

Karpathys Obsidian RAG Hat Meine Vektordatenbank Abgelöst
Ich steckte mitten in einer traditionellen RAG-Pipeline, als Andrej Karpathy etwas auf X postete, das mich jede Architekturentscheidung der letzten sechs Monate hinterfragen ließ.
Keine Vektordatenbank. Keine Embeddings. Keine Chunking-Strategie. Keine Similarity-Schwellenwerte zum Tunen. Nur Markdown-Dateien, eine Ordnerstruktur und ein LLM, das gleichzeitig als Bibliothekar und Autor fungiert.
Meine erste Reaktion war Skepsis. Ich habe RAG-Systeme gebaut. Ich habe Retrieval-Fehler debuggt, mit Chunk-Overlap-Einstellungen gekämpft und zugesehen, wie perfekt relevante Dokumente unter Cosine-Similarity-Scores begraben wurden, die keinen Sinn ergaben. Die Vorstellung, dass man diese ganze Infrastruktur überspringen und bessere Ergebnisse für eine persönliche Wissensdatenbank erzielen könnte, fühlte sich an, als würde jemand sagen, man könne ein Auto überholen, indem man geht — in die richtige Richtung.
Dann baute ich es. Und die In-die-richtige-Richtung-gehen-Metapher erwies sich als unbequem zutreffend.
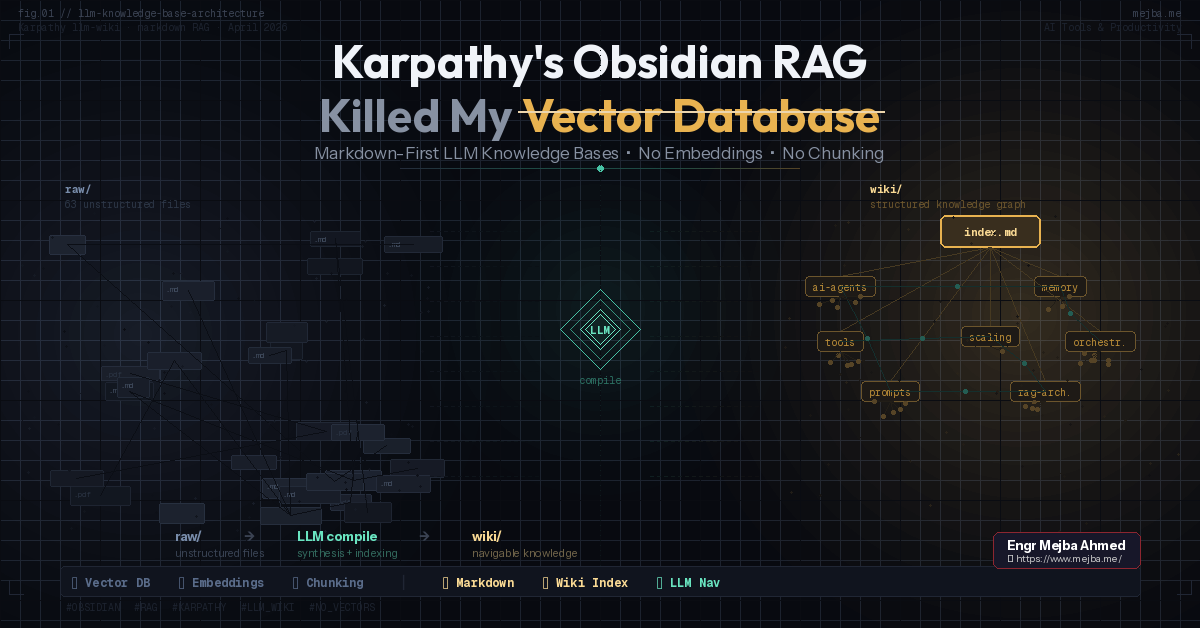
Karpathys System — das er "LLM Knowledge Bases" nennt — funktioniert, weil es etwas ausnutzt, das die meisten RAG-Architekten übersehen: Für Datensätze unter etwa 400.000 Wörtern (ungefähr 100 substanzielle Artikel) gibt eine gut organisierte Markdown-Struktur mit Zusammenfassungen und Indexdateien dem LLM mehr nützlichen Kontext als Vektorsuche es je könnte. Das Modell ruft keine Fragmente ab. Es navigiert durch einen Wissensgraphen, den es selbst aufgebaut hat, folgt Links, die es selbst erstellt hat, liest Zusammenfassungen, die es selbst geschrieben hat.
Diese Unterscheidung — das LLM als Autor der Wissensstruktur, nicht nur als Konsument abgerufener Chunks — verändert alles daran, wie das System performt. Und es ist der Teil, den die meiste Berichterstattung über Karpathys Ansatz unter der Überschrift begräbt.
Warum Traditionelles RAG auf der Skala Versagt, auf der die Meisten Menschen Tatsächlich Arbeiten
Hier ist etwas, das niemand im RAG-Ökosystem zugeben will: Für 90% der einzelnen Entwickler und kleinen Teams ist traditionelles RAG Overkill, der die Ergebnisse aktiv verschlechtert.
Ich spreche nicht von Enterprise-Suche über Millionen von Dokumenten. Das ist ein anderes Problem mit anderen Einschränkungen. Ich spreche vom Entwickler, der 50-200 gebookmarkte Artikel hat, eine Handvoll Forschungsarbeiten, etwas Repo-Dokumentation und einen wachsenden Stapel Notizen, über die ein LLM reasoning betreiben soll.
Für diesen Anwendungsfall — der die meisten von uns beschreibt — führt die traditionelle RAG-Pipeline drei Probleme ein, die Markdown-first-Systeme schlicht nicht haben.
Das Chunking-Problem. Jedes RAG-System teilt Dokumente in Chunks auf. Die Chunk-Größe ist ein Kompromiss: zu klein und man verliert Kontext, zu groß und man verschwendet Tokens an irrelevanten Text. Es gibt keine universell korrekte Chunk-Größe, und die falsche Wahl verschlechtert still jede Query. Ich habe ganze Nachmittage mit dem Tuning von Chunk-Overlap-Prozentsätzen verbracht, und die ehrliche Wahrheit ist, dass es sich immer anfühlte, als würde ich mit dem System verhandeln statt es zu konfigurieren.
Das Retrieval-Rausch-Problem. Vektor-Similarity-Suche gibt die mathematisch ähnlichsten Chunks zurück, nicht die nützlichsten. Ich hatte Queries, bei denen die Top-5 abgerufenen Chunks alle aus demselben Abschnitt desselben Dokuments stammten — fünf leicht unterschiedliche Absätze, die fast dasselbe sagten — während die tatsächlich relevante Erkenntnis aus einem anderen Dokument auf Position 47 in den Ergebnissen saß. Relevanz und Ähnlichkeit sind nicht dasselbe, und Vektorsuche optimiert für das Falsche.
Das Black-Box-Problem. Mit einer Vektordatenbank kann man nicht einfach sehen, was drin ist. Man kann seine Wissensdatenbank nicht durchblättern wie einen Ordner. Man kann nicht manuell prüfen, ob ein Dokument korrekt indexiert wurde. Man kann keine Lücken in der Abdeckung erkennen, indem man eine Liste überfliegt. Die Daten verschwinden in Embeddings, und man interagiert mit ihnen nur über Queries, die vielleicht das liefern, was man braucht — oder auch nicht.
Karpathys System umgeht alle drei. Kein Chunking — das LLM liest strukturierte Zusammenfassungen und folgt Links zu vollständigen Dokumenten bei Bedarf. Keine Vektor-Similarity — das LLM navigiert durch einen Index, den es aufgebaut hat und versteht. Keine Black Box — jedes Stück Wissen lebt in einer lesbaren Markdown-Datei, die man in jedem Texteditor öffnen kann.
Der Trade-off? Es skaliert nicht auf Millionen von Dokumenten. Aber wenn die Wissensdatenbank in Hunderten von Artikeln gemessen wird statt in Millionen, ist dieser Trade-off einer der besten Deals in der KI derzeit.
Wie Karpathys LLM-Wissensdatenbank Tatsächlich Funktioniert
Am 3. April 2026 veröffentlichte Karpathy einen GitHub-Gist namens llm-wiki, der die vollständige Architektur darlegt. Das System hat drei Schichten, und zu verstehen, wie sie zusammenwirken, ist der Schlüssel, um es zum Laufen zu bringen.
Schicht 1: Der Roh-Tresor
Alles beginnt in einem raw/-Ordner innerhalb eines Obsidian-Vaults. Dies ist der Staging-Bereich — ein Sammelplatz für alles, was das LLM letztendlich wissen soll. Vom Web kopierte Artikel. PDF-Forschungsarbeiten. Repository-Dokumentation. Screenshots. Code-Schnipsel. Podcast-Transkripte.
Der raw-Ordner hat eine Regel: Nichts darin muss organisiert sein. Man wirft Dinge hinein, und das LLM organisiert sie später. Das ist wichtiger, als es klingt. Die meisten Wissensmanagement-Systeme scheitern, weil die Aufnahmereibung zu hoch ist — man muss Dinge taggen, kategorisieren, an der richtigen Stelle ablegen. Mit Karpathys Ansatz ist die Aufnahme so einfach wie das Ziehen einer Datei in einen Ordner.
Für Webartikel nutzt Karpathy den Obsidian Web Clipper — eine Chrome-Erweiterung, die jede Webseite in eine Markdown-Datei konvertiert und sie direkt in den raw-Ordner legt. Ein Klick. Der Artikel ist im System, Bilder und alles.
Apropos Bilder: Obsidian handhabt Inline-Bilder von geclippten Webseiten nicht automatisch. Man braucht das "Local Images Plus" Community-Plugin, das externe Bilder herunterlädt und sie lokal im Vault speichert. Ohne dieses Plugin haben geclippte Artikel defekte Bildlinks, sobald man offline geht — und das LLM kann visuelle Inhalte nicht über seine Vision-Fähigkeiten referenzieren.
Schicht 2: Das Kompilierte Wiki
Hier weicht Karpathys System von jedem anderen Wissensmanagement-Ansatz ab, den ich gesehen habe.
Statt die Rohdokumente für Retrieval zu indexieren, liest das LLM sie und schreibt neue Dokumente. Es kompiliert das Rohmaterial zu einem strukturierten Wiki — enzyklopädische Artikel über Kernkonzepte, Zusammenfassungen von Quelldokumenten und explizite Backlinks zwischen verwandten Ideen.
Das Wiki lebt in einem wiki/-Ordner, parallel zu raw/. Darin findet man:
-
Einen Master-Index (
index.md) — eine einzelne Markdown-Datei, die jedes erstellte Wiki auflistet, mit kurzen Beschreibungen und Links. Dies ist der Startpunkt des LLM für jede Query. Es liest den Master-Index, identifiziert welches Wiki relevant ist und navigiert dann zum eigenen Index und den Artikeln dieses Wikis. -
Sub-Wiki-Ordner — jedes Thema bekommt seinen eigenen Ordner mit eigenem
index.mdund einem Satz kompilierter Artikel. Ein Wiki über "Transformer-Architekturen" könnte Artikel über Aufmerksamkeitsmechanismen, Positionskodierung und Skalierungsgesetze enthalten, alle untereinander verlinkt. -
Backlinks und Querverweise — das LLM erstellt
[[Wiki-Stil-Links]]zwischen verwandten Konzepten über verschiedene Wikis hinweg. Diese sind nicht dekorativ. Sie bilden die Navigationsstruktur, die das LLM verwendet, wenn es Queries beantwortet, die mehrere Themen umfassen.
Der Kompilierungsschritt ist, wo das LLM seinen Wert beweist. Es kopiert keinen Text aus Rohdokumenten in Wiki-Artikel. Es synthetisiert — es identifiziert die Kernkonzepte, schreibt klare Erklärungen, notiert Widersprüche zwischen Quellen und baut ein Netz von Verbindungen, das keine Vektordatenbank replizieren könnte.
So sieht ein Kompilierungs-Prompt in der Praxis aus. Man richtet seinen LLM-Agenten (Karpathy nutzt Claude Code) auf den raw-Ordner und sagt etwas wie:
Lies die Dateien in raw/ durch, die sich auf [Thema] beziehen.
Erstelle ein neues Wiki in wiki/[themenname]/ mit:
1. Einer index.md, die alle Artikel in diesem Wiki auflistet
2. Einzelnen Artikeln für jedes wichtige Konzept
3. Backlinks zu verwandten Wikis wo relevant
4. Aktualisiere den Master wiki/index.md um dieses neue Wiki aufzunehmen
Das LLM führt die Recherche durch, schreibt die Artikel, baut die Links und aktualisiert die Indexe. Man überprüft die Ausgabe in Obsidians UI — sauber, navigierbar, menschlich lesbar.
Schicht 3: Das Query-Interface
Wenn man dem LLM eine Frage über die Wissensdatenbank stellt, durchsucht es keine Rohdokumente. Es folgt einem strukturierten Pfad:
- Liest den Master
wiki/index.mdum relevante Wikis zu identifizieren - Öffnet die
index.mddes relevanten Wikis um spezifische Artikel zu finden - Liest diese Artikel (die synthetisiertes Wissen plus Quellenverweise enthalten)
- Folgt Backlinks zu verwandten Konzepten, wenn die Frage mehrere Themen umfasst
- Gibt eine Antwort zurück, die im kompilierten Wiki verankert ist, mit Verweisen auf spezifische Artikel
Dies ähnelt mehr der Arbeitsweise eines menschlichen Forschers als alles, was Vektorsuche bietet. Ein Forscher scannt nicht jedes Dokument in einer Bibliothek nach Schlüsselwort-Übereinstimmungen. Er prüft den Index, findet den richtigen Abschnitt, liest die relevanten Artikel und folgt Verweisen zu verwandtem Material.
Der Leistungsunterschied ist real. Für Karpathys Datensatz von ungefähr 100 Artikeln und 400.000 Wörtern lieferte der Wiki-Navigationsansatz kohärentere, besser belegte Antworten als eine traditionelle RAG-Pipeline — weil das LLM über strukturiertes Wissen reasoning betrieb, das es bereits synthetisiert hatte, statt in Echtzeit zu versuchen, abgerufene Chunks zu verstehen.
Das Ganze von Grund auf Einrichten: Die Vollständige Anleitung
Ich habe Karpathys System auf meiner eigenen Maschine in unter einer Stunde nachgebaut. Hier ist jeder Schritt, einschließlich der Schritte, die die meisten Anleitungen überspringen.
Schritt 1: Obsidian installieren und die Vault-Struktur erstellen.
Obsidian von obsidian.md herunterladen. Es ist kostenlos für den persönlichen Gebrauch. Einen neuen Vault erstellen — Obsidian fragt nach einem Ordner. Ich nannte meinen vault und legte ihn in mein Home-Verzeichnis, aber der Speicherort ist egal.
Innerhalb des Vaults zwei Ordner erstellen:
vault/
raw/
wiki/
Das ist die gesamte Dateistruktur zum Start. Der wiki-Ordner wird beim Kompilieren befüllt.
Schritt 2: Den Web Clipper installieren.
Zu obsidian.md/clipper gehen und die Chrome-Erweiterung installieren. In den Clipper-Einstellungen den Standard-Speicherort auf den raw/-Ordner setzen. Jetzt ist jeder Webartikel nur einen Klick von der Wissensdatenbank entfernt.
Sofort testen. Einen Artikel clippen, den man schon lesen wollte. Obsidian öffnen und bestätigen, dass die Markdown-Datei in raw/ erschienen ist. Wenn Bilder nicht angezeigt werden, braucht man Schritt 3.
Schritt 3: Local Images Plus installieren.
In Obsidian zu Einstellungen > Community-Plugins > Durchsuchen gehen. Nach "Local Images Plus" suchen und installieren. Das Plugin aktivieren, dann konfigurieren, dass es Bilder in einen Unterordner im Vault herunterlädt (ich verwende vault/assets/images/).
Nach Aktivierung dieses Plugins erneut einen Webartikel clippen. Die Bilder sollten jetzt lokal heruntergeladen werden und korrekt in Obsidians Vorschaumodus angezeigt werden. Dies ist besonders wichtig beim Clippen technischer Artikel mit Diagrammen, Architektur-Charts oder Code-Screenshots — der visuelle Kontext ist wichtig, und moderne LLMs mit Vision-Fähigkeiten können diese Bilder tatsächlich lesen.
Schritt 4: Den raw-Ordner befüllen.
Das ist der spaßige Teil. Damit beginnen, Inhalte in raw/ zu laden. Einige Quellen, die gut funktionieren:
- Technische Blogposts, die man gebookmarkt hat (Web Clipper verwenden)
- Forschungsarbeiten (als PDF speichern oder in Markdown konvertieren)
- GitHub-Repo-READMEs (Markdown direkt kopieren)
- Eigene Notizen, Gliederungen und Projektdokumentation
- Konferenz-Transkripte
- Gespeicherte Newsletter-Ausgaben
Nicht organisieren. Nicht umbenennen. Nicht taggen. Einfach in den Ordner bekommen. Das LLM übernimmt die Organisation im nächsten Schritt.
Ich startete mit 63 Artikeln über KI-Agenten-Architekturen — ein Mix aus Blogposts, Papers und meinen eigenen Projektnotizen. Das Gesamtvolumen lag bei etwa 180.000 Wörtern Rohmaterial.
Schritt 5: Die erste Wiki-Kompilierung erstellen.
Hier bringt man seinen LLM-Agenten ins Spiel. Wenn man Claude Code verwendet (was ich für diesen Workflow empfehle, weil es Dateioperationen nativ handhabt), zum Vault-Verzeichnis navigieren und einen Kompilierungs-Prompt ausführen.
Hier ist der Prompt, den ich für mein erstes Wiki verwendete:
Schau die Dateien in raw/ durch, die KI-Agenten-Architekturen, Multi-Agent-
Systeme oder Agent-Orchestrierungsmuster behandeln.
Erstelle ein Wiki unter wiki/ai-agent-architectures/ mit:
- Einer index.md, die jeden Artikel im Wiki mit einer Einzeiler-Beschreibung auflistet
- Einzelnen Artikeln für wichtige Konzepte (mindestens: Orchestrierungsmuster,
Tool-Use-Muster, Speicherarchitekturen, Multi-Agent-Kommunikation)
- Jeder Artikel sollte Informationen aus mehreren Rohquellen synthetisieren
- [[Backlinks]] zu verwandten Konzepten innerhalb des Wikis einfügen
- Am Ende jedes Artikels die Roh-Quelldateien auflisten, aus denen er schöpfte
- wiki/index.md (den Master-Index) erstellen falls nicht vorhanden,
und dieses Wiki hinzufügen
Claude Code las die relevanten Rohdateien durch, identifizierte die Kernkonzepte und generierte ein Wiki mit 11 Artikeln, einem umfassenden Index und Querverweisen dazwischen. Der gesamte Prozess dauerte etwa vier Minuten.
Die Ausgabequalität überraschte mich. Es war nicht bloße Zusammenfassung — es war echte Synthese. Ein Artikel über "Speicherarchitekturen für KI-Agenten" zog Erkenntnisse aus sieben verschiedenen Rohquellen, organisierte sie in einem kohärenten Rahmenwerk und notierte, wo zwei der Quellen sich beim Thema Langzeit-Speicher-Persistenz widersprachen.
Schritt 6: Den Master-Index einrichten.
Nach der ersten Kompilierung sollte wiki/index.md existieren. In Obsidian öffnen und verifizieren, dass es richtig aussieht. Mit der Erstellung weiterer Wikis wird diese Datei zum Einstiegspunkt des LLM — das Inhaltsverzeichnis der gesamten Wissensdatenbank.
Ein gesunder Master-Index sieht ungefähr so aus:
# Wissensdatenbank-Index
## Wikis
### KI-Agenten-Architekturen
Orchestrierungsmuster, Tool-Use, Speichersysteme und Multi-Agent-
Kommunikationsframeworks.
→ [[ai-agent-architectures/index]]
### Transformer-Skalierungsgesetze
Trainings-Compute, Parameteranzahlen, Datenanforderungen und
emergente Fähigkeiten über Modellgrößen hinweg.
→ [[transformer-scaling/index]]
Schritt 7: Die Wissensdatenbank befragen.
Jetzt kommt die Belohnung. Wenn man der Wissensdatenbank eine Frage stellen will, weist man Claude Code an, beim Master-Index zu beginnen:
Lies wiki/index.md um dich zu orientieren, was in meiner Wissensdatenbank
verfügbar ist. Beantworte dann diese Frage anhand der relevanten Wiki-
Artikel: [deine Frage hier]
Das LLM liest den Index, identifiziert das relevante Wiki, navigiert zu den spezifischen Artikeln und gibt eine Antwort basierend auf kompiliertem Wissen — mit Verweisen auf spezifische Artikel, die man verifizieren kann.
Pro-Tipp: Eine changelog.md zum Vault-Root hinzufügen. Jedes Mal, wenn man ein neues Wiki kompiliert oder ein bestehendes aktualisiert, Datum und Änderungen loggen. Karpathy empfiehlt ein konsistentes Präfix-Format wie ## [2026-04-05] ingest | Artikeltitel, damit das Log mit Standard-Unix-Tools parsebar wird. Dies gibt einem (und dem LLM) eine Zeitlinie, wie sich die Wissensdatenbank entwickelt hat.
Was Dies Richtig Macht, Was Traditionelles RAG Falsch Macht
Nachdem ich beide Systeme eine Woche parallel betrieben hatte — meine alte vektorbasierte RAG-Pipeline auf demselben Datensatz neben dem Karpathy-Stil-Wiki — bemerkte ich drei spezifische Vorteile, die nicht offensichtlich sind, bis man beide benutzt hat.
Der Synthese-Vorteil. Als ich mein Vektor-RAG-System fragte "Was sind die Trade-offs zwischen zentralisierter und dezentralisierter Agent-Orchestrierung?", gab es fünf Chunks aus drei verschiedenen Dokumenten zurück. Die Chunks waren relevant, aber ich musste sie selbst mental synthetisieren. Das Wiki-System hatte diese Synthese bereits während der Kompilierung durchgeführt. Der Artikel über Orchestrierungsmuster legte die Trade-offs in einem strukturierten Vergleich dar, schöpfte aus denselben Quelldokumenten, präsentierte sie aber als kohärentes Argument statt als Fragmente.
Der Entdeckungs-Vorteil. Die Backlink-Struktur des Wikis bringt Verbindungen zum Vorschein, nach denen man nicht gefragt hat. Als ich das Wiki-System zu Speicherarchitekturen befragte, verwies die Antwort auf einen Backlink zu einem Konzept im "Tool-Use-Muster"-Wiki, das ich mental nicht verknüpft hatte. Der Backlink existierte, weil das LLM während der Kompilierung bemerkte, dass das Speicher-Persistenz-Problem bei Agenten strukturell ähnlich dem Zustandsmanagement-Problem in Tool-Ketten ist. Vektorsuche findet diese Verbindungen nicht, weil sie nicht lexikalisch ähnlich sind — sie sind konzeptuell auf einer Ebene verwandt, die Verständnis erfordert, nicht Matching.
Der Transparenz-Vorteil. Wenn das Wiki-System mir eine Antwort gibt, kann ich die Quellartikel in Obsidian öffnen und sie selbst lesen. Ich kann sehen, was das LLM synthetisiert hat, ich kann prüfen, ob die Synthese korrekt ist, ich kann sie korrigieren, wenn sie falsch ist. Bei Vektor-RAG bekomme ich Chunks und Similarity-Scores. Zu debuggen, warum das System eine schlechte Antwort gab, bedeutet, durch Embeddings und Retrieval-Logs zu graben. Beim Wiki-System öffne ich eine Markdown-Datei und lese sie. Die Debug-Oberfläche ist menschlich lesbarer Text.
Wenn Sie lieber jemanden haben möchten, der ein vollständiges LLM-Wissensdatenbank-System aufbaut, das auf Ihren spezifischen Forschungs-Workflow zugeschnitten ist, nehme ich genau solche KI-Infrastruktur-Projekte an. Sie können sehen, was ich gebaut habe, auf fiverr.com/s/EgxYmWD.
Die Ehrlichen Einschränkungen — Wo Dieser Ansatz An Seine Grenzen Stößt
Ich würde Ihnen einen schlechten Dienst erweisen, wenn ich die Grenzen nicht klar darlege. Karpathys System ist brillant für seinen vorgesehenen Anwendungsfall, aber es hat reale Einschränkungen, die zählen.
Skalierungsdecke. Dieser Ansatz funktioniert für ungefähr 100-400 Artikel (bis zu etwa 400.000 Wörter Rohmaterial). Darüber hinaus beginnt das LLM mit der Aufrechterhaltung kohärenter Indexe zu kämpfen und die Kompilierungszeit wächst erheblich. Bei Tausenden von Dokumenten braucht man traditionelles RAG oder einen hybriden Ansatz. Der Break-even-Punkt hängt vom Kontextfenster des LLM ab — mit Opus 4.6s 1M Token-Kontext kann man weiter gehen als Karpathys ursprüngliche Schätzungen, aber es gibt immer noch eine praktische Obergrenze.
Kompilierungskosten. Jedes Mal, wenn signifikant neues Material hinzugefügt wird, muss das betroffene Wiki neu kompiliert werden. Das bedeutet LLM-Aufrufe, was Tokens bedeutet, was Geld bedeutet. Für ein Hobbyprojekt ist das vernachlässigbar. Für eine kontinuierlich aktualisierte Wissensdatenbank mit täglicher Aufnahme summieren sich die Kompilierungskosten. Ich habe festgestellt, dass Batching — Rohmaterial eine Woche sammeln und dann einmal kompilieren — die Kosten vertretbar hält.
Kein Echtzeit-Retrieval. Das Wiki ist eine Momentaufnahme. Wenn man vor zehn Minuten einen Artikel geclipt hat, aber das relevante Wiki nicht neu kompiliert hat, weiß das LLM bei einer Query nichts davon. Man kann es für kürzliche Ergänzungen auf den raw-Ordner verweisen, aber das ist ein manueller Schritt. Traditionelle RAG-Systeme indexieren neue Dokumente innerhalb von Sekunden nach der Aufnahme.
Einzelbenutzer-Design. Dies ist grundlegend ein persönliches Wissensmanagement-System. Es gibt keine Mehrbenutzerzugangskontrolle, keine Schutzvorrichtungen für gleichzeitiges Bearbeiten, keine Versionshistorie jenseits dessen, was Git bietet. Für Teams müsste man Kollaborationsinfrastruktur darüber bauen — an welchem Punkt man möglicherweise besser mit einem zweckgebauten RAG-System bedient ist.
LLM-Abhängigkeit. Die Qualität des Wikis ist direkt an die Qualität des kompilierenden LLM gekoppelt. Ich habe dies mit kleineren Modellen getestet und die Ergebnisse sind merklich schwächer — die Synthese ist oberflächlicher, die Querverweise sind weniger aufschlussreich und die Indexorganisation ist weniger intuitiv. Man will ein Frontier-Modell für den Kompilierungsschritt. Für Queries kann ein kleineres Modell oft ausreichen, weil es nur ein gut strukturiertes Wiki navigiert.
Das sind keine Dealbreaker. Es sind Designgrenzen. Karpathy baute dieses System für ein spezifisches Profil — einen individuellen Forscher oder Entwickler, der eine persönliche Wissensdatenbank moderater Größe verwaltet — und innerhalb dieser Grenzen funktioniert es besser als alles andere, was ich ausprobiert habe.
Was Ich Nach Einer Woche Anders Machen Würde
Meine erste Wiki-Kompilierung war schlampig. Nicht weil das LLM schlechte Arbeit leistete, sondern weil ich ihm zu viel Rohmaterial auf einmal gab ohne eine klare Themengrenze. Ich wies Claude Code auf 63 Artikel und sagte "mach ein Wiki über KI-Agenten." Das Ergebnis war ausschweifend — 11 Artikel, die alles von Prompt Engineering über Multi-Agent-Koordination bis Tool Calling abdeckten, mit Backlinks, die Konzepte verbanden, die nur im losesten Sinne verwandt waren.
Beim zweiten Mal war ich chirurgischer. Ich gruppierte meine Rohdateien vor der Kompilierung in grobe Themen-Cluster: 18 Artikel über Orchestrierungsmuster in einem Batch, 12 über Speicherarchitekturen in einem anderen, 15 über Tool-Use in einem dritten. Jedes wurde sein eigenes Wiki mit eigenem fokussiertem Index. Die Querverweise zwischen Wikis waren bedeutungsvoller, weil jedes Wiki einen klaren Umfang hatte.
Das ist meine größte praktische Lektion: Kompiliere eng, verlinke weit. Jedes Wiki sollte ein enges Thema abdecken. Die Verbindungen zwischen Wikis entstehen natürlich durch Backlinks, und diese Verbindungen sind wertvoller, wenn sie wirklich verschiedene Domänen überbrücken, statt benachbarte Absätze im selben ausufernden Thema zu verlinken.
Zweite Lektion: Die erste Kompilierung jedes Wikis manuell überprüfen. Das LLM trifft gelegentlich strukturelle Entscheidungen, die man selbst nicht treffen würde — Konzepte anders gruppieren als erwartet oder Artikel in einer Granularität erstellen, die nicht dazu passt, wie man über das Thema denkt. Ein 10-minütiger Review- und Umstrukturierungs-Durchgang nach der ersten Kompilierung bewahrt einen davor, strukturelle Probleme zu vervielfachen, wenn das Wiki wächst.
Dritte Lektion: Der raw-Ordner wird unordentlich, und das ist in Ordnung. Ich begann damit, Rohdateien in Unterordner nach Quellentyp zu organisieren. Das war verschwendete Mühe. Dem LLM ist egal, ob die Rohdateien organisiert sind. Es liest alle, extrahiert was relevant ist und ignoriert den Rest. Das Wiki soll die organisierte Schicht sein. Raw soll die Schublade sein.
Ich baue schon seit einer Weile persönliche Wissensmanagement-Systeme mit Obsidian — wenn Sie meine Anleitung gelesen haben, wie man Obsidian und Claude Code in ein zweites Gehirn verwandelt, erkennen Sie einige dieser Muster. Aber Karpathys Kompilierungsansatz geht weiter. Mein ursprüngliches Setup nutzte Obsidian hauptsächlich als Kontextquelle — das LLM auf Markdown-Dateien richten und lesen lassen. Karpathys Erkenntnis ist, dass das LLM auch die Wissensstruktur schreiben soll, nicht nur konsumieren.
Wo Dies in der RAG-Landschaft von 2026 Einzuordnen Ist
Das Timing von Karpathys Post war kein Zufall. Wir befinden uns an einem Wendepunkt, an dem sich die Werkzeuge zum Aufbau von Wissenssystemen in zwei Lager aufgespalten haben.
Lager eins: Schwergewichtige RAG-Plattformen mit Vektordatenbanken, Embedding-Pipelines, Reranking-Modellen und komplexen Retrieval-Strategien. Diese sind zweckgebaut für Enterprise-Skalierung — Millionen von Dokumenten, Tausende gleichzeitige Queries, strikte Latenzanforderungen. Sie funktionieren. Aber sie sind teuer zu bauen, teuer zu warten und Overkill für jeden, dessen Dokumentensammlung in einen Ordner passt.
Lager zwei: Was Karpathy "LLM Knowledge Bases" nennt. Markdown-Dateien, strukturierte Indexe, LLM-kompilierte Wikis. Null Infrastruktur jenseits eines Texteditors und einer LLM-API. Diese sind zweckgebaut für individuelle Forscher, Entwickler und kleine Teams, deren Wissensdatenbank in Hunderten von Artikeln gemessen wird, nicht Millionen.
Der Fehler, den die meisten machen, ist die Verwendung von Lager-eins-Werkzeugen für Lager-zwei-Probleme. Ich habe Solo-Entwickler gesehen, die Pinecone-Instanzen aufsetzen, um 40 Dokumente zu verwalten. Das ist kein Engineering, das ist lebenslaufgetriebene Architektur. Das richtige Werkzeug für eine 40-Dokumente-Wissensdatenbank ist ein Ordner mit Markdown-Dateien und ein smartes LLM.
Wenn die Bedürfnisse über das hinauswachsen, was der Markdown-first-Ansatz bewältigt, kann man jederzeit migrieren. Die Rohdateien sind Klartext. Die Wikis sind Klartext. Es gibt kein proprietäres Format, kein Vendor-Lock-in, keinen Migrations-Albtraum. Man nimmt seine Markdown-Dateien und speist sie in das System ein, zu dem man aufsteigt.
Das ist vielleicht der am meisten unterschätzte Aspekt von Karpathys Design: Es optimiert für den Ausgangsweg, nicht nur den Eingangsweg. Jedes Stück Wissen im System wird im portabelsten Format gespeichert, das möglich ist. Wenn Obsidian morgen verschwindet, funktionieren die Dateien immer noch in VS Code, Notion, Bear oder jedem anderen Markdown-Editor. Wenn man das System übersteigt, zieht der Inhalt mit um.
Wenn man Obsidian bereits mit Claude Code für persistenten Speicher nutzt — etwas, das ich ausführlich in meinem Beitrag darüber behandelt habe, warum Obsidian Claude Codes größte Schwäche behoben hat — ist Karpathys Wiki-Kompilierungsansatz der natürliche nächste Schritt. Man speichert bereits Kontext in Markdown. Jetzt lässt man das LLM diesen Kontext in etwas organisieren, durch das es intelligent navigieren kann.
Der Wandel, Der Mehr Ausmacht Als Die Technischen Details
Ich komme immer wieder auf eine einzige Unterscheidung zurück, die Karpathys Ansatz grundlegend anders anfühlen lässt als traditionelles RAG.
In einem traditionellen RAG-System ist das LLM ein Konsument. Es empfängt Chunks, liest sie und generiert eine Antwort. Die Wissensstruktur — die Embeddings, der Index, die Retrieval-Logik — wird von Engineering-Infrastruktur gebaut, nicht vom Modell selbst.
In Karpathys System ist das LLM sowohl Architekt als auch Bewohner. Es baut die Wissensstruktur während der Kompilierung. Es schreibt die Zusammenfassungen, erstellt die Links, organisiert den Index. Dann navigiert es bei Queries durch ein Haus, das es selbst entworfen hat. Es weiß, wo Dinge sind, weil es sie dort hingelegt hat.
Das ist kein kleiner technischer Unterschied. Es ist ein anderes Paradigma dafür, wie wir über LLMs und Wissen denken.
Der größte Teil der KI-Community in 2026 konzentriert sich darauf, Retrieval smarter zu machen — bessere Embeddings, besseres Reranking, bessere Chunk-Auswahl. Karpathy stellt eine grundlegend andere Frage: Was, wenn wir aufhören, das LLM als Suchmaschine zu behandeln, und anfangen, es als Forschungsbibliothekar zu behandeln? Nicht einer, der Bücher auf Anfrage findet, sondern einer, der bereits jedes Buch in der Sammlung gelesen hat, Zusammenfassungen jedes einzelnen geschrieben hat, einen querverweisenden Katalog erstellt hat und einen direkt zum richtigen Regal führen kann.
Diese Frage wird wichtiger, je größer die Kontextfenster werden. Mit Opus 4.6, das 1 Million Tokens verarbeitet, ist die Menge an Wissen, die ein LLM durch strukturierte Indexe navigieren kann — ohne jegliche Vektorsuche — bereits für die meisten persönlichen und kleinen Team-Anwendungsfälle praktikabel. Und die Kontextfenster werden nur größer.
Meine Vektordatenbank geht nirgendwo hin. Ich brauche sie immer noch für das Produktions-RAG-System, das ich für das 2-Millionen-Dokumente-Archiv eines Kunden gebaut habe. Aber für meine persönliche Wissensdatenbank? Für die Forschung, die ich über KI-Agenten betreibe, die Artikel, die ich lese, die Ideen, die ich sammle? Die Vektordatenbank ist ausgesteckt. Der Obsidian-Vault ist offen. Und zum ersten Mal fühlt sich meine Wissensdatenbank wie etwas an, das ich tatsächlich durchblättern kann, nicht nur abfragen.
Starten Sie mit 20 Artikeln über ein Thema, das Sie aktiv erforschen. Clippen Sie sie in raw. Führen Sie eine Kompilierung durch. Stellen Sie dem Wiki eine Frage. Sehen Sie, was es verbindet. Das Setup dauert eine Stunde. Der Moment, in dem es eine Verbindung zwischen zwei Ideen aufdeckt, die Sie selbst nicht verknüpft hatten — das ist der Punkt, an dem Sie verstehen, warum Karpathy dies gebaut hat, statt zu einer weiteren Vektordatenbank zu greifen.
Häufig Gestellte Fragen
Erfordert Karpathys Obsidian RAG-System Programmierkenntnisse?
Minimale Programmierkenntnisse sind nötig. Das System nutzt Obsidian (kostenlos, grafisch) für die Oberfläche und einen LLM-Agenten wie Claude Code für die Wiki-Kompilierung. Man schreibt Prompts in natürlicher Sprache, keinen Code. Grundlegende Kommandozeilen-Vertrautheit hilft, ist aber nicht strikt erforderlich.
Wie viele Dokumente kann das Obsidian-Wiki-System verarbeiten?
Karpathys Ansatz funktioniert gut für ungefähr 100-400 Artikel bis maximal 400.000 Wörter. Darüber hinaus wachsen die Kompilierungszeiten und die Indexkohärenz verschlechtert sich. Für größere Sammlungen ist ein hybrider Ansatz oder eine traditionelle RAG-Pipeline besser geeignet.
Kann ich GPT oder andere LLMs statt Claude Code für die Wiki-Kompilierung verwenden?
Ja. Karpathys GitHub-Gist erwähnt explizit Kompatibilität mit OpenAI Codex, Claude Code und anderen LLM-Agenten. Die Kompilierungsqualität hängt von der Reasoning-Fähigkeit des Modells ab — Frontier-Modelle produzieren merklich bessere Synthese und Querverweise als kleinere Modelle.
Was passiert, wenn Obsidian nicht mehr gepflegt wird?
Nichts geht kaputt. Jede Datei im System ist Klartext-Markdown, lokal auf der eigenen Maschine gespeichert. Man kann die gesamte Wissensdatenbank in VS Code, Notion, Bear oder jedem Texteditor öffnen. Es gibt null Vendor-Lock-in by Design.
Wie unterscheidet sich das davon, einfach Dateien in einen Ordner zu legen und ChatGPT zu verwenden?
Der entscheidende Unterschied ist der Kompilierungsschritt. Rohdateien, die in einen Chat geworfen werden, geben dem LLM unstrukturierten Kontext. Karpathys System lässt das LLM diese Dateien in strukturierte Wiki-Artikel kompilieren mit Indexen, Zusammenfassungen und Querverweisen — wodurch eine navigierbare Wissensstruktur entsteht statt eines Dokumentenstapels.
Lassen Sie Uns Zusammenarbeiten
Sie möchten KI-Systeme bauen, Workflows automatisieren oder Ihre Tech-Infrastruktur skalieren? Ich helfe gerne.
- Fiverr (Maßarbeit & Integrationen): fiverr.com/s/EgxYmWD
- Portfolio: mejba.me
- Ramlit Limited (Enterprise-Lösungen): ramlit.com
- ColorPark (Design & Branding): colorpark.io
- xCyberSecurity (Sicherheitsdienste): xcybersecurity.io
