

Open Swarm: das Multi-Agent-System, das ich täglich nutze
Die Aufforderung war zwölf Wörter lang. „Erstellen Sie mir ein komplettes Investoren-Pitch-Deck für ein AI-Markenmonitor-SaaS.“
Ich drückte in einem schwarzen Terminalfenster die Eingabetaste, ging in die Küche, kochte Kaffee und kam zurück. Etwa fünfzehn Minuten später befand sich in meinem Ausgabeordner ein vollständig gestaltetes PDF. Abdeckfolie. Problemstellung. Marktgröße mit einem echten TAM/SAM/SOM-Diagramm, das tatsächliche Zahlen aus einer Wettbewerbsanalyse entnommen hat. Eine Produktübersicht mit Mockups. Eine Go-to-Market-Folie. Preisstufen. Ein Gründerbereich. Eine abschließende Frage. Achtzehn Folien, gestaltet – nicht „Hier ist eine Markdown-Aufzählungsliste, Sie können diese selbst in Google Slides einfügen.“ Eine fertige Sache.
Als ich vor sechs Monaten zum ersten Mal dieselbe Eingabeaufforderung auf einem einzelnen Claude Code-Agenten ausführte, erhielt ich eine Markdown-Gliederung zurück. Eine gute Gliederung. Aber eine Übersicht. Die mentale Lücke zwischen „Ich schreibe dir den Inhalt des Decks“ und „Hier ist ein Deck“ ist die Lücke, auf die ich in der Open-Source-Welt seit zwei Jahren darauf gewartet habe, dass jemand sie schließt.
Das Ding, das es für mich geschlossen hat, heißt Open Swarm. Es handelt sich um ein Open-Source-Multiagentensystem von VRSEN – dem gleichen Team hinter Agency Der Slogan des Repos lautet „Claude Code für alles außer Codierung.“ Das ist richtig. Es wird auch etwas unterboten, was hier tatsächlich passiert.
Ich verwende es jetzt seit fast zwei Wochen in meiner täglichen Content-Pipeline. Lassen Sie mich Ihnen sagen, was funktioniert, was nicht und warum ich denke, dass dies derzeit das Interessanteste im Bereich der Open-Source-Agenten ist.
Was Open Swarm eigentlich ist
Wenn man die Marketingsprache weglässt, besteht Open Swarm aus drei übereinander gestapelten Dingen.
Ganz unten steht OpenCode – der Open-Source-Terminal-Coding-Agent AI, der rund 150.000 GitHub-Stars, über 850 Mitwirkende und eine installierte Basis von Millionen von Entwicklern hat. OpenCode selbst ist eine auf Bubble Tea basierende TUI, anbieterübergreifend und modellunabhängig. Wenn Sie Claude Code verwendet haben, sieht OpenCode wie sein Geschwister aus und fühlt sich auch so an. Gleiche Tastatur-First-Atmosphäre, gleiche dauerhafte Sitzung, gleiche „Ihr Projekt befindet sich im aktuellen Verzeichnis“-Philosophie.
In der Mitte befindet sich Agency Die Agentur Swarm arbeitet schon seit einiger Zeit mit den Kunden von VRSEN zusammen; Es ist der Motor, der die Agenten davon abhält, aneinander vorbeizureden.
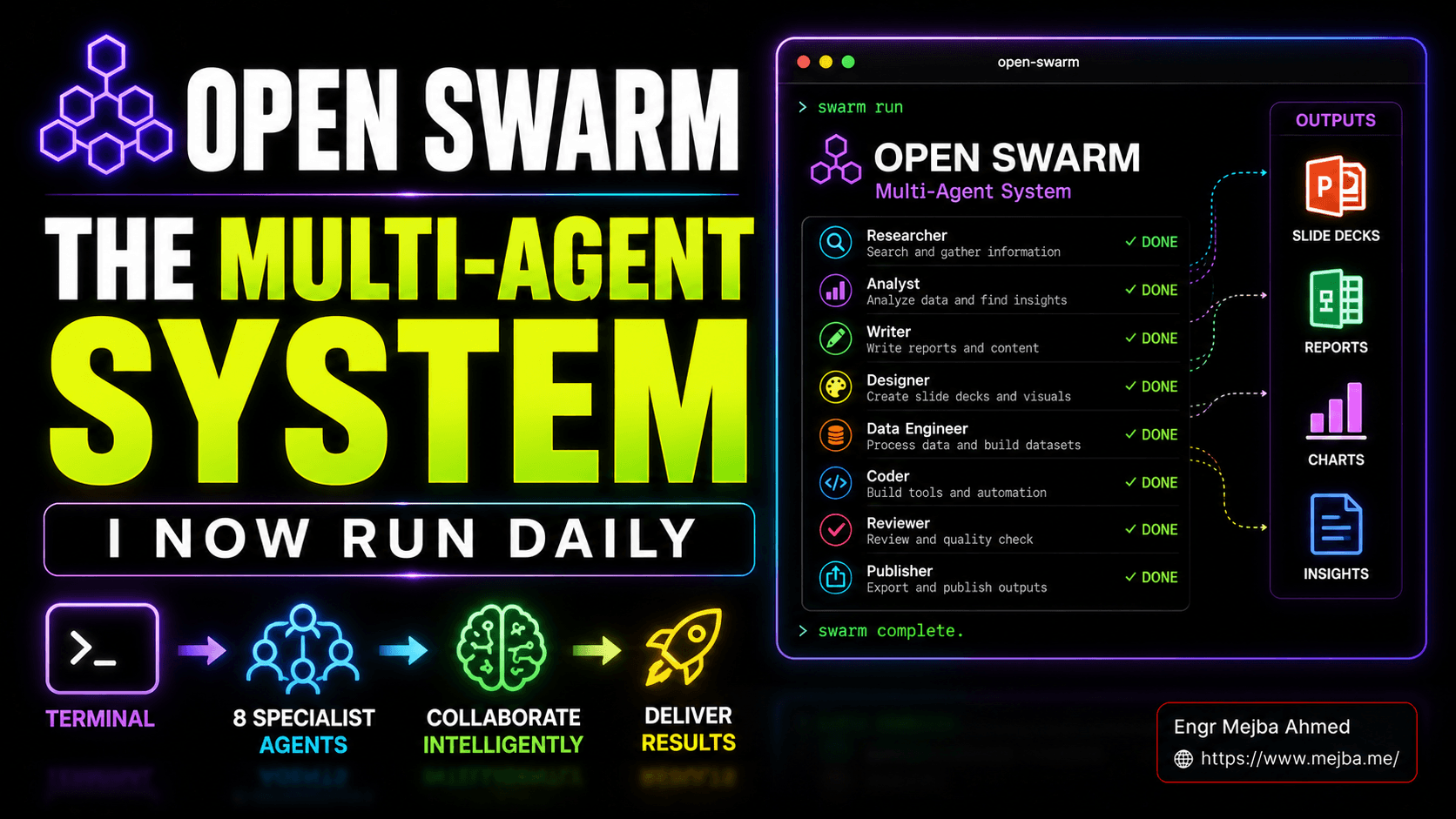
Darüber hinaus befindet sich Open Swarm selbst: ein kuratierter Satz von acht Spezialagenten, eigenwillige Eingabeaufforderungsdateien und ein Einrichtungsassistent für die erste Ausführung, der Sie in weniger als einer Minute von git clone zu einem funktionierenden Schwarm auf einer sauberen Maschine bringt. Die acht Spezialisten, wie sie sofort einsatzbereit sind:
- Orchestrator – der Chef. Nimmt Ihre Eingabeaufforderung entgegen, zerlegt sie in Unteraufgaben, weist die Arbeit Spezialisten zu, versucht es bei Fehlern erneut und gibt Ihnen die zusammengestellte Ausgabe zurück. 2. Generalagent – der Allround-Problemlöser für Aufgaben, die nicht für einen Spezialisten geeignet sind. Webzugriff, leichte Argumentation, Klebearbeit. 3. Slides-Agent – entwirft und rendert Präsentationsdecks. Die Schlagzeilenfunktion. Diagramme, Layouts, Markenkonsistenz, Exporte als PDF. 4. Deep Research Agent – der Long-Context-Leser. Erstellt Wettbewerbsanalysen, Marktberichte und Synthesen aus mehreren Quellen. Gibt echte Token für die Suche nach Primärquellen aus. 5. Datenanalyse-Agent – das Tabellenkalkulationsgehirn. Nimmt Rohzahlen oder Forschungsergebnisse auf und erstellt Diagramme, Tabellen und Zusammenfassungen. 6. Docs-Agent – schreibt strukturierte Dokumente. Berichte, Briefings, One-Pager, Verträge, interne Memos.
Markdown- und PDF-fähig. 7. Video-Agent – generiert eine kurze Videoausgabe. Noch früh, aber funktionsfähig für Produktmockups und Pitch-Animationen. 8. Bildagent – generiert Bilder für Folien, Modelle und Markenwerte. Verbindet sich mit Bildgenerierungsanbietern.
Das ist die Standardverteilung. Nichts davon ist fest codiert. Jeder Spezialist ist nur eine Eingabeaufforderungsdatei plus eine Werkzeugliste plus eine Modellzuweisung, und Sie können jeden von ihnen bearbeiten, forken oder ersetzen – das ist der Teil, über den ich später in diesem Beitrag ausführlich sprechen möchte, denn hier sieht Open Swarm weniger wie ein Produkt als vielmehr wie eine Plattform aus.
Das Repo befindet sich unter github.com/VRSEN/OpenSwarm. Der Setup-Assistent kümmert sich um Authentifizierung, Abhängigkeiten und Konfiguration. Klonen Sie, führen Sie den Assistenten aus, geben Sie Ihre API-Schlüssel ein, schon kann es losgehen.
Warum Spezialisierung einen großen Agenten schlägt
Ich habe zwei Jahre damit verbracht, Menschen dabei zuzusehen, wie sie versuchen, einen einzigen generalistischen Agenten dazu zu bringen, alles zu erledigen. Ich habe selbst Versionen davon gebaut. Das Muster schlägt jedes Mal auf die gleiche Weise fehl, und zwar aus strukturellen Gründen, die mit einer intelligenteren Eingabeaufforderung nicht behoben werden können.
Ein einzelner Agent, der Recherche, Analyse, Schreiben, Design und Rendering durchführt, sammelt den Kontext aller fünf Jobs in einem Fenster. Wenn es Folie drei schreibt, trägt es den rohen HTML-Code aus dem Rechercheschritt, die fehlgeschlagenen Diagrammversuche aus dem Datenschritt und den halbbearbeiteten Markdown aus dem Dokumentenschritt mit sich herum. Kontextfenster sind endlich. Selbst mit 1 Mio. Token Opus möchten Sie eigentlich nicht eine Million Token veralteten Mülls im Umfang haben, wenn Sie das Modell auffordern, eine strenge visuelle Entscheidung über eine Diagrammachse zu treffen. Halluzinationen nehmen mit Kontextgeräuschen zu. Die Ausgabequalität nimmt ab.
Spezialisten beheben dieses Problem, indem sie den Geltungsbereich durchsetzen. Der Forschungsagent erhält ein leeres Fenster, das nur die Forschungsaufgabe enthält. Wenn es fertig ist, übergibt es eine saubere Zusammenfassung an den Orchestrator und bricht ab. Der Datenanalyst erhält ein sauberes Fenster, das nur die Zusammenfassung und seine eigenen Tools enthält. Wenn der Slides-Agent das Ergebnis abholt, arbeitet er mit einem engen, kuratierten Kontext – und nicht mit einer Suppe aus sieben vorherigen Aufgaben.
Darauf ging es in dem Beitrag zur Agentenschwarmarchitektur, den ich im März geschrieben habe, und es ist genau das Muster, das die eigenen gegabelten Unteragenten in Claude Code von Anthropic auf Plattformebene implementiert haben. Open Swarm ist die gleiche Idee, die auf nicht-codierende Arbeiten verallgemeinert wird.
Es gibt einen zweiten Vorteil, der wichtiger ist, als den Menschen bewusst ist: Jeder Spezialist verfügt über sein eigenes Toolset. Der Rechercheagent verfügt über Websuche, Webbrowsing, RSS-Reader und Dokumentenabrufer. Der Datenanalyst verfügt über Codeausführungs- und Diagrammbibliotheken. Der Slides-Agent verfügt über Rendering-Tools. Ein einziger Generalist muss jedes Werkzeug in einer Eingabeaufforderung verwalten – das bedeutet mehr Entscheidungen darüber, welches Werkzeug verwendet werden soll, was mehr Fehler bei der Werkzeugauswahl bedeutet, was wiederum langsamere Abläufe und eine schlechtere Ausgabe bedeutet. Spezialisten machen die Tool-Auswahl zu einer Architekturentscheidung und nicht zu einer Laufzeitentscheidung.
Der dritte Vorteil ist dumm, aber real: Sie können sie parallel ausführen. Recherche und Bilderzeugung sind nicht voneinander abhängig, sodass der Orchestrator sie gleichzeitig starten kann. Bei einer Aufgabe mit mehreren Aufgaben verkürzt die Parallelität die Arbeitszeit um einen bedeutenden Teil.
Das Kopf-an-Kopf-Rennen: Open Swarm vs. Claude Code vs. Open Claw
Ich gab drei verschiedenen Setups die gleiche Eingabeaufforderung und schaute mir an, was zurückkam. Die Aufforderung: „Erstellen Sie mir ein vollständiges Pitch-Deck für Investoren für einen AI-Markenmonitor für SaaS-Zielagenturen. Beziehen Sie Marktgröße, Konkurrenzanalyse, Produktübersicht, Preisstufen, GTM und eine 12-Monats-Roadmap ein.“ Wo möglich, gleiche Modellauswahl (Sonnet 4.6 allgemein für die Arbeitsagenten, Opus 4.7 für jeden Orchestrierungsschritt, der dies unterstützt).
Claude Code, Einzelagent. Ausgabe: ein Markdown-Dokument mit 4.400 Wörtern. Hervorragender Inhalt – die Modelle von Anthropic sind beim strukturierten Schreiben in Langform unschlagbar – aber es ist ein Dokument, kein Deck. Abschnitte mit der Bezeichnung „Folie 1: Cover“, „Folie 2: Problem“ usw. Um daraus etwas zu machen, das ich einem Investor tatsächlich zeigen würde, müsste ich mehr als 90 Minuten in Figma oder Slides damit verbringen, Inhalte zu verschieben, Layouts zu entwerfen und Diagramme zu erstellen. Zeitersparnis gegenüber dem Schreiben von Grund auf: vielleicht 60–70 %. Zeit bis zum fertigen, vorzeigbaren Ergebnis: immer noch mehr als zwei Stunden.
Open Claw (die Agentenautomatisierungsplattform, die ich in meinem Vergleich von Open Claw vs. Claude Code behandelt habe). Ausgabe: ein Google-Slides-Deck per Browser-Automatisierung. Echte Folien, echte Layouts, aber die Designqualität war die generische blau-weiße Vorlage, die man aus jeder „AI hat das für mich erstellt“-Demo kennt. Diagramme waren Platzhalterbalken. Der Inhalt war etwa 80 % so gut wie bei Claude Code, weil der Workflow mehr Agentensprünge und mehr Chancen für Kontextdrift enthielt. Zeit bis zum fertigen Deck: ungefähr 40 Minuten, größtenteils automatisiert.
Open Swarm. Ausgabe: ein 18-Folien-PDF, entworfen, mit echten Diagrammen aus echten Forschungsdaten, markenkonsistenter Typografie, handabgestimmten Layouts pro Folie. Plus – und das überraschte mich – ein separates einseitiges Zusammenfassungsdokument, das vom Dokumentenagenten parallel zum Deck erstellt wurde, sowie Mockup-Bilder vom Bildagenten, die der Folienagent in die Produktübersichtsfolie eingebettet hatte. Verstrichene Zeit: 17 Minuten. Token-Kosten: Sonnet/Opus-Anrufe im Wert von ca. 4,20 $ über alle acht Agenten hinweg. Qualität der fertigen Ausgabe: kommt der Aussage „Ich würde es einem Investor zeigen, ohne es erneut zu bearbeiten“ am nächsten, die ich von jedem offenen Agentensystem gesehen habe.
Das Interessante daran ist nicht, dass Open Swarm gewonnen hat. Der interessante Teil ist, wie es gewonnen hat. Es hat nicht gewonnen, weil das zugrunde liegende Modell intelligenter war – dieselben Modelle. Es hat gewonnen, weil die Architektur jeden Modellaufruf in einen Kontext gestellt hat, in dem sie ihre beste Arbeit leisten konnte, und dann die Teile zusammengesetzt hat. Das ist ein technisches Ergebnis, kein Modellergebnis. Und die technischen Ergebnisse verstärken sich.
Ein echter Lauf, Schritt für Schritt
Lassen Sie mich erklären, was tatsächlich passiert, wenn Sie eine Eingabeaufforderung bei Open Swarm auslösen. Als Beispiel verwende ich den Pitch-Deck-Durchlauf für Investoren von oben, da die Spur am anschaulichsten ist.
T+0s – Eingabeaufforderung kommt beim Orchestrator an. Der Orchestrator-Agent liest die Eingabeaufforderung und zerlegt sie. Intern wird ein Aufgabendiagramm erstellt: Recherchieren Sie den AI-Markenüberwachungsmarkt, identifizieren Sie 4–6 Wettbewerber, erstellen Sie ein TAM/SAM/SOM-Modell, entwerfen Sie eine Produktpositionierung, entwerfen Sie 18 Folien mit konsistentem Branding, erstellen Sie eine einseitige Zusammenfassung der Geschäftsleitung, erstellen Sie ein Produktmodellbild. Das Aufgabendiagramm wird im Arbeitsspeicher des Orchestrators gespeichert und nicht auf die Festplatte geschrieben. Sie können jedoch ein Flag umschalten, um es zum Debuggen zu sichern.
T+30s – Forschungsagent feuert. Deep Research Agent erhält die Unteraufgabe Wettbewerbsanalyse. Es führt mehrstufige Websuchen durch und ruft Seiten von G2, Crunchbase, ProductHunt und den eigenen Marketingseiten der Wettbewerber ab. Es erstellt ein strukturiertes Wettbewerbsraster im Markdown – Name, Positionierung, Preisgestaltung, Zielsegment, Schwächen. Ungefähr 90 Sekunden Wanduhr, ungefähr 200.000 Token Modellzeit. Die Ausgabe wird als saubere Zusammenfassung an den Orchestrator zurückgegeben. Der Orchestrator entfernt den rohen, gescrapten HTML-Code, bevor er etwas nachgelagertes weitergibt.
T+2m – Recherche- und Image-Agenten laufen parallel. Der Orchestrator löst den Deep-Research-Agenten erneut für eine separate Aufgabe (TAM/SAM/SOM Marktgrößenbestimmung) gleichzeitig mit dem Image-Agenten (Produktmodell eines Dashboards) aus. Parallelität ist hier die kostengünstige, aber echte Zeitersparnis – diese beiden Aufgaben haben keinen gemeinsamen Kontext.
T+4 Mio. – Datenanalyseagent übernimmt die Forschungsergebnisse. Die Marktgrößenforschung kommt als Rohdaten der Branche und Hinweise zur Methodik zurück. Der Datenagent nimmt es auf, führt Python in einem Sandbox-Code-Interpreter aus und generiert ein TAM/SAM/SOM-Diagramm mit den richtigen Achsen und Beschriftungen sowie ein Preisvergleichsdiagramm der Konkurrenz. Die Diagramme werden in einem temporären Verzeichnis gespeichert, aus dem der Folien-Agent liest.
T+7m – Folienagent startet den Entwurfsdurchlauf. Dies ist der Agent, der den größten Teil der Arbeit erledigt. Es liest die Forschungszusammenfassungen, die Diagramme und die Markenanforderungen (es fragt den Orchestrator, ob er etwas Unklares benötigt). Es generiert eine Deck-Spezifikation – 18 Folien, jede mit einem Layouttyp, Inhalt, Bildreferenzen, Diagrammreferenzen. Dann wird gerendert. Auf der anderen Seite: ein echtes PDF.
T+12m – Docs Agent schreibt den One-Pager parallel zum Rendern der Folien. Ruft die gleiche Recherche ab, verdichtet sie zu einer Zusammenfassung mit 600 Wörtern und exportiert sie als PDF. Unabhängig vom Folienagenten, da die Eingabedaten gleich sind und die Ausgaben nicht koordiniert werden müssen.
T+17m – Orchestrator stellt zusammen, validiert, gibt zurück. Abschließende Prüfung: Sind alle Ergebnisse vorhanden, sind die Dateigrößen angemessen, hat ein Agent einen kritischen Fehler protokolliert, wurde der Lauf innerhalb seines Wiederholungsbudgets abgeschlossen. Dann kehrt die Kontrolle zum Terminal zurück und Sie sehen die Dateipfade in Ihrem Ausgabeordner.
Was Sie bei diesem Lauf nicht sehen, ist die Wiederholungsschleife des Orchestrators. Der erste Versuch einer Wettbewerbsanalyse scheiterte – eine der Konkurrenzseiten meldete eine Cloudflare-Challenge zurück, die den Scraper zerstörte. Der Orchestrator erkannte den Fehler, versuchte es erneut mit einer anderen Scraping-Strategie und belästigte den Menschen (mich) nie damit. Das ist eine kleine Sache, die sehr wichtig ist. Ein Single-Agent-Setup schlägt entweder vor Ihren Augen fehl oder verbirgt den Fehler vollständig. Ein Schwarm mit einem echten Orchestrator behandelt Fehler als Routing-Problem.
Anpassen Ihres eigenen Swarm
Dies ist der Teil von Open Swarm, der meiner Meinung nach in den meisten Berichten, die ich gesehen habe, unterverkauft ist. Die Standardverteilung mit acht Agenten ist ein Ausgangspunkt, keine Obergrenze. Jeder Spezialist verfügt über eine Eingabeaufforderungsdatei, eine Werkzeugliste und eine Modellzuordnung. Sie können das Repo forken und alles ändern.
Konkret sieht die Struktur so aus. Jeder Agent existiert als Verzeichnis mit einem prompt.md (Systemeingabeaufforderung), einem tools.yaml (der Toolliste mit Berechtigungen) und einem Konfigurationsblock in agents.md (Modellauswahl, Temperatur, Wiederholungsrichtlinie, Bindung des übergeordneten Orchestrators). Das Hinzufügen eines neuen Agenten ist eigentlich eine Aufgabe zum Kopieren, Einfügen und Bearbeiten, nicht eine Aufgabe, bei der man sich zuerst mit dem Framework vertraut machen muss. Wenn Sie jemals eine Claude Code-Subagentendefinition geschrieben haben, handelt es sich hierbei um dasselbe mentale Modell mit einem anderen Dateinamen.
Hier ist die von mir gebaute, die meiner Meinung nach am besten zum Gehäuse passt. Ich habe Open Swarm geforkt und daraus einen SEO-Schwarm gemacht – einen anderen Spezialistenmix, der für die Art von Arbeit optimiert ist, die ich jede Woche erledige. Die Standardacht wurde zu:
- Orchestrator – unverändert, immer noch der Boss. - Keyword-Planer – ersetzt „Generalvertreter“. Ruft Suchkonsolenabfragen ab, führt die Absichtsklassifizierung durch und erstellt Keyword-Cluster. Toolliste: GSC API-Client, ein kleines benutzerdefiniertes Python-Tool für die Clusterbewertung. - Kurzbericht – ersetzt durch „Folienagent“. Nimmt einen Ziel-Keyword-Cluster und erstellt ein strukturiertes Inhaltsbriefing: SERP-Analyse, Mitbewerber-Winkelkarte, empfohlene Gliederung, Zielwortanzahl, Vorschläge für interne Links. - Deep Research Agent – beibehalten, aber mit einem kleineren Toolset und einem stärkeren Fokus auf Branchenforschung statt allgemeiner Forschung. - Datenagent – ersetzt durch einen GA4/GSC-Analysespezialisten. Ruft Leistungsdaten ab, erstellt Dashboards und markiert verfallende Seiten. - Docs-Agent – beibehalten.
Schreibt jetzt den eigentlichen Blog-Beitrag, sobald das Briefing genehmigt wurde. - Crawler-Agent – ersetzt „Video-Agent“. Führt einen einfachen technischen SEO-Crawling auf einer Zieldomäne durch – Schema-Markup-Prüfungen, interne Linkintegrität, Statuscode-Sweep. - Bildagent – wird beibehalten und für Blog-Hero-Bilder verwendet.
Der Forking-Vorgang dauerte einen Nachmittag. Der größte eintägige Produktivitätssprung, den meine Pipeline seit Monaten erlebt hat. Die Überschrift, die Sie aus dieser Anekdote ziehen sollten, ist nicht, dass ich einen SEO-Schwarm aufgebaut habe. Es liegt daran, dass die Anpassungsoberfläche so flach ist, dass „Bau mir einen Schwarm für genau meinen Job“ ein Samstagsprojekt ist und nicht ein Viertel der Ingenieursarbeit. Jeder, dessen Arbeit mehrere diskrete Teilaufgaben umfasst, bei denen ein Generalist Fehler macht, kann dies tun.
Der andere erwähnenswerte Punkt: VRSEN hat einen „Agent Builder Agent“ angedeutet – einen Agenten, der eine Beschreibung eines Workflows in natürlicher Sprache übernimmt („Ich möchte einen Schwarm, der die Konkurrenz für SaaS-Startups überwacht“) und den Spezialistenmix für Sie zusammenstellt. Das ist zum Zeitpunkt, als ich dies schreibe, noch in der Entwicklung. Wenn es landet, sinkt die Anpassungshürde von „Samstagsprojekt“ auf „fünf Minuten“. Das ändert die Mathematik darüber, wer dies nutzen kann.
Wo es neben Claude Code in meinen Workflow passt
Ich möchte zu diesem Teil ehrlich sein, denn die Formulierung „X tötet Y“ ist faul und normalerweise falsch. Open Swarm hat Claude Code in meinem Stack nicht ersetzt. Es läuft daneben.
Claude Code ist weiterhin der Ort, an dem meine Coding-Arbeit stattfindet. Refactoring, Agenten bauen, Debugging, Infrastrukturarbeit – es ist das richtige Tool, wenn das Ergebnis eine Codeänderung ist. Die Modelle von Anthropic haben bei langfristigem Code-Reasoning weiterhin einen Vorsprung, den das offene Ökosystem noch nicht eingeholt hat. Die forked sub-agents von Claude Code und die jüngste Verdopplung der Rate Limits nach dem SpaceX-Compute-Deal machen es für produktive Engineering-Arbeit nützlicher denn je.
Open Swarm ist das richtige Werkzeug für „das Ergebnis ist etwas anderes als Code.“ Decks. Berichte. Modelle. Diagramme. Slip. Die Art von Arbeit, die früher eine Kette von „Claude hat mir eine Gliederung geschrieben, dann habe ich sie in Figma entworfen, dann habe ich Diagramme in Numbers erstellt, dann habe ich sie als PDF exportiert“ bestand und jetzt in einer Eingabeaufforderung und einer Terminalsitzung zusammenfällt.
Der Rest des Stacks: Ich verwende immer noch Open Claw für visuelle Workflows, wenn das menschliche Überwachungsmuster wichtig ist – Kanban-artiges Board, menschliche Genehmigungstore zwischen den Phasen, Sichtbarkeit für Stakeholder. Das ist die falsche Lösung für einen ergebnisorientierten Run mit dem Kopf nach unten; Es ist die richtige Lösung für ein mehrtägiges funktionsübergreifendes Projekt. Und Codex bleibt bei den wenigen spezifischen Aufgaben in der Ecke, bei denen der Argumentationsstil von GPT den von Claude übertrifft.
Drei Terminal-First-Tools, ein mentales Modell, drei bewusste Entscheidungen darüber, wer für welchen Job kündigt. Der gemeinsame Thread besteht darin, dass alle drei lokale Dateien sind, Terminal-First und mehrstündige autonome Ausführungen tolerieren. Keines davon sind SaaS-Dashboards, auf die ich aufpassen muss. Diese Terminal-First-Ausrichtung ist für mich immer wieder die unterschätzte Sache. Wenn Sie in letzter Zeit eine UI-gesteuerte Agentenplattform verwendet haben, wissen Sie, was ich meine – der ständige Kontextwechsel zwischen Ihrem Editor und der Weboberfläche des Agenten ist eine schleppende Reibung. Open Swarm und seine Kollegen beseitigen dies. Der Agent läuft dort, wo ich bereits wohne.
Was kommt
Es lohnt sich, auf einige Dinge auf der Open Swarm-Roadmap aufmerksam zu machen, da sie Ihre Möglichkeiten noch vor Jahresende verändern.
Engere Integrationen mit benachbarten Terminalagenten. In den Community-Kanälen von VRSEN wird über Open Swarm + Codex + Das ist der fehlende Teil für „Ich möchte eine einzige Aufforderung zum Entwerfen und Versenden einer kleinen SaaS-Funktion.“ Heute machen Sie das als zwei Eingabeaufforderungen in zwei Terminals. Morgen könnte es einer sein.
Open Claw-Integration. „Alle Ihre Agenten an einem Ort“ ist die Sprache, die VRSEN verwendet hat. In der Praxis würde dies bedeuten, dass die terminal-native Architektur von Die richtige Mischung, wenn sie tatsächlich versendet wird.
Der Agent Builder Agent. Ich habe es oben erwähnt. Der größte Beschleuniger für die Akzeptanz, wenn es gut ankommt. Die Messlatte liegt hoch – die meisten „Build me a agent from natural language“-Demos, die ich gesehen habe, produzieren Agenten, die technisch korrekt und praktisch nutzlos sind. Wenn VRSEN einen ausliefern kann, der funktionierende Schwärme produziert, bricht die Anpassungsbarriere zusammen.
Bessere Video- und Bildspezialisten. Dies ist der Teil der Standardverteilung, der eindeutig der jüngste ist. Folien, Dokumente, Recherchen, Daten – diese Agenten sind ausgereift. Der Videoagent funktioniert, erzeugt jedoch eine Ausgabe, die wie ein generatives Videotool aus dem Jahr 2024 und nicht wie ein Tool aus dem Jahr 2026 aussieht. Der Bildagent ist in Ordnung, aber nicht Higgsfield-fein. Ich erwarte, dass sich beide in den nächsten zwei Quartalen aggressiv weiterentwickeln, da VRSEN bessere Tool-Integrationen liefert.
Speicher und Lernen über Läufe hinweg. Im Moment ist jeder Lauf größtenteils frisch. In der Agentur Swarm ist die Infrastruktur für einbettungsbasiertes Langzeitgedächtnis vorhanden, und es gibt Anzeichen dafür, dass sie auch in Open Swarm eintrifft. Die Version davon, bei der sich mein SEO-Schwarm merkt, welche Keyword-Cluster erfolgreich waren, und zukünftige Briefings entsprechend anpasst, ist die Version, für die ich echtes Geld bezahlen würde.
Ehrliche Einschränkungen
Ich werde diesen Teil so erledigen, wie ich möchte, dass ihn jemand für mich erledigt – direkt, ohne Absicherung.
„Keine Codierung erforderlich“ ist nicht unbedingt wahr. Das Versprechen besteht darin, dass Sie keinen Code schreiben, um Open Swarm auszuführen. Das ist richtig. Das Versprechen ist nicht, dass Sie niemals eine Datei berühren. Um den Schwarm sinnvoll anzupassen, bearbeiten Sie Eingabeaufforderungsdateien. Um ein Tool hinzuzufügen, bearbeiten Sie eine YAML-Datei. Um einen sich schlecht benehmenden Spezialisten zu debuggen, lesen Sie dessen Eingabeaufforderung und finden heraus, wo die Anweisungen falsch sind. Wenn Ihnen der Ausdruck „eine YAML-Konfiguration bearbeiten“ Angst macht, wird sich die Anpassungsebene von Open Swarm wie Codierung anfühlen, obwohl dies nicht der Fall ist.
Die Ausgabequalität hängt von der Modellauswahl ab. Das klingt offensichtlich. Es ist wichtiger als es klingt. Führen Sie Open Swarm auf günstigen Modellen aus und Sie erhalten eine günstige Ausgabe. Führen Sie es auf Sonnet 4.6 auf den Worker-Agenten und Opus 4.7 auf dem Orchestrator aus und Sie erhalten die oben beschriebenen Ergebnisse. Die Schwarmarchitektur verstärkt die Qualität, die Ihnen die zugrunde liegenden Modelle bieten – im Guten wie im Schlechten. Erwarten Sie von 0,30-Dollar-pro-Run-Modellen keine Ausgabe von 0,30 $ pro Lauf.
Mehrstündige autonome Läufe kosten echte Token. Der von mir beschriebene Investor-Pitch-Lauf kostete etwa 4,20 $. Für einmalige Leistungen ist das in Ordnung. Wenn Sie zwanzig davon pro Tag in die Warteschlange stellen, sind das 84 $/day, etwa 2.500 $ pro Monat, allein für die Agentenläufe. Das ist immer noch günstiger als die Beauftragung eines Designers oder Analysten, aber es ist nicht kostenlos und kann sich an Sie heranschleichen. Legen Sie vom ersten Tag an in der Konfiguration eine Kostenobergrenze pro Lauf fest. Der Schwarm respektiert es.
Der Folienagent ist die Überschrift. Bild und Video sind noch früh. Ich komme immer wieder darauf zurück, weil es für die Erwartungshaltung wichtig ist. Wenn Sie aufgrund der Deck-Ausgabe auf Open Swarm verkauft werden, erhalten Sie genau das, wofür Sie sich angemeldet haben. Wenn Sie wegen der Videoausgabe davon überzeugt sind, dämpfen Sie die Erwartungen etwas. Der Videoagent funktioniert – ich habe ihn für Produktmodellanimationen verwendet –, aber es ist der Teil der Standardverteilung, der am meisten Arbeit erfordert. In sechs Monaten würde ich einen anderen Bericht dazu erwarten.
Anbieterbindung ist ein Risiko, über das Sie nachdenken sollten. Open Swarm läuft auf LiteLLM, was bedeutet, dass Anbieterflexibilität technisch verfügbar ist. In der Praxis sind die Eingabeaufforderungsdateien auf die spezifischen Besonderheiten von Sonnet/Opus abgestimmt, und der Wechsel zu einem anderen Anbieter verschlechtert die Ausgabequalität. Wenn Ihre Sorge lautet: „Was passiert, wenn Anthropic die Preise erhöht oder Funktionen einstellt?“, schützt Sie Open Swarm nicht vollständig davor. Es gibt Ihnen Migrationsoptionalität, keine Migrationsparität.
Lange Läufe können Probleme verbergen. Wenn ein Spezialist in Schritt drei eines 15-minütigen Laufs einen stillen Fehler macht, bemerkt der Orchestrator ihn normalerweise nicht. Sie sehen das Endergebnis, es sieht plausibel aus, Sie versenden es. Eine Woche später stellen Sie fest, dass in der Wettbewerbsanalyse ein Konkurrent aufgeführt ist, der nicht existiert, weil der Forschungsagent halluziniert hat und ihn nichts weiter unten entdeckt hat. Dies gilt für alle Multiagentensysteme, und Open Swarm ist nicht schlechter als seine Mitbewerber, aber der Abstand zwischen „Ich habe den Lauf gestartet“ und „Ich sehe die Ausgabe“ macht die Überprüfung langsamer, als sie sein sollte. Machen Sie es sich zur Gewohnheit, Zitate in jedem Dokument, das Sie an einen echten Menschen senden, stichprobenartig zu überprüfen.
Wer sollte es dieses Wochenende versuchen?
Wenn Sie ein Gründer sind, der Investorendecks von Hand geschrieben hat und ein Guthaben von API in Höhe von 50 $ übrig hat, installieren Sie Open Swarm noch heute Abend. Führen Sie die Investoren-Pitch-Eingabeaufforderung gegen Ihr eigenes Unternehmen durch. Das erste Deck, das Sie zurückerhalten, wird nicht Ihr endgültiges Deck sein – aber der zweite Entwurf wird, nachdem Sie ihn mit Ihren tatsächlichen Zahlen gefüttert und die Positionierung verschärft haben, neunzig Prozent des Weges dorthin zurückgelegt haben, und zwar in einem Bruchteil der Zeit, die für die handschriftliche Erstellung erforderlich wäre.
Wenn Sie ein Forscher sind, der Berichte für Kunden erstellt, ist die Kombination aus tiefgreifender Forschung und Dokumenten der Anwendungsfall, für den der Schwarm entwickelt wurde. Eine gute Regel: Jedes Ergebnis, für das Sie derzeit einen ganzen Tag „Recherche, dann Diagramm, dann Schreiben, dann Format“ benötigen, ist ein Kandidat für ein Experiment am Samstagnachmittag.
Wenn Sie wie ich ein Vermarkter oder SEO-Betreiber sind, ist es der richtige Schritt, die Standardverteilung zu forken und Ihren eigenen Schwarm aufzubauen. Die acht Standardspezialisten sind auf allgemeine Geschäftsaufgaben ausgerichtet. Spezialisieren Sie sie auf Ihren Job und der Produktivitätssprung verändert, was Sie Ihren Kunden in Rechnung stellen können.
Wenn Sie ein Entwickler sind, der sich mit den Agententeams von Claude Code auskennt und dasselbe Modell auf nicht programmierende Arbeiten ausweiten möchte, dann ist dies genau das Richtige. Das mentale Modell ist identisch. Die Reibung ist gering.
Und wenn Sie jemand sind, der mit Einzelagenten-Obergrenzen frustriert ist – Läufe, die an Kontextgrenzen stoßen, bei Länge drei halluzinieren, den Faden bei mehrstufigen Aufgaben verlieren – dann ist dies die Architektur, auf die Sie gewartet haben, bis jemand sie als sauberes Open-Source-Grundelement ausliefert. Das Orchestrator-plus-Spezialisten-Muster ist als Konzept nicht neu. Das Muster, das als etwas geliefert wird, das Sie klonen und in 60 Sekunden ausführen können, ist neu.
Die einzeilige Installation ist ein git clone von github.com/VRSEN/OpenSwarm, gefolgt vom Setup-Assistenten. Von einer sauberen Maschine zum funktionierenden Schwarm: weniger als fünf Minuten. Die Kosten für den Versuch: gering. Der Vorteil, wenn es hängenbleibt: eine dauerhafte Änderung der Menge Ihrer Arbeit, die Sie einer Maschine übergeben können.
Ich saß zwei Wochen lang auf der Verdoppelung des Claude Code-Ratenlimits, bevor ich darüber schrieb, weil ich wissen wollte, ob sich dadurch tatsächlich etwas änderte. Ich schreibe drei Wochen nach der ersten Installation über Open Swarm, weil die Antwort früher eintraf. Es ist das erste Stück Open-Source-Agenten-Infrastruktur, das ich im Jahr 2026 installiert habe und das sich einen festen Platz in meinem Workflow verdient hat, ohne dass ich mir selbst davon überzeugen muss, dass es einen verdient. Die Ergebnisse, die es produziert, sind real. Die Architektur stimmt. Die Anpassungsgeschichte ist so oberflächlich, dass Sie sie über ein Wochenende zu Ihrem eigenen machen können.
Das Terminal hat bereits den AI-Agent-UX-Krieg gewonnen. Open Swarm ist das Interessanteste, was innerhalb dieses Terminals passiert, bei dem es nicht um das Schreiben von Code geht.
Häufig gestellte Fragen
Ist die Nutzung von Open Swarm kostenlos?
Open Swarm selbst ist kostenlos und Open Source im VRSEN-Repository unter github.com. Ein typischer vollständig lieferbarer Lauf kostet ein paar Dollar an Modellaufrufen.
Was ist der Unterschied zwischen Open Swarm und Agency Swarm?
Agency Swarm ist das zugrunde liegende Multi-Agent-Orchestrierungs-Framework – die Engine. Open Swarm ist eine kuratierte, sofort einsatzbereite Distribution, die darauf aufbaut: acht vorkonfigurierte Spezialagenten, ein Einrichtungsassistent, eigenwillige Eingabeaufforderungen, Terminal-First-UX. Wenn Agency Swarm das Framework ist, ist Open Swarm das Starterkit mit Batterien.
Muss ich wissen, wie man Code schreibt, um Open Swarm auszuführen?
Sie müssen keinen Code schreiben, um den Standardschwarm auszuführen – Klonen, Setup-Assistent, Eingabeaufforderung, fertig. Um Spezialisten anzupassen oder Ihren eigenen Schwarm aufzubauen, bearbeiten Sie Eingabeaufforderungsdateien (Markdown) und Toolkonfiguration (YAML). Dabei handelt es sich um Textbearbeitung, nicht um Codierung, aber wenn sich „Bearbeiten einer YAML-Datei“ für Sie wie Codieren anfühlt, müssen Sie mit einer kleinen Lernkurve auf der Anpassungsebene rechnen.
Wie schneidet Open Swarm im Vergleich zu Claude Code-Subagenten ab?
Die Subagenten von Claude Code basieren auf dem gleichen Architekturmuster (Orchestrator plus Spezialisten mit separaten Kontextfenstern), das auf die Codierungsarbeit angewendet wird. Open Swarm wendet es auf alles außer Codierung an – Foliendecks, Forschungsberichte, Diagramme, Dokumente, Bilder. Es handelt sich um ergänzende Tools, die Sie vernünftigerweise Seite an Seite und nicht mit Konkurrenten betreiben sollten.
Welche Modelle funktionieren am besten mit Open Swarm?
In meinen Tests lieferten Sonnet 4.6 auf den Worker-Agents und Opus 4.7 auf dem Orchestrator die qualitativ hochwertigste Ausgabe. Das Framework ist über LiteLLM anbieterunabhängig, aber die Standard-Eingabeaufforderungsdateien sind auf die Modelle von
Lasst uns zusammenarbeiten
Möchten Sie AI-Systeme aufbauen, Arbeitsabläufe automatisieren oder Ihre technische Infrastruktur skalieren? Ich würde gerne helfen.
- Fiverr (benutzerdefinierte Builds und Integrationen): fiverr.com/s/EgxYmWD
- Portfolio: mejba.me
- Ramlit Limited (Unternehmenslösungen): ramlit.com
- ColorPark (Design & Branding): colorpark.io
- xCyberSecurity (Sicherheitsdienste): xcybersecurity.io



