgresql://user:pass@postgres:5432/infrawhisper
REDIS_URL=redis://redis:6379
KAFKA_BROKERS=kafka:9092
Gleiches Konzept, anderer Orchestrator. Die Service-Abstraktion bedeutet, dass es meinem Anwendungscode egal ist, ob er in Docker Compose oder Kubernetes läuft. Er verbindet sich einfach mit postgres:5432 in beiden Fällen.
Schritt 5: Ingress für externen Zugriff einrichten.
Mit allen neun Services, die im Cluster laufen, brauchte ich eine Möglichkeit, das Dashboard und den API-Server aus meinem Browser zu erreichen. Das ist Ingress:
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: infrawhisper-ingress
namespace: infrawhisper
spec:
rules:
- host: infrawhisper.local
http:
paths:
- path: /api
pathType: Prefix
backend:
service:
name: api-server
port:
number: 8080
- path: /
pathType: Prefix
backend:
service:
name: dashboard
port:
number: 3000
Nach dem Anwenden routete infrawhisper.local/api zum API-Server und infrawhisper.local lud das Dashboard. OrbStack handhabt die DNS-Auflösung für .local-Domains automatisch auf dem Mac — keine /etc/hosts-Bearbeitung nötig.
Ich saß da und starrte auf das Dashboard, das von einem Kubernetes-Cluster auf meinem Laptop lud. Neun Services. Alle gesund. Alle miteinander kommunizierend. Ich war von „Ich verstehe Pods nicht wirklich" zu diesem Punkt in drei Tagen gekommen.
Wenn du lieber jemanden diese Art von Infrastruktur-Setup von Grund auf bauen und deployen lassen möchtest, übernehme ich DevOps- und Cloud-Architektur-Aufträge. Du kannst sehen, was ich gebaut habe unter fiverr.com/s/EgxYmWD.
Aber das Deployment war nur der Anfang. Die echte Stärke zeigte sich, als ich Services aktualisieren, debuggen und skalieren musste, ohne Downtime.
Der Deploy-Update-Rollback-Workflow, der mich Kubernetes vertrauen ließ
Das ist der Workflow, der jetzt auf Wiederholung läuft, wenn ich Änderungen an einem InfraWhisper-Service pushe:
1. Code-Änderung schreiben.
2. Neues Docker-Image mit Versions-Tag bauen:
docker build -t api-server:v2 .
3. In eine Container-Registry pushen:
docker push ghcr.io/yourname/api-server:v2
4. Via Helm deployen (oder das Image direkt aktualisieren):
Mit Helm — das alle Kubernetes-Manifeste als ein Paket verwaltet:
helm upgrade --install infrawhisper ./deploy/helm/infrawhisper -n infrawhisper
Oder nur das Image eines Services aktualisieren:
kubectl set image deployment/api-server api-server=ghcr.io/yourname/api-server:v2 -n infrawhisper
5. Den Rollout in Echtzeit beobachten:
kubectl rollout status deployment/api-server -n infrawhisper
Dieser Befehl blockiert, bis die neuen Pods laufen und die alten beendet sind. Du siehst Ausgabe wie:
Waiting for deployment "api-server" rollout to finish: 1 old replicas are pending termination...
deployment "api-server" successfully rolled out
6. Wenn etwas kaputtgeht — sofort zurückrollen:
kubectl rollout undo deployment/api-server -n infrawhisper
Ein Befehl. Die vorherige Version läuft innerhalb von Sekunden wieder. Keine Downtime. Keine Panik. Kein SSH auf einen Server und git revert ausführen und beten.
Du kannst sogar den Rollout-Verlauf einsehen, um alle vorherigen Versionen zu sehen:
kubectl rollout history deployment/api-server -n infrawhisper
Dieser Workflow hat mich überzeugt. Das Sicherheitsnetz des sofortigen Rollbacks veränderte, wie ich über Deployments denke. Ich bin eher bereit, kleine, häufige Updates auszuliefern, weil die Kosten eines schlechten Deployments von „dreißig Minuten Hektik" auf „einen Befehl ausführen" gefallen sind.
Das gesagt, ich bin unterwegs auf genug Probleme gestoßen. Hier ist, was kaputtging und wie ich es behoben habe.
Was schiefging (und die Befehle, die mich retteten)
Kubernetes hat einen Ruf für Komplexität. Ehrlich? Die Komplexität liegt nicht in den Konzepten — sie liegt im Debugging. Wenn etwas nicht funktioniert, können die Fehlermeldungen kryptisch sein, und zu wissen, welchen Befehl man in welcher Situation ausführt, erfordert Übung.
Hier sind die Debug-Muster, die ich tatsächlich verwendet habe, organisiert nach Problemtyp.
Wenn Pods nicht starten wollen — zuerst Events prüfen, dann Logs.
kubectl describe pod api-server-xxxx -n infrawhisper
Der Events-Abschnitt am Ende der describe-Ausgabe sagt dir warum ein Pod nicht startet. Häufige Übeltäter, auf die ich stieß:
ImagePullBackOff— der Image-Tag existierte nicht in der Registry. Normalerweise ein Tippfehler im Versions-Tag.CrashLoopBackOff— der Container startet, crasht aber sofort. Zeit, Logs zu prüfen.Pendingohne Events — normalerweise ein Ressourcenproblem. Der Scheduler kann keinen Node mit genug CPU oder Speicher finden.
Sobald ich wusste, dass der Pod startete aber crashte, waren Logs der nächste Halt:
kubectl logs -n infrawhisper deployment/api-server
Für einen Crash, der bereits passiert ist (der Pod hat neugestartet und die Logs sind von der neuen Instanz):
kubectl logs -n infrawhisper deployment/api-server --previous
Dieses --previous-Flag hat mich mindestens zweimal gerettet. Die Logs der aktuellen Instanz sagten „gesunder Start." Die Logs der vorherigen Instanz zeigten den tatsächlichen Segfault. Ohne --previous hätte ich Geistern nachgejagt.
Wenn du Logs in Echtzeit beobachten musst:
kubectl logs -n infrawhisper deployment/api-server -f
Das -f-Flag streamt Logs live. Ich ließ dies in einem Terminal laufen, während ich die Verbindung des Stream-Prozessors zu Kafka testete. Den Verbindungshandshake in Echtzeit gelingen zu sehen, fühlte sich an wie eine Raketenstart zu beobachten.
Wenn du einen breiteren Überblick über alles im Namespace willst:
kubectl get all -n infrawhisper
Das zeigt alle Deployments, Services, Pods und Replica Sets auf einmal. Es ist mein „wie ist der Zustand der Welt"-Befehl. Ich habe ihn wahrscheinlich hundert Mal in drei Tagen ausgeführt.
Für ein bestimmtes Deployment mit extra Detail:
kubectl get deployment api-server -n infrawhisper -o wide
Das -o wide-Flag zeigt Container-Image und Node-Informationen — nützlich um zu bestätigen, dass die richtige Version tatsächlich läuft.
Wenn du Pod-Statusänderungen live beobachten willst:
kubectl get pods -n infrawhisper -w
Das -w-Flag überwacht Änderungen. Wenn ich ein Update deployete, ließ ich das in einem Terminal laufen und kubectl rollout status im anderen, und beobachtete alte Pods beenden und neue hochfahren.
Wenn du einen Service erzwungen neu starten musst:
Manchmal gerät ein Service in einen seltsamen Zustand. Anstatt das Deployment zu löschen und neu zu erstellen, startet ein Rollout Restart die Pods auf elegante Weise neu:
kubectl rollout restart deployment/api-server -n infrawhisper
Das erstellt neue Pods bevor alte beendet werden, also gibt es keine Downtime. Wenn du einen bestimmten Pod killen musst (vielleicht steckt er fest und du willst, dass Kubernetes ihn neu erstellt):
kubectl delete pod api-server-xxxx -n infrawhisper
Der Deployment-Controller bemerkt den fehlenden Pod sofort und erstellt einen Ersatz. Selbstheilung in Aktion.
Wenn du unter Last skalieren musst:
kubectl scale deployment/api-server --replicas=3 -n infrawhisper
Drei Instanzen des API-Servers, automatisch über den Service lastverteilt. Ich testete das, indem ich einen Last-Generator gegen die API laufen ließ und OrbStack beobachtete, wie drei Pods den Verkehr gleichmäßig teilten. Zurückskalieren ist derselbe Befehl mit --replicas=1.
Jeder dieser Befehle wurde bis Ende Tag drei zum Muskelgedächtnis. Am ersten Tag googelte ich jedes Flag. Am dritten Tag kettete ich sie ohne nachzudenken aneinander.
Die ehrlichen Teile, über die niemand schreibt
Hier weiche ich vom typischen „Ich lernte Kubernetes und es war magisch"-Narrativ ab. Denn einiges davon war nicht magisch. Einiges war frustrierend auf Weisen, die mich fragen ließen, ob die Investition es wert war.
YAML ist schmerzhaft. Daran führt kein Weg vorbei. Kubernetes-Manifeste sind ausführlich, einrückungssensitiv und leicht stillschweigend falsch zu konfigurieren. Ich verbrachte fünfundvierzig Minuten mit dem Debuggen eines Deployments, das keine Pods erstellen wollte, weil ich containerPort auf der falschen Verschachtelungsebene hatte. YAML-Linter helfen — ich begann kubeval auf jedem Manifest auszuführen, bevor ich es anwendete — aber die Entwicklererfahrung des Schreibens von Kubernetes-YAML ist das schwächste Glied im gesamten Ökosystem.
Helm hilft, fügt aber eigene Komplexität hinzu. Helm Charts verpacken deine Kubernetes-Manifeste in wiederverwendbare, parametrisierte Templates. Für InfraWhisper erstellte ich ein Helm Chart, mit dem ich den gesamten Stack mit einem Befehl deployen konnte:
helm upgrade --install infrawhisper ./deploy/helm/infrawhisper -n infrawhisper
Riesige Verbesserung gegenüber dem individuellen Anwenden von fünfzehn YAML-Dateien. Aber Helm Templates verwenden Go-Templating-Syntax, was seine eigene Lernkurve hat. Ich hatte jetzt drei Schichten zum Debuggen: meinen Anwendungscode, meine Kubernetes-Manifeste und meine Helm Templates, die diese Manifeste wrappen. Bei zwei Gelegenheiten produzierte ein Rendering-Fehler in einem Helm Template gültiges YAML, das das Falsche konfigurierte. Lustige Zeiten.
Ressourcenlimits sind anfangs ein Ratespiel. Wie viel Speicher braucht ein Kafka-Broker? Wie viel CPU sollte die AI-Engine bekommen? Ich hatte keine Ahnung. Mein erster Versuch gab jedem Service die gleichen Limits — 256Mi Speicher, 250m CPU — und die AI-Engine wurde sofort OOM-killed, weil ML-Inferenz mehr als 256 Megabyte RAM braucht. Offensichtlich.
Ich profilete schließlich jeden Service zuerst in Docker, notierte Spitzen-Speicher und CPU-Nutzung und setzte Limits auf ungefähr 2x Spitze mit etwas Spielraum. Nicht wissenschaftlich, aber es funktionierte. Kubernetes gibt dir kubectl top pods -n infrawhisper zum Überwachen der tatsächlichen Nutzung, sobald Dinge laufen, und ich passte Limits über ein paar Tage basierend auf echten Daten an.
Die Lernkurve ist front-loaded. Tag eins war brutal. Tag zwei war produktiv. Tag drei war schnell. Die Konzepte sind nicht inhärent schwierig — sie sind nur unvertraut. Sobald das mentale Modell klickt (und ich hoffe, das, was ich zuvor dargelegt habe, hilft), werden die Befehle zu logischen Erweiterungen dessen, was du zu tun versuchst. „Ich will drei Replicas" mappt direkt auf kubectl scale. „Ich will Logs sehen" mappt auf kubectl logs. Die Befehlsnamen sind die Konzepte.
Wenn ich das nochmal machen müsste, würde ich eine Sache ändern: Ich würde mit zwei oder drei Services anfangen statt neun. Alles auf einmal zu deployen bedeutete, dass wenn etwas kaputtging, der Fehler an jeder der neun Stellen sein konnte. Klein anfangen, den Workflow mit einer einfachen App und einer Datenbank verifizieren, dann Services inkrementell hinzufügen — das ist der Ansatz, den ich empfehlen würde.
Dies ist auch eine der Situationen, in denen Kubernetes nicht immer die richtige Antwort ist. Wenn deine Anwendung ein einzelner Container mit einer Datenbank ist, ist Docker Compose wahrscheinlich ausreichend. Der Overhead von Kubernetes zahlt sich nur aus, wenn du mehrere Services hast, die unabhängige Skalierung, selbstheilende Neustarts und Zero-Downtime-Deployments brauchen. Für InfraWhispers neun Services war diese Schwelle klar erreicht. Für ein Zwei-Container-Nebenprojekt vielleicht nicht.
Das InfraWhisper kubectl-Spickzettel
Nach drei Tagen des Deployens, Debuggens, Aktualisierens und gelegentlichen Fluchens auf YAML-Dateien sind dies die Befehle, nach denen ich ständig greife. Ich halte diese Liste in meinen Terminal-Notizen angeheftet.
Vor dem Deployment — verifiziere, dass dein Cluster bereit ist:
kubectl cluster-info
kubectl get nodes
kubectl get all -n infrawhisper
Deployen und Konfigurationen anwenden:
kubectl apply -f deployment.yaml
kubectl apply -f ./deploy/k8s/
helm upgrade --install infrawhisper ./deploy/helm/infrawhisper -n infrawhisper
Service-Image aktualisieren:
kubectl set image deployment/api-server api-server=ghcr.io/yourname/api-server:v2 -n infrawhisper
kubectl rollout status deployment/api-server -n infrawhisper
Prüfen, was läuft:
kubectl get pods -n infrawhisper
kubectl get pods -n infrawhisper -w
kubectl describe pod api-server-xxxx -n infrawhisper
kubectl get deployment api-server -n infrawhisper -o wide
Logs lesen und debuggen:
kubectl logs -n infrawhisper deployment/api-server
kubectl logs -n infrawhisper deployment/api-server -f
kubectl logs -n infrawhisper deployment/api-server --previous
Rollback wenn etwas schiefgeht:
kubectl rollout undo deployment/api-server -n infrawhisper
kubectl rollout history deployment/api-server -n infrawhisper
Hoch- oder runterskalieren:
kubectl scale deployment/api-server --replicas=3 -n infrawhisper
Neustart oder Löschen:
kubectl rollout restart deployment/api-server -n infrawhisper
kubectl delete pod api-server-xxxx -n infrawhisper
Der vollständige Build-to-Deploy-Zyklus:
docker build -t api-server:v2 .
docker push ghcr.io/yourname/api-server:v2
helm upgrade infrawhisper ./deploy/helm/infrawhisper -n infrawhisper
kubectl get pods -n infrawhisper
kubectl logs -n infrawhisper deployment/api-server -f
kubectl rollout undo deployment/api-server -n infrawhisper # if needed
Drucke das aus. Hefte es an. Du wirst jeden einzelnen dieser Befehle in deiner ersten Woche verwenden.
Was das für die Zukunft ändert
Vor drei Tagen fühlte sich die Idee, neun Services in einem orchestrierten Cluster laufen zu lassen, nach etwas an, das Monate an DevOps-Training und ein Team von Infrastruktur-Ingenieuren erfordert.
Tut es nicht. Es erfordert einen Mac, OrbStack, ein paar YAML-Dateien und die Bereitschaft, sich durch etwa acht Stunden Verwirrung zu kämpfen, bevor Dinge anfangen zu klicken. Die Tools sind gut genug geworden, dass ein Software-Engineer — kein DevOps-Spezialist, ein Software-Engineer — an einem langen Wochenende von null zu einem produktionsreifen lokalen Cluster kommen kann.
Was ich mitnehme, ist nicht nur ein funktionierendes Kubernetes-Setup. Es ist eine mentale Verschiebung. Ich denke jetzt anders über Anwendungen nach. Ich denke in Services und Pods und Deployments. Ich denke darüber nach, was passiert wenn Dinge fehlschlagen, nicht nur wenn sie funktionieren. Ich denke über Skalierung als einen Schieberegler nach, den ich anpassen kann, nicht als eine Krise, aus der ich mich heraus-engineeren muss.
Das InfraWhisper-Deployment läuft noch immer auf meinem lokalen OrbStack-Cluster während ich dies schreibe. Neun Pods, alle grün, alle gesund. Kafka verarbeitet Events, ClickHouse speichert Analysen, das Dashboard rendert Daten in Echtzeit. Und wenn einer von ihnen jetzt gerade crasht — bringt Kubernetes ihn zurück, bevor ich diesen Satz beende.
Wenn du Kubernetes aufgeschoben hast wie ich — es als Infrastrukturwissen für jemand anderen behandelt hast — hier ist dein Zeichen. Installiere heute Abend OrbStack. Deploye morgen einen Service. Füge übermorgen einen zweiten hinzu. Am dritten Tag fragst du dich, warum du so lange gewartet hast.
Was ist der eine Service in deinem Stack, der ständig crasht und niemand ihn neustartet? Fang dort an.
Häufig gestellte Fragen
Kann ich Kubernetes lokal auf dem Mac ohne Docker Desktop ausführen?
Ja. OrbStack bietet ein vollständiges Kubernetes-Cluster auf dem Mac ohne Docker Desktop. Es enthält sowohl Docker als auch Kubernetes, verwendet deutlich weniger Speicher (etwa 1,5-2 GB gegenüber 4-6 GB) und startet in Sekunden. Installiere von orbstack.dev und aktiviere Kubernetes in den Einstellungen.
Wie viele Services kann OrbStack auf einem lokalen Kubernetes-Cluster handhaben?
OrbStack handhabt bequem 10-15 Services auf einem M-Serien Mac mit 16 GB RAM. Ich lief 9 Services einschließlich Postgres, Redis, Kafka und ClickHouse gleichzeitig ohne Leistungsprobleme. Ressourcenlimits auf jedem Deployment verhindern, dass ein einzelner Service die anderen aushungert.
Was ist der Unterschied zwischen kubectl apply und helm upgrade?
kubectl apply -f deployt einzelne YAML-Manifest-Dateien direkt. helm upgrade --install deployt ein Helm Chart — ein Paket aus Template-Manifesten mit konfigurierbaren Werten. Helm ist besser für komplexe Multi-Service-Anwendungen; rohes kubectl funktioniert gut für einfache Deployments. Siehe den Implementierungsabschnitt oben für beide Ansätze.
Wie debugge ich einen Pod, der in CrashLoopBackOff feststeckt?
Führe kubectl describe pod [pod-name] -n [namespace] aus, um Events auf den Crash-Grund zu prüfen, dann kubectl logs -n [namespace] deployment/[name] --previous, um Logs der abgestürzten Instanz zu sehen. Das --previous-Flag ist entscheidend — es zeigt die Ausgabe des letzten Containers, nicht den aktuellen Neustartversuch.
Ist Kubernetes Overkill für kleine Projekte?
Für einen einzelnen Container mit einer Datenbank, ja — Docker Compose ist einfacher und ausreichend. Kubernetes zahlt sich aus, wenn du 3+ Services laufen lässt, die unabhängige Skalierung, selbstheilende Neustarts und Zero-Downtime-Deployments brauchen. Der Break-Even-Punkt liegt ungefähr dort, wo docker-compose beginnt, externe Tools für Zuverlässigkeit zu benötigen.
Let's Work Together
Looking to build AI systems, automate workflows, or scale your tech infrastructure? I'd love to help.
- Fiverr (custom builds & integrations): fiverr.com/s/EgxYmWD
- Portfolio: mejba.me
- Ramlit Limited (enterprise solutions): ramlit.com
- ColorPark (design & branding): colorpark.io
- xCyberSecurity (security services): xcybersecurity.io