

Open Swarm : le système multi-agents que j'utilise chaque jour
L’invite comptait douze mots. "Construisez-moi un pitch deck complet pour les investisseurs pour un moniteur SaaS de marque AI."
J'ai appuyé sur Entrée à l'intérieur d'une fenêtre noire du terminal, je me suis dirigé vers la cuisine, j'ai préparé du café et je suis revenu. Quinze minutes plus tard, un PDF entièrement conçu se trouvait dans mon dossier de sortie. Couvrir la diapositive. Énoncé du problème. Taille du marché avec un véritable graphique TAM/SAM/SOM qui extrait les chiffres réels d'une analyse des concurrents. Un aperçu du produit avec des maquettes. Une diapositive de mise sur le marché. Niveaux de prix. Une section fondatrice. Une demande finale. Dix-huit diapositives, conçues – et non « voici une liste à puces de démarque, vous pouvez la coller vous-même dans Google Slides ». Une chose terminée.
La première fois que j'ai exécuté la même invite sur un seul agent Claude Code il y a six mois, j'ai reçu un aperçu de démarque. Un bon aperçu. Mais un aperçu. L'écart mental entre « Je vais vous écrire le contenu du deck » et « voici un deck » est l'écart que j'attendais que quelqu'un comble dans le monde open source depuis deux ans.
La chose qui l'a fermé pour moi s'appelle Open Swarm. Il s'agit d'un système multi-agent open source de VRSEN — la même équipe derrière l'agence Swarm — qui réside dans votre terminal, exécute huit agents spécialisés sous un seul orchestrateur et produit de véritables livrables (diapositives, rapports de recherche, graphiques, documents, images, vidéo) à partir d'une seule invite. Le slogan du dépôt indique "Claude Code pour tout sauf le codage". C'est exact. Cela sous-estime également légèrement ce qui se passe réellement ici.
Je l'exécute maintenant dans mon pipeline de contenu quotidien depuis près de deux semaines. Laissez-moi vous dire ce qui fonctionne, ce qui ne fonctionne pas, et pourquoi je pense que c'est la chose la plus intéressante qui se passe actuellement dans l'espace des agents open source.
Qu'est-ce que Open Swarm ?
Supprimez le langage marketing et Open Swarm est constitué de trois éléments empilés les uns sur les autres.
En bas se trouve OpenCode, l'agent de codage du terminal open source AI qui compte environ 150 000 étoiles GitHub, plus de 850 contributeurs et une base installée de millions de développeurs. OpenCode lui-même est une TUI écrite sur Bubble Tea, multi-fournisseurs et indépendante du modèle. Si vous avez utilisé Claude Code, OpenCode ressemble à son frère. Même ambiance de clavier en premier, même session persistante, même philosophie « votre projet vit dans le répertoire courant ».
Au milieu se trouve l'agence Swarm, également de VRSEN — un cadre d'orchestration multi-agents qui étend le SDK d'agents OpenAI pour vous offrir des flux de communication fiables, des transferts structurés entre spécialistes et une exécution flexible par le fournisseur (Anthropic, OpenAI, Gemini, Grok, tout ce qui est routable LiteLLM). L'agence Swarm est en production avec les clients de VRSEN depuis un moment ; c'est le moteur qui empêche les agents de se parler.
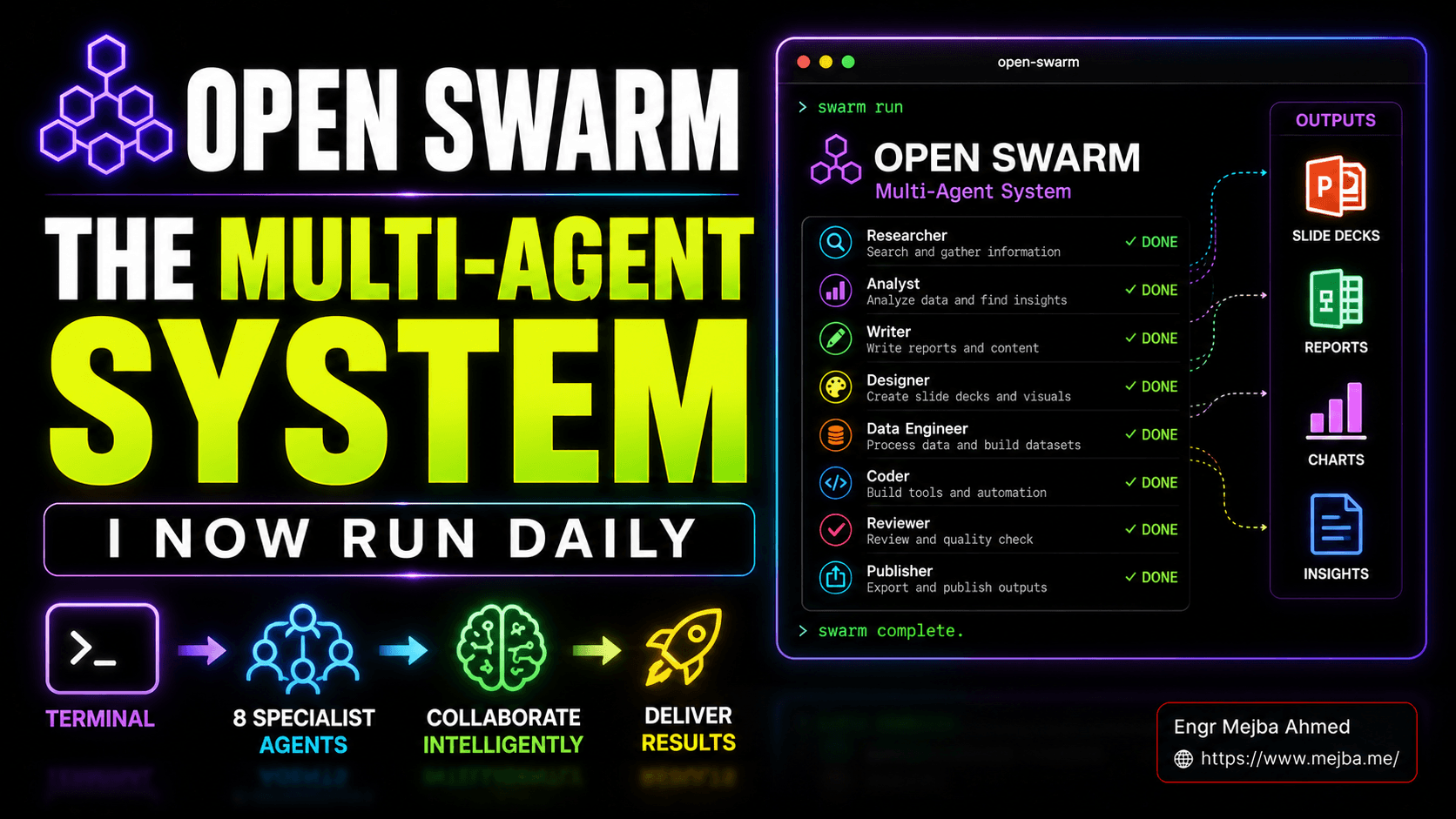
Au-dessus de ces deux se trouve Open Swarm lui-même : un ensemble organisé de huit agents spécialisés, des fichiers d'invite avisés et un assistant de configuration de première exécution qui vous fait passer de git clone à un essaim fonctionnel en moins d'une minute sur une machine propre. Les huit spécialistes, tels que configurés prêts à l'emploi :
- Orchestre — le patron. Reçoit votre invite, la décompose en sous-tâches, attribue le travail à des spécialistes, réessaye en cas d'échec, vous rend le résultat assemblé. 2. Agent général — la solution fourre-tout pour les tâches qui ne conviennent pas à un spécialiste. Accès au Web, raisonnement léger, travail de colle. 3. Agent Slides — conçoit et réalise des présentations. La fonctionnalité de titre. Graphiques, mises en page, cohérence de la marque, exportations au format PDF. 4. Agent de recherche approfondie — le lecteur de contexte long. Extrait des analyses concurrentielles, des rapports de marché, des synthèses multi-sources. Dépense de vrais jetons pour chasser les sources primaires. 5. Agent d'analyse de données — le cerveau du tableur. Prend des chiffres bruts ou des résultats de recherche, produit des graphiques, des tableaux et des résumés. 6. Agent Docs — écrit des documents structurés. Rapports, briefs, one-pagers, contrats, mémos internes.
Compatible Markdown et PDF. 7. Agent vidéo : génère une sortie vidéo courte. Encore précoce, mais fonctionnel pour les maquettes de produits et les animations de pitch. 8. Agent d'image — génère des images pour les diapositives, les maquettes et les actifs de marque. Se connecte aux fournisseurs de génération d’images.
C'est la distribution standard. Rien de tout cela n’est codé en dur. Chaque spécialiste n'est qu'un fichier d'invite plus une liste d'outils plus une affectation de modèle, et vous pouvez modifier, duper ou remplacer n'importe lequel d'entre eux - c'est la partie dont je veux parler correctement plus tard dans cet article, car c'est là que Open Swarm commence à ressembler moins à un produit qu'à une plate-forme.
Le dépôt se trouve sur github.com/VRSEN/OpenSwarm. L'assistant d'installation gère l'authentification, les dépendances et la configuration. Clonez, exécutez l'assistant, déposez vos clés API, vous êtes prêt.
Pourquoi la spécialisation bat un seul gros agent
J'ai passé deux ans à observer les gens essayer de confier tout à un seul agent généraliste. J'en ai construit des versions moi-même. Le modèle échoue de la même manière à chaque fois, et il échoue pour des raisons structurelles, non réparables avec une invite plus intelligente.
Un seul agent effectuant des recherches, des analyses, de l'écriture, de la conception et du rendu accumule le contexte des cinq tâches dans une seule fenêtre. Au moment où il écrit la troisième diapositive, il transporte le HTML brut récupéré de l'étape de recherche, les tentatives de création de graphiques échouées de l'étape de données, le Markdown à moitié édité de l'étape de documentation. Les fenêtres contextuelles sont limitées. Même avec Opus à 1 million de jetons, vous ne voulez pas réellement avoir un million de jetons obsolètes lorsque vous demandez au modèle de prendre une décision visuelle précise concernant un axe du graphique. Les hallucinations augmentent avec le bruit contextuel. La qualité de sortie se dégrade.
Les spécialistes résolvent ce problème en appliquant la portée. L'agent de recherche obtient une fenêtre vierge contenant uniquement la tâche de recherche. Lorsqu'il a terminé, il remet un résumé clair à l'orchestrateur et meurt. L'analyste de données obtient une fenêtre propre qui contient uniquement le résumé ainsi que ses propres outils. Au moment où l'agent Slides récupère le résultat, il travaille dans un contexte précis et organisé, et non dans une soupe de sept tâches précédentes.
C'est à cela que voulait en venir l'article sur l'architecture d'essaim d'agents que j'ai écrit en mars, et c'est le modèle exact que les propres sous-agents forkés dans Claude Code de Anthropic ont implémentés au niveau de la plate-forme. Open Swarm est la même idée généralisée au travail sans codage.
Il existe un deuxième avantage qui compte plus que ce que les gens pensent : chaque spécialiste dispose de son propre ensemble d’outils. L'agent de recherche dispose de recherches sur le Web, de navigation sur le Web, de lecteurs RSS et de récupérateurs de documents. L'analyste de données dispose de bibliothèques d'exécution de code et de graphiques. L'agent Slides dispose d'outils de rendu. Un seul généraliste doit jongler avec chaque outil dans une seule invite, ce qui signifie plus de décisions sur l'outil à utiliser, ce qui signifie plus d'erreurs de sélection d'outils, ce qui signifie des exécutions plus lentes et un rendement moins bon. Les spécialistes font du choix des outils une décision architecturale et non une décision d'exécution.
Le troisième avantage est stupide mais réel : vous pouvez les exécuter en parallèle. La recherche et la génération d'images ne dépendent pas l'une de l'autre, l'orchestrateur peut donc les lancer simultanément. Sur une tâche multi-livrables, le parallélisme réduit considérablement le temps d’horloge murale.
Le face-à-face : Open Swarm contre Claude Code contre Open Claw
J'ai donné la même invite à trois configurations différentes et j'ai regardé ce qui revenait. L'invite : "Construisez-moi un pitch deck complet pour les investisseurs pour une agence de ciblage SaaS de surveillance de la marque AI. Incluez la taille du marché, l'analyse des concurrents, la présentation du produit, les niveaux de tarification, le GTM et une feuille de route sur 12 mois." Même sélection de modèle lorsque cela est possible (Sonnet 4.6 dans tous les domaines pour les agents travailleurs, Opus 4.7 pour toute étape d'orchestration qui le prend en charge).
Claude Code, agent unique. Résultat : un document démarque de 4 400 mots. Excellent contenu – les modèles de Anthropic sont imbattables en matière d'écriture structurée longue – mais il s'agit d'un document, pas d'un deck. Sections intitulées « Diapositive 1 : Couverture », « Diapositive 2 : Problème », etc. Pour transformer cela en quelque chose que je montrerais réellement à un investisseur, je devrais passer plus de 90 minutes dans Figma ou Slides à déplacer du contenu, à concevoir des mises en page, à créer des graphiques. Temps gagné par rapport à l'écriture à partir de zéro : peut-être 60 à 70 %. Délai pour obtenir un livrable fini et présentable : encore plus de deux heures.
Open Claw (la plate-forme d'automatisation des agents que j'ai abordée dans ma comparaison Open Claw vs Claude Code). Résultat : une présentation Google Slides via l'automatisation du navigateur. De vraies diapositives, de vraies mises en page, mais la qualité de conception était le genre de modèle générique bleu et blanc que vous reconnaîtriez dans n'importe quelle démo "AI a généré ceci pour moi". Les graphiques étaient des barres d'espace réservé. Le contenu était environ 80 % aussi bon que celui de Claude Code, car le flux de travail impliquait plus de sauts d'agent et plus de risques de dérive de contexte. Temps nécessaire pour terminer un deck : environ 40 minutes, en grande partie automatisées.
Open Swarm. Résultat : un PDF de 18 diapositives, conçu avec de vrais graphiques alimentés à partir de données de recherche réelles, une typographie cohérente avec la marque et des mises en page ajustées à la main par diapositive. De plus - et cela m'a surpris - un document de synthèse distinct d'une page généré par l'agent Docs en parallèle avec le deck, ainsi que des images de maquette de l'agent d'image que l'agent Slides avait intégrées dans la diapositive de présentation du produit. Temps écoulé : 17 minutes. Coût du jeton : environ 4,20 $ d'appels Sonnet/Opus entre les huit agents. Qualité du résultat final : la plus proche de "Je montrerais ceci à un investisseur sans le retoucher" que j'ai vu parmi n'importe quel système d'agent ouvert.
La partie intéressante n’est pas que Open Swarm ait gagné. La partie intéressante est comment il a gagné. Elle n’a pas gagné parce que le modèle sous-jacent était plus intelligent : les mêmes modèles. Il a gagné parce que l'architecture a placé chaque appel de modèle dans un contexte où il pouvait faire de son mieux, puis a assemblé les pièces. C'est un résultat d'ingénierie, pas un résultat de modèle. Et les résultats techniques sont composés.
Une vraie course, étape par étape
Laissez-moi vous expliquer ce qui se passe réellement lorsque vous déclenchez une invite sur Open Swarm. J'utilise le pitch deck de l'investisseur exécuté ci-dessus comme exemple, car la trace est la plus illustrative.
T+0s : l'invite arrive à l'orchestrateur. L'agent orchestrateur lit l'invite et la décompose. En interne, il génère un graphique de tâches : rechercher le marché de surveillance de la marque AI, identifier 4 à 6 concurrents, créer un modèle TAM/SAM/SOM, rédiger le positionnement du produit, concevoir 18 diapositives avec une image de marque cohérente, produire un résumé exécutif d'une page, générer une image de maquette de produit. Le graphique des tâches est conservé dans la mémoire de travail de l'orchestrateur et n'est pas écrit sur le disque, bien que vous puissiez activer un indicateur pour le vider à des fins de débogage.
T+30 – l'agent de recherche est renvoyé. L'agent de recherche approfondie obtient la sous-tâche d'analyse concurrentielle. Il exécute des recherches Web en plusieurs étapes, extrait des pages de G2, Crunchbase, ProductHunt, les sites marketing des concurrents. Il rédige une grille concurrentielle structurée en démarque – nom, positionnement, prix, segment cible, faiblesses. Environ 90 secondes d'horloge murale, environ 200 000 jetons de temps de modèle. Le résultat est renvoyé à l'orchestrateur sous la forme d'un résumé clair ; l'orchestrateur supprime le code HTML brut récupéré avant de transmettre quoi que ce soit en aval.
T+2m — les agents de recherche et d'image s'exécutent en parallèle. L'orchestrateur déclenche à nouveau l'agent de recherche approfondie sur une tâche distincte (dimensionnement du marché TAM/SAM/SOM) en même temps que l'agent d'image (maquette de produit d'un tableau de bord). Le parallélisme est ici un gain de temps bon marché mais réel : ces deux tâches ne partagent pas de contexte.
T+4m — l'agent d'analyse de données récupère les résultats de la recherche. La recherche sur la taille du marché revient sous forme de chiffres bruts de l'industrie et de notes méthodologiques. L'agent de données l'ingère, exécute Python dans un interpréteur de code en bac à sable, génère un graphique TAM/SAM/SOM avec les axes et les étiquettes appropriés, ainsi qu'un tableau de comparaison des prix des concurrents. Les graphiques sont enregistrés dans un répertoire temporaire à partir duquel l'agent Slides lira.
T+7 m : l'agent Slides démarre la phase de conception. Il s'agit de l'agent qui effectue la partie de travail la plus lourde. Il lit les résumés de recherche, les graphiques, les exigences de la marque (il demande à l'orchestrateur s'il a besoin de quelque chose d'ambigu). Il génère une spécification de présentation : 18 diapositives, chacune avec un type de mise en page, un contenu, des références d'images et des références de graphiques. Ensuite, il rend. De l’autre côté : un vrai PDF.
T+12 mois : l'agent de documentation écrit la page d'une page en parallèle avec le rendu des diapositives. Extrait la même recherche, la condense en un résumé de 600 mots, l'exporte au format PDF. Indépendant de l'agent Slides car les données d'entrée sont les mêmes et les sorties n'ont pas besoin d'être coordonnées.
T+17 m — l'orchestrateur assemble, valide, renvoie. Vérification finale : tous les livrables existent-ils, la taille des fichiers est-elle raisonnable, un agent a-t-il enregistré une erreur critique, l'exécution s'est-elle terminée dans les limites de son budget de nouvelle tentative. Ensuite, le contrôle revient au terminal et vous voyez les chemins de fichiers dans votre dossier de sortie.
Ce que vous ne voyez pas pendant cette exécution, c'est la boucle de nouvelle tentative de l'orchestrateur. La première tentative d'analyse concurrentielle a échoué : l'un des sites concurrents a renvoyé un défi Cloudflare qui a brisé le scraper. L'orchestrateur a détecté l'échec, a réessayé avec une stratégie de grattage différente et n'a jamais dérangé l'humain (moi) à ce sujet. C'est une petite chose qui compte beaucoup. Une configuration à agent unique échoue devant vous ou masque entièrement l’échec. Un essaim avec un véritable orchestrateur traite les échecs comme un problème de routage.
Personnalisation de votre propre Swarm
C'est la partie de Open Swarm qui, à mon avis, est sous-vendue dans la plupart des couvertures que j'ai vues. La répartition par défaut de huit agents est un point de départ et non un plafond. Chaque spécialiste est un fichier d'invite, une liste d'outils et une affectation de modèle. Vous pouvez créer le dépôt et tout changer.
Concrètement, la structure ressemble à ceci. Chaque agent se présente sous la forme d'un répertoire avec un prompt.md (invite système), un tools.yaml (la liste d'outils avec autorisations) et un bloc de configuration dans agents.md (sélection du modèle, température, stratégie de nouvelle tentative, liaison de l'orchestrateur parent). L'ajout d'un nouvel agent est véritablement un travail de copier-coller-édition, et non un travail consistant à « apprendre d'abord le framework ». Si vous avez déjà écrit une définition de sous-agent Claude Code, il s'agit du même modèle mental avec un nom de fichier différent.
Voici celui que j’ai construit et qui, à mon avis, constitue le meilleur cas. J'ai créé Open Swarm et l'ai transformé en un essaim de référencement – un mélange de spécialistes différent optimisé pour le type de travail que je fais chaque semaine. Le huit par défaut est devenu :
- Orchestre — inchangé, toujours le patron. - Planificateur de mots clés : remplacement de "agent général". Extrait les requêtes de la Search Console, exécute la classification des intentions, crée des clusters de mots clés. Liste d'outils : client GSC API, un petit outil Python personnalisé pour la notation de cluster. - Rédacteur de notes : remplacement de "agent de diapositives". Prend un groupe de mots-clés cible et produit un résumé de contenu structuré : analyse SERP, carte d'angle des concurrents, plan recommandé, nombre de mots cibles, suggestions de liens internes. - Agent de recherche approfondie – conservé, mais avec un ensemble d'outils plus petit et une invite plus stricte axée sur la recherche industrielle plutôt que sur la recherche générale. - Agent de données — remplacé par un spécialiste de l'analyse GA4/GSC. Extrait des données de performances, crée des tableaux de bord, signale les pages en décomposition. - Agent Docs — conservé.
Rédige désormais l'article de blog lui-même une fois le brief approuvé. - Agent Crawler : remplacement de "agent vidéo". Exécute une analyse SEO technique légère sur un domaine cible : vérifications du balisage du schéma, intégrité des liens internes, balayage du code d'état. - Agent d'image — conservé, utilisé pour les images de héros de blog.
Le processus de fork a pris un après-midi. La plus grande augmentation de productivité en une seule journée que mon pipeline ait connue depuis des mois. Le titre que vous devriez retenir de cette anecdote n’est pas que j’ai construit un essaim SEO. C'est que la surface de personnalisation est suffisamment peu profonde pour que "construire-moi un essaim pour mon travail exact" soit un projet du samedi, et non un quart de travail d'ingénierie. Toute personne dont le travail implique plusieurs sous-tâches distinctes sur lesquelles un généraliste se trompe peut le faire.
L'autre élément qui mérite d'être signalé : VRSEN a fait allusion à un "agent constructeur" - un agent qui prend une description en langage naturel d'un flux de travail ("Je veux un essaim qui surveille les concurrents pour les startups SaaS") et lance le mélange spécialisé pour vous. C'est encore en développement au moment où j'écris ceci. Lorsqu'il atterrit, la barrière de personnalisation passe de « projet du samedi » à « cinq minutes ». Cela change les calculs quant à savoir qui peut utiliser cela.
Où cela s'intègre-t-il dans mon flux de travail aux côtés de Claude Code
Je veux être honnête à propos de cette partie parce que le cadrage « X tue Y » est paresseux et généralement erroné. Open Swarm n'a pas remplacé Claude Code dans ma pile. Il passe à côté.
Claude Code est toujours l'endroit où se déroule mon travail de codage. Refactoring, création d'agents, débogage, travaux d'infrastructure : c'est le bon outil pour "le livrable est un changement de code". Les modèles de Anthropic ont un avantage sur le raisonnement en code long que rien dans l'écosystème ouvert n'a encore égalé. Les sous-agents forkés de Claude Code et le récent doublement des limites de débit après l'accord de calcul SpaceX le rendent plus utile que jamais pour les travaux d'ingénierie de production.
Open Swarm est le bon outil pour « le livrable est autre chose que du code ». Ponts. Rapports. Maquettes. Graphiques. Slips. Le genre de travail qui était autrefois une chaîne de "Claude m'a écrit un plan, puis je l'ai conçu dans Figma, puis j'ai créé des graphiques dans Numbers, puis j'ai exporté au format PDF" et se résume maintenant en une seule invite et une seule session de terminal.
Le reste de la pile : j'utilise toujours Open Claw pour les flux de travail visuels là où le modèle de supervision humaine est important : tableau de style kanban, portes d'approbation humaines entre les étapes, visibilité des parties prenantes. Ce n’est pas la bonne solution pour une exécution tête baissée des livrables ; c'est la solution idéale pour un projet interfonctionnel de plusieurs jours. Et Codex se trouve dans le coin pour les quelques tâches spécifiques où le style de raisonnement de GPT bat celui de Claude.
Trois outils axés sur le terminal, un modèle mental, trois choix délibérés quant à savoir lequel licencier pour quel poste. Le fil conducteur est que tous les trois sont des fichiers locaux, le terminal d’abord et tolèrent des exécutions autonomes de plusieurs heures. Aucun d'entre eux n'est un tableau de bord SaaS que je dois garder. Cette orientation vers le terminal d’abord est ce à quoi je reviens sans cesse comme étant la chose sous-estimée. Si vous avez récemment utilisé une plate-forme d'agent basée sur l'interface utilisateur, vous savez ce que je veux dire : il y a une friction persistante dans le changement de contexte constant entre votre éditeur et l'interface Web de l'agent. Open Swarm et ses pairs éliminent cela. L'agent court là où j'habite déjà.
Ce qui s'en vient
Quelques éléments de la feuille de route Open Swarm méritent d'être signalés car ils modifient ce que vous pouvez en faire avant la fin de l'année.
Des intégrations plus étroites avec les agents terminaux adjacents. Open Swarm + Codex + Claude Code en tant que trio coordonné est évoqué dans les chaînes communautaires de VRSEN – l'idée étant que Open Swarm orchestre le travail de non-codage, confie les tâches de codage à Codex ou Claude Code et réassemble la sortie. C'est la pièce manquante pour "Je veux une seule invite pour concevoir et livrer une petite fonctionnalité SaaS". Aujourd'hui, vous faites cela sous la forme de deux invites dans deux terminaux. Demain, ce sera peut-être un.
Intégration Open Claw. "Tous vos agents au même endroit" est le langage utilisé par VRSEN. En pratique, cela signifierait que l'architecture native du terminal de Open Swarm est connectée au flux de travail d'approbation visuelle d'Open Claw : vitesse du terminal pour l'exécution lourde, surveillance visuelle pour les moments de passage humain. Le bon mélange s’il est réellement expédié.
L'agent générateur d'agents. Je l'ai mentionné ci-dessus. Le plus grand accélérateur d’adoption, s’il réussit. La barre est haute : la plupart des démos « construisez-moi un agent à partir du langage naturel » que j'ai vues produisent des agents techniquement corrects et pratiquement inutiles. Si VRSEN peut en expédier un qui produit des essaims fonctionnels, la barrière de la personnalisation s’effondre.
De meilleurs spécialistes de la vidéo et de l'image. C'est la partie de la distribution par défaut qui est clairement la plus jeune. Diapositives, documents, recherches, données : ces agents sont matures. L'agent vidéo fonctionne mais produit une sortie qui ressemble à un outil vidéo génératif de 2024, et non à un outil de 2026. L'agent d'image est bien mais pas bien pour Higgsfield. Je m'attendrais à ce que les deux évoluent de manière agressive au cours des deux prochains trimestres, à mesure que VRSEN propose de meilleures intégrations d'outils.
Mémoire et apprentissage à travers les exécutions. À l'heure actuelle, chaque exécution est pour la plupart nouvelle. L'infrastructure existe dans l'agence Swarm pour la mémoire à long terme basée sur l'intégration, et certains signaux indiquent qu'elle arrive dans Open Swarm. La version de ceci dans laquelle mon essaim SEO se souvient des groupes de mots clés exécutés et ajuste les futurs briefs en conséquence est la version pour laquelle je paierais de l'argent réel.
Limites honnêtes
Je vais faire cette partie de la façon dont j'aimerais que quelqu'un le fasse pour moi – directement, sans couverture.
« Aucun codage requis » n'est pas strictement vrai. La promesse est que vous n'écrivez pas de code pour exécuter Open Swarm. C'est exact. La promesse n'est pas que vous ne touchiez jamais à un fichier. Pour personnaliser l'essaim de manière significative, vous modifiez les fichiers d'invite. Pour ajouter un outil, vous modifiez un fichier YAML. Pour déboguer un spécialiste qui se comporte mal, vous lisez son invite et déterminez où les instructions sont erronées. Si l'expression « modifier une configuration YAML » vous inquiète, la couche de personnalisation de Open Swarm ressemblera à du codage même si ce n'est pas le cas.
La qualité de sortie évolue en fonction du choix du modèle. Cela semble évident. Cela compte plus qu’il n’y paraît. Exécutez Open Swarm sur des modèles bon marché et vous obtenez une sortie bon marché. Exécutez-le sur Sonnet 4.6 sur les agents de travail et Opus 4.7 sur l'orchestrateur et vous obtenez les résultats que j'ai décrits ci-dessus. L’architecture en essaim amplifie la qualité que vous offrent les modèles sous-jacents – pour le meilleur ou pour le pire. Ne vous attendez pas à un rendement de 0,30 $ par exécution pour les modèles à 0,30 $ par exécution.
Les courses autonomes de plusieurs heures coûtent de vrais jetons. La course de présentation aux investisseurs que j'ai décrite coûte environ 4,20 $. C'est très bien pour les livrables ponctuels. Si vous en mettez vingt en file d'attente par jour, cela représente 84 /day, soit 2 500 $ par mois, rien que pour les courses de l'agent. C'est toujours moins cher que d'embaucher un concepteur ou un analyste, mais ce n'est pas gratuit et cela peut vous surprendre. Définissez un plafond de coût par exécution dans la configuration dès le premier jour. L'essaim le respecte.
** L'agent des diapositives est le titre. L'image et la vidéo sont encore précoces.** J'y reviens sans cesse car cela est important pour la définition des attentes. Si vous êtes vendu sur Open Swarm en raison de la sortie du deck, vous obtiendrez exactement ce pour quoi vous vous êtes inscrit. Si vous êtes convaincu par la sortie vidéo, modérez vos attentes d’un cran. L'agent vidéo fonctionne (je l'ai utilisé pour des animations de maquettes de produits) mais c'est la partie de la distribution par défaut qui nécessite le plus de travail. Dans six mois, je m'attendrais à un rapport différent à ce sujet.
Le verrouillage du fournisseur est un risque auquel vous devriez penser. Open Swarm fonctionne sur LiteLLM, ce qui signifie que la flexibilité du fournisseur est techniquement disponible. En pratique, les fichiers d'invite sont adaptés aux particularités spécifiques de Sonnet/Opus, et le passage à un autre fournisseur dégrade la qualité de sortie. Si votre préoccupation est « et si Anthropic augmente les prix ou supprime des fonctionnalités », Open Swarm ne vous protège pas complètement de cela. Il vous offre une option de migration, pas la parité de migration.
De longues exécutions peuvent masquer des problèmes. Lorsqu'un spécialiste commet une erreur discrète lors de la troisième étape d'une exécution de quinze minutes, l'orchestrateur ne la détecte généralement pas. Vous voyez le résultat final, il semble plausible, vous l'expédiez. Une semaine plus tard, vous réalisez que l'analyse concurrentielle a répertorié un concurrent qui n'existe pas parce que l'agent de recherche a halluciné et que rien en aval ne l'a détecté. Cela est vrai pour tous les systèmes multi-agents et Open Swarm n'est pas pire que ses pairs, mais la distance entre "J'ai commencé l'exécution" et "Je vois le résultat" rend la vérification plus lente qu'elle ne devrait l'être. Prenez l'habitude de vérifier ponctuellement les citations dans tout livrable que vous allez envoyer à un véritable humain.
Qui devrait essayer ce week-end
Si vous êtes un fondateur qui a rédigé à la main des présentations d'investisseurs et que vous disposez de 50 $ de crédit API, installez Open Swarm ce soir. Exécutez l’invite de présentation aux investisseurs contre votre propre entreprise. Le premier deck que vous récupérerez ne sera pas votre deck final - mais le deuxième draft, après lui avoir fourni vos chiffres réels et resserré le positionnement, aura parcouru quatre-vingt-dix pour cent du chemin en une fraction du temps qu'il faudrait pour le faire à la main.
Si vous êtes un chercheur qui crée des rapports pour ses clients, la combinaison recherche approfondie et documentation est le cas d'utilisation pour lequel l'essaim a été conçu. Une bonne règle : tout livrable qui vous demande actuellement une journée complète de « recherche, puis graphique, puis écriture, puis formatage » est candidat pour une expérience le samedi après-midi.
Si vous êtes un spécialiste du marketing ou un opérateur SEO comme moi, la bonne solution est de créer la distribution par défaut et de créer votre propre essaim. Les huit spécialistes par défaut sont destinés aux travaux commerciaux généraux. Spécialisez-les pour votre travail et le gain de productivité est de ceux qui changent ce que vous pouvez facturer aux clients.
Si vous êtes un développeur qui est à l'aise avec les équipes d'agents de Claude Code et que vous souhaitez étendre le même modèle au travail sans codage, c'est exactement cela. Le modèle mental est identique. Le frottement est faible.
Et si vous êtes quelqu'un qui a été frustré par les plafonds d'un seul agent - des exécutions qui atteignent les limites du contexte, des hallucinations longuement trois, une perte de fil sur des tâches en plusieurs étapes - c'est l'architecture que vous attendiez que quelqu'un livre en tant que primitive open source propre. Le modèle orchestrateur plus spécialistes n’est pas un concept nouveau. Le modèle fourni comme quelque chose que vous pouvez cloner et exécuter en 60 secondes est nouveau.
L'installation en une ligne est un git clone de github.com/VRSEN/OpenSwarm suivi de l'assistant d'installation. Une machine propre à un essaim fonctionnel : moins de cinq minutes. Le coût de l’essayer : faible. L’avantage si cela persiste : un changement permanent dans la quantité de travail que vous pouvez confier à une machine.
Je suis resté assis sur le doublement de la limite de taux Claude Code pendant deux semaines avant d'écrire à ce sujet parce que je voulais savoir si cela changeait réellement quelque chose. J'écris à propos de Open Swarm trois semaines après la première installation car la réponse est arrivée plus tôt. Il s'agit du premier élément d'infrastructure d'agent open source que j'ai installé en 2026 et qui occupe une place permanente dans mon flux de travail sans que j'aie à me convaincre qu'il en mérite un. Les livrables qu’il produit sont réels. L'architecture est correcte. L’histoire de personnalisation est suffisamment superficielle pour que vous puissiez vous l’approprier en un week-end.
Le terminal a déjà gagné la guerre UX de l'agent AI. Open Swarm est la chose la plus intéressante qui se passe à l'intérieur de ce terminal et qui ne consiste pas à écrire du code.
Questions fréquemment posées
L'utilisation de Open Swarm est-elle gratuite ?
Open Swarm lui-même est gratuit et open source sous le dépôt de VRSEN sur github.com/VRSEN/OpenSwarm. Vous apportez votre propre modèle de clés API - Anthropic, OpenAI, Gemini ou tout fournisseur compatible LiteLLM - et payez ces fournisseurs directement pour l'utilisation du jeton. Une exécution typique entièrement livrable coûte quelques dollars en appels de modèles.
Quelle est la différence entre Open Swarm et l'agence Swarm ?
L'agence Swarm est le cadre d'orchestration multi-agent sous-jacent : le moteur. Open Swarm est une distribution organisée et prête à l'emploi construite sur celle-ci : huit agents spécialisés préconfigurés, un assistant de configuration, des invites avisées, une UX axée sur le terminal. Si l'agence Swarm est le cadre, Open Swarm est le kit de démarrage avec piles incluses.
Dois-je savoir coder pour exécuter Open Swarm ?
Vous n'avez pas besoin d'écrire du code pour exécuter l'essaim par défaut : clone, assistant de configuration, invite, terminé. Pour personnaliser les spécialistes ou créer votre propre essaim, vous modifierez les fichiers d'invite (markdown) et la configuration des outils (YAML). Il s'agit d'édition de texte, pas de codage, mais si « modifier un fichier YAML » vous donne l'impression de coder, attendez-vous à une petite courbe d'apprentissage au niveau de la couche de personnalisation.
Comment Open Swarm se compare-t-il aux sous-agents Claude Code ?
Les sous-agents de Claude Code sont le même modèle architectural (orchestre plus spécialistes avec fenêtres contextuelles séparées) appliqué au travail de codage. Open Swarm l'applique à tout sauf au codage : diaporamas, rapports de recherche, graphiques, documents, images. Ce sont des outils complémentaires que vous utiliseriez raisonnablement côte à côte plutôt qu’avec des concurrents.
Quels modèles fonctionnent le mieux avec Open Swarm ?
Lors de mes tests, Sonnet 4.6 sur les agents de travail et Opus 4.7 sur l'orchestrateur ont produit la sortie de la plus haute qualité. Le framework est indépendant du fournisseur via LiteLLM, mais les fichiers d'invite par défaut sont adaptés aux modèles de Anthropic, donc changer de fournisseur a tendance à dégrader la qualité à moins que vous ajustiez également les invites.
Travaillons ensemble
Vous cherchez à créer des systèmes AI, à automatiser les flux de travail ou à faire évoluer votre infrastructure technologique ? J'aimerais aider.
- Fiverr (versions et intégrations personnalisées) : fiverr.com/s/EgxYmWD
- Portefeuille : mejba.me
- Ramlit Limited (solutions d'entreprise) : ramlit.com
- ColorPark (conception et image de marque) : colorpark.io
- xCyberSecurity (services de sécurité) : xcybersecurity.io



