

Skills CLAUDE.md de Karpathy : je l'ai installé. Verdict réel
Mardi dernier, j'ai demandé à Claude Code de corriger une seule vérification de null dans une classe de service Laravel. Une ligne. Un null-coalesce à la place d'un if imbriqué.
Il m'a renvoyé un diff de 214 lignes.
De nouvelles constantes de classe. Une méthode renommée. Quatre refactorings sans rapport sur des fichiers que je n'avais même pas ouverts. Un commentaire en bloc « tant qu'on y est » qui expliquait pourquoi l'auteur précédent s'était trompé. Le null check était enterré ligne 138, correct, entouré d'une réorganisation complète d'un fichier qui fonctionnait très bien depuis onze mois.
C'est ce comportement que le plugin Karpathy CLAUDE.md skills est conçu pour stopper. Et après l'avoir installé dans trois projets distincts — une codebase d'agence en Laravel 13, un build perso en Next.js 15, et le pipeline de contenu qui fait tourner ce blog — je suis prêt à te dire ce qui change vraiment, où les garde-fous tiennent, et où ils lâchent.
Si tu as lu mes notes de premier build sur le workflow Claude Routines avec Opus 4.7, tu sais déjà que je vis dans Claude Code à plein temps. Ce post est la suite naturelle : une fois que tu es dans Claude Code tous les jours, tu remarques exactement quels comportements te bouffent tes matinées — et le plugin Karpathy vise les quatre pires.
Pourquoi ce repo a atteint 71,5k étoiles en moins d'un mois
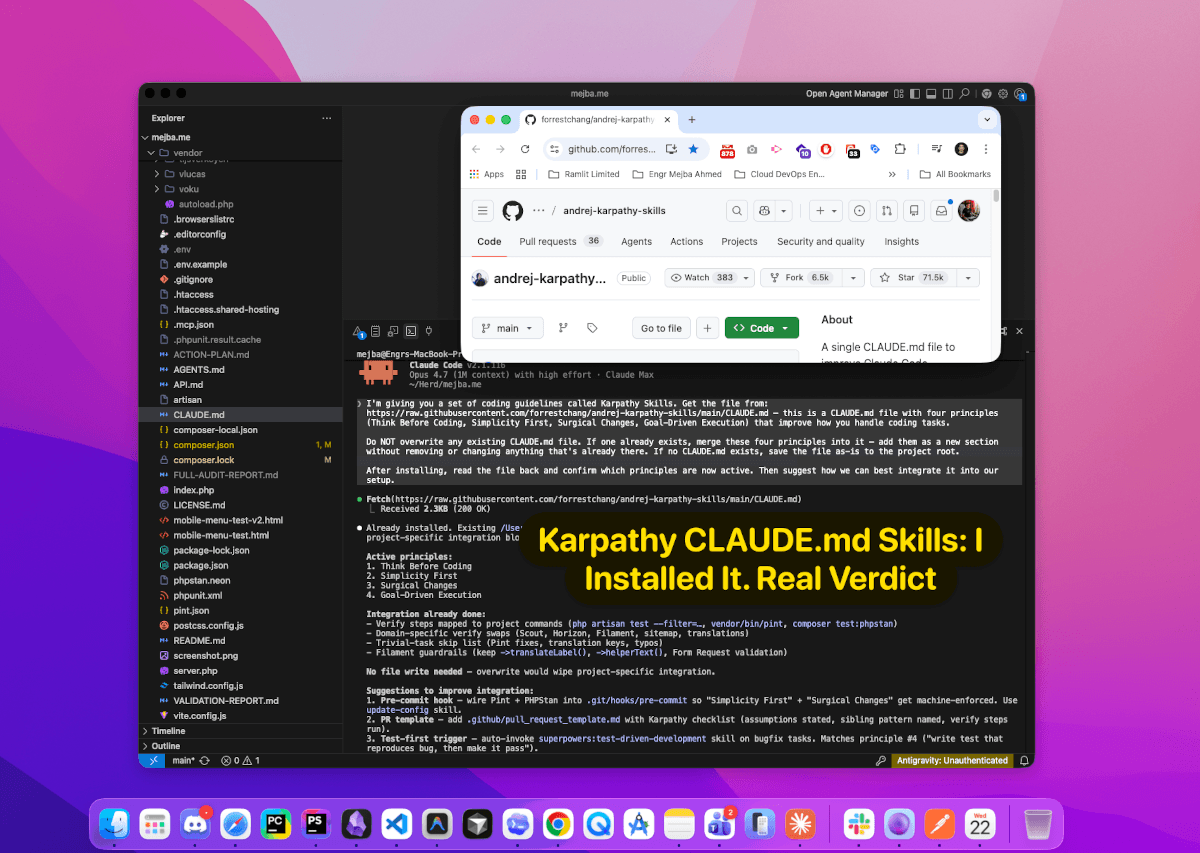
Le projet s'appelle andrej-karpathy-skills. Au moment où j'écris ceci, il est à 71,5k étoiles, 6,5k forks, 28 commits et 8 contributeurs. C'est un ratio étoiles/commits absurde. La plupart des repos qui trendent comme ça sont des frameworks de 50 000 lignes de code. Celui-ci se résume essentiellement à un seul fichier CLAUDE.md, plus un manifeste de plugin, un dossier skills, un dossier de règles Cursor et une poignée d'exemples.
C'est tout le produit. Un fichier markdown qui reformate le comportement de Claude Code.
La raison pour laquelle il a explosé est simple : il nomme les quatre modes d'échec que tout ingénieur en activité maudit dans son assistant IA depuis un an, et il emballe le correctif sous la forme de quatre principes nommés que Claude respecte réellement une fois qu'ils sont dans la fenêtre de contexte. Andrej Karpathy n'a pas écrit le repo (c'est l'œuvre de forrestchang), mais les principes sont directement distillés à partir des observations publiques de Karpathy sur X à propos des pièges du coding LLM — notamment sa célèbre description des assistants IA comme « un stagiaire junior savant un peu trop enthousiaste, avec une connaissance encyclopédique du software, mais qui te raconte des conneries en permanence, qui a une surabondance de courage et qui montre peu ou pas de goût pour le bon code ».
Cette citation résume tout le repo. Le stagiaire est brillant. Le stagiaire est aussi dangereux sans laisse.
Le plugin Karpathy CLAUDE.md skills, c'est la laisse.
Ce qu'il y a vraiment dans le repo
Avant l'installation, tu dois savoir ce que tu embarques. Voici l'arborescence à la racine :
.claude-plugin/
plugin.json
.cursor/
rules/
karpathy-guidelines.mdc
skills/
karpathy-guidelines/
SKILL.md
CLAUDE.md
CURSOR.md
EXAMPLES.md
README.md
README.zh.md
LICENSE
Quatre mécanismes de livraison, les mêmes quatre principes :
CLAUDE.md— le fichier drop-in pour les racines de projet Claude Code.claude-plugin/plugin.json— le manifeste pour le flux de plugin marketplace de Claude Codeskills/karpathy-guidelines/SKILL.md— la version au format skill compatible avec l'écosystème skills.sh que j'ai couvert plus tôt cette année.cursor/rules/karpathy-guidelines.mdc— l'équivalent Cursor, ajouté dans les derniers commits
Le manifeste de plugin est volontairement minuscule. Le voici mot pour mot :
{
"name": "andrej-karpathy-skills",
"description": "Behavioral guidelines to reduce common LLM coding mistakes, derived from Andrej Karpathy's observations on LLM coding pitfalls",
"version": "1.0.0",
"author": {
"name": "forrestchang"
},
"license": "MIT",
"keywords": ["guidelines", "best-practices", "coding", "karpathy"],
"skills": ["./skills/karpathy-guidelines"]
}
Une version, une référence à un skill, licence MIT. Aucune dépendance. Aucun script post-install. Aucune télémétrie. C'est le genre de repo que j'installe sans lire chaque octet — sauf que j'ai quand même lu chaque octet, et toi aussi tu devrais.
Maintenant, la partie intéressante. Les quatre principes eux-mêmes.
Les quatre principes, mot pour mot depuis le CLAUDE.md
Je vais les citer exactement comme ils apparaissent dans le fichier source, parce que les paraphraser leur fait perdre leur tranchant. La spécificité est le point clé.
1. Think Before Coding
"Don't assume. Don't hide confusion. Surface tradeoffs."
- Formule tes hypothèses explicitement. Si tu n'es pas sûr, demande.
- S'il existe plusieurs interprétations, présente-les — ne choisis pas en silence.
- Si une approche plus simple existe, dis-le. Conteste quand c'est justifié.
- Si quelque chose n'est pas clair, arrête-toi. Nomme ce qui est confus. Demande.
Mode d'échec que ça empêche : les hypothèses silencieuses. Le pire comportement absolu du coding assisté par IA. Tu demandes « un endpoint d'export utilisateurs » et tu récupères un téléchargement CSV qui balance tous les champs de la base parce que le modèle a décidé que c'est ce que tu voulais. Sans ce principe, Claude devine. Avec lui, Claude demande si l'export doit être scopé, quels champs sont sensibles, et si tu as besoin de JSON ou de CSV avant d'écrire une seule ligne.
2. Simplicity First
"Minimum code that solves the problem. Nothing speculative."
- Aucune fonctionnalité au-delà de ce qui a été demandé.
- Aucune abstraction pour du code à usage unique.
- Aucune « flexibilité » ou « configurabilité » non demandée.
- Aucune gestion d'erreur pour des scénarios impossibles.
- Si tu écris 200 lignes et que ça pourrait faire 50, réécris.
Mode d'échec que ça empêche : le problème du strategy-pattern-pour-un-seul-if. Tu demandes un calcul de remise et tu récupères un DiscountStrategyFactory abstrait avec des règles d'arrondi configurables, un enum de types de promotion et une dataclass DiscountContext. Le vrai problème, c'était price * 0.1. Ce principe explique pourquoi mes projets test sont passés d'implémentations surchargées de 180 lignes à des versions de 30 lignes sans perdre une seule vraie fonctionnalité. C'est le même pattern de sur-ingénierie que j'ai dénoncé sur trois des modèles dans mon roundup d'outils IA d'avril 2026 — presque tous les modèles frontière te construiront volontiers la cathédrale alors que tu demandais un cabanon.
3. Surgical Changes
"Touch only what you must. Clean up only your own mess."
- Ne « améliore » pas le code, les commentaires ou la mise en forme adjacents.
- Ne refactorise pas ce qui n'est pas cassé.
- Respecte le style existant, même si tu ferais autrement.
- Si tu remarques du code mort sans rapport, signale-le — ne le supprime pas.
- Supprime les imports/variables/fonctions que TES changements ont rendus inutilisés.
- Ne supprime pas le code mort préexistant sans qu'on te le demande.
Mode d'échec que ça empêche : le drive-by refactor. Le comportement exact qui m'a bouffé mon mardi matin. C'est le principe avec le plus gros impact ressenti. Une fois actif, le diff de 214 lignes devient un diff d'une ligne, et Claude te dit à la fin « j'ai remarqué que la classe a trois imports inutilisés d'un refactor d'il y a deux commits — tu veux que je m'en occupe séparément ? » au lieu de simplement les supprimer.
4. Goal-Driven Execution
"Define success criteria. Loop until verified."
- Transforme les tâches en objectifs vérifiables
- Pour les tâches en plusieurs étapes, énonce un plan bref avec étapes et vérifications
- Des critères de succès solides te permettent de boucler en autonomie
Mode d'échec que ça empêche : la finition « je crois que c'est bon » basée sur les vibes. La formulation de Karpathy lui-même sur ce point est la ligne la plus punchy de tout le repo : "LLMs are exceptionally good at looping until they meet specific goals… Don't tell it what to do, give it success criteria and watch it go." Une fois ce principe chargé, Claude arrête de dire « j'ai ajouté la limite de requêtes, préviens-moi s'il y a autre chose » et commence à dire « Limite de requêtes ajoutée. Plan de vérification : (a) curl 10 requêtes sous la limite, attendre des 200, (b) curl 11 et attendre un 429 à la dernière, (c) lancer la suite de tests existante. J'exécute maintenant. »
Ces quatre points, c'est tout le framework. Le reste de ce post, c'est comment les charger, comment les garder chargés, et comment savoir qu'ils fonctionnent.
Les trois chemins d'installation — et celui que tu veux vraiment
Le repo propose trois chemins d'installation parce qu'il existe trois contextes différents où tu pourrais vouloir ces principes actifs. J'ai testé les trois. Chacun a un cas d'usage spécifique, et les mélanger gaspille des tokens et provoque des collisions de règles.
Chemin A — L'installation via plugin Claude Code
C'est le chemin le plus propre si tu veux que les guidelines soient disponibles dans chaque session Claude Code sur ta machine, indépendamment de tout projet. Deux commandes :
/plugin marketplace add forrestchang/andrej-karpathy-skills
/plugin install andrej-karpathy-skills@karpathy-skills
Ce sont des slash commands que tu colles dans Claude Code lui-même, pas dans bash. La première ajoute le repo comme source du plugin marketplace. La seconde installe le plugin, ce qui enregistre le fichier skills/karpathy-guidelines/SKILL.md comme skill disponible. Claude le chargera automatiquement quand la session correspondra à la description d'activation du skill.
Où les fichiers atterrissent vraiment : Claude Code stocke les plugins installés sous ~/.claude/plugins/andrej-karpathy-skills/. Le manifeste du skill se trouve à ~/.claude/plugins/andrej-karpathy-skills/skills/karpathy-guidelines/SKILL.md. Tu peux vérifier avec :
ls -la ~/.claude/plugins/andrej-karpathy-skills/
cat ~/.claude/plugins/andrej-karpathy-skills/.claude-plugin/plugin.json
Quand l'utiliser : tu veux les principes actifs globalement, sur chaque repo, sans toucher aux fichiers de projet. Idéal pour les devs solo sur des machines où tu es le seul utilisateur.
Quand l'éviter : tu es sur une codebase d'équipe. Le chargement au niveau skill est par utilisateur, donc tes coéquipiers n'auront pas le même comportement. Pour la cohérence d'équipe, tu veux le chemin B.
Chemin B — Le drop-in (ou merge) CLAUDE.md à la racine du projet
C'est le chemin que j'utilise sur chaque vrai projet client. Les guidelines vivent dans le repo, sont versionnées avec le code, et chaque coéquipier qui lance Claude Code sur ce checkout obtient le même comportement automatiquement.
Si le projet n'a pas encore de CLAUDE.md, c'est une seule commande :
curl -o CLAUDE.md https://raw.githubusercontent.com/forrestchang/andrej-karpathy-skills/main/CLAUDE.md
Commit-le. Fini. La prochaine session claude dans ce dossier charge les quatre principes dans le contexte système avant ton premier message.
Si le projet a déjà un CLAUDE.md — ce qui est probablement le cas — ne l'écrase pas. J'ai fait ça une fois sur le repo ai-agents-team (celui qui fait tourner ce blog) et j'ai perdu toute ma config de génération de contenu pendant environ quatre-vingt-dix secondes avant de comprendre ce qu'il s'était passé et de la récupérer depuis git. Ne fais pas comme moi.
À la place, fusionne. Voici le workflow exact que j'utilise maintenant :
# 1. Fetch the Karpathy principles to a temp file
curl -o .karpathy-skills-temp.md https://raw.githubusercontent.com/forrestchang/andrej-karpathy-skills/main/CLAUDE.md
# 2. Append as a new section to your existing CLAUDE.md
{
echo ""
echo "---"
echo ""
echo "# Coding Behavior (Karpathy Guidelines)"
echo ""
echo "_Source: https://github.com/forrestchang/andrej-karpathy-skills — MIT_"
echo ""
cat .karpathy-skills-temp.md
} >> CLAUDE.md
# 3. Clean up the temp file
rm .karpathy-skills-temp.md
# 4. Verify the result opens cleanly and your original rules are still on top
head -40 CLAUDE.md
tail -60 CLAUDE.md
L'ordre des sections compte. Claude traite les règles placées plus tôt dans CLAUDE.md comme prioritaires en cas de conflit. Tu veux le comportement spécifique au projet (tes templates de contenu, tes conventions Laravel, tes règles de déploiement) en haut, et les principes Karpathy comme une section générale de comportement de code plus bas. Ce sont des méta-règles sur comment Claude devrait aborder le code — pas des règles de domaine sur quoi Claude devrait construire — donc elles vont à l'arrière du fichier, pas à l'avant.
Quand l'utiliser : toute codebase d'équipe, tout projet qui te tient à cœur sur le long terme, tout repo où tu veux un comportement d'agent versionné.
Chemin C — L'installation Cursor
Si tu es sur Cursor au lieu de Claude Code, le repo livre un fichier .cursor/rules/karpathy-guidelines.mdc qui fonctionne avec le système de règles de Cursor. Installe-le en copiant le fichier dans ton projet :
mkdir -p .cursor/rules
curl -o .cursor/rules/karpathy-guidelines.mdc \
https://raw.githubusercontent.com/forrestchang/andrej-karpathy-skills/main/.cursor/rules/karpathy-guidelines.mdc
Le moteur de règles de Cursor charge automatiquement tout fichier .mdc dans .cursor/rules/ à l'ouverture du projet, donc ça s'active dès la session suivante. Le contenu, ce sont les mêmes quatre principes au format règle Cursor — un fichier .mdc n'est que du markdown avec un petit bloc frontmatter qui déclare quand la règle s'applique.
Quand l'utiliser : tu es principalement sur Cursor. Je fais quand même tourner Claude Code pour le travail agentique, donc j'installe les deux — les fichiers n'entrent pas en conflit parce qu'ils sont dans des dossiers spécifiques à chaque outil.
Comment vérifier que c'est vraiment actif
Installer, c'est une chose. Savoir que ça fait quelque chose, c'en est une autre. Chaque système de skill/plugin que j'ai utilisé a un problème « est-ce que ça s'est chargé ? », et la réponse n'est jamais de faire confiance au message d'installation.
Voici ma vérification en trois étapes que je lance après chaque install :
Étape 1 — Test de restitution. Ouvre une session Claude Code fraîche dans le projet et demande :
« Quels principes de comportement de code sont actuellement chargés dans ton contexte ? Liste-les avec leur source. »
Si l'install a fonctionné, Claude listera les quatre principes Karpathy par leur nom — Think Before Coding, Simplicity First, Surgical Changes, Goal-Driven Execution — et citera le fichier CLAUDE.md ou le skill du plugin comme source. S'il liste des « bonnes pratiques de code » génériques sans les noms Karpathy, quelque chose cloche : soit le fichier n'a pas été sauvegardé, soit le plugin ne s'est pas installé, soit tu es dans un dossier que Claude ne considère pas comme la racine du projet.
Étape 2 — Test comportemental. Donne-lui une tâche spécifiquement conçue pour déclencher l'ancien mauvais comportement :
« Corrige le null check à la ligne 42 de UserService.php. »
Sans les guidelines : diff tentaculaire, refactor non sollicité, changements de style, l'expérience du mardi matin au complet. Avec les guidelines : Claude devrait faire exactement ce que tu as demandé, faire l'édition minimale, et signaler tout le reste qu'il a remarqué dans un message séparé au lieu de l'expédier.
Étape 3 — Piège au scope-creep. C'est celui qui te dit vraiment ce qu'il en est.
« Ajoute une limite de requêtes à l'endpoint de login. Tant que tu y es, ajoute aussi le logging des requêtes. »
Sans les guidelines : Claude fait les deux, les présente comme un seul changement, et y glisse probablement un refactor du middleware d'auth pour faire bonne mesure. Avec Goal-Driven Execution actif, Claude devrait séparer les tâches, énoncer les critères de succès pour chacune, et — c'est ça l'indice — proposer des vérifications pour la limite de requêtes spécifiquement avant de toucher à la tâche de logging. S'il les écrase en un seul gros changement non vérifié, les principes ne sont pas chargés correctement.
J'ai lancé ce test en trois étapes sur chaque install. Ça prend environ quatre minutes. Si tu le sautes, tu fais confiance à l'auto-déclaration du modèle pour savoir si les garde-fous sont levés, et l'auto-déclaration, c'est exactement la chose que ces principes ont été conçus pour ne pas croire.
Fusionner avec un setup existant (le cas du monde réel)
Tout ce qui précède suppose une install propre. Le cas plus difficile — et celui auquel la plupart des ingénieurs que je connais font vraiment face — c'est de fusionner ces principes dans un projet qui a déjà un CLAUDE.md avec ses propres règles bien arrêtées.
Le repo de ce blog est un bon exemple. Le projet ai-agents-team a un CLAUDE.md de génération de contenu qui définit les règles de voix d'Aria, les configurations de marque, les conventions de noms de fichiers, et une pile de contraintes dures (« pas de phrases IA de remplissage », « 3 000 mots minimum », « pas de frontmatter YAML dans les posts »). Les principes Karpathy parlent de comportement de code, pas de comportement de contenu, mais je voulais quand même les charger pour quand le travail d'Aria déborde sur du vrai code — quand je demande au repo de refactoriser une définition d'agent, de mettre à jour un hook ou d'ajouter un nouveau fichier skill.
La structure sur laquelle je me suis arrêté après quelques itérations :
# CLAUDE.md
<Project-specific identity and purpose goes first>
## Project Overview
...
## Architecture
...
## Hard Constraints
<Domain rules — these are non-negotiable and win any conflict>
...
---
# Coding Behavior (Karpathy Guidelines)
<Source: https://github.com/forrestchang/andrej-karpathy-skills — MIT>
<The four principles verbatim, dropped in as an appendix>
La règle horizontale avant la section de comportement de code est délibérée. Elle donne à Claude un indice structurel visuel que la section suivante traite d'une autre préoccupation — des méta-règles sur comment écrire du code, par opposition aux règles de domaine sur ce que le projet fait. Dans mes tests, Claude respecte cette séparation : quand j'édite du contenu, il suit les règles de contenu en haut ; quand j'édite du code, il tire la section Karpathy et l'applique.
Trois règles pour fusionner sans casser ton setup existant :
-
Les règles spécifiques au projet restent en haut. Ta voix de marque, tes choix de framework, tes conventions de noms de fichiers, ta liste de phrases interdites — ce sont des règles de domaine et elles doivent gagner en cas de conflit. Mets-les au-dessus de la section Karpathy.
-
Garde l'attribution de la source. Une ligne :
Source: https://github.com/forrestchang/andrej-karpathy-skills — MIT. C'est sous licence MIT donc tu es libre de l'intégrer, mais l'attribution compte pour deux raisons : elle permet au futur-toi de savoir d'où viennent les principes s'ils te semblent bizarres un jour, et elle signale à Claude (qui lit bien ce genre de choses) que cette section a une provenance externe. -
Ne mélange jamais la formulation des principes avec tes règles de projet. Si tu veux référencer Simplicity First dans une règle spécifique au projet (« applique Simplicity First ici — pas d'abstractions spéculatives »), c'est bon. Ce qui n'est pas bon, c'est de paraphraser les principes dans ta propre section de projet et de laisser tomber la formulation mot pour mot. La spécificité de la formulation originale est ce qui fait fonctionner les principes, et les reformuler avec tes propres mots émousse le tranchant dont Claude a besoin pour les reconnaître.
Ça ne remplace pas superpowers, skills, ni aucun des autres systèmes de comportement que tu as déjà chargés. Ça les complète. Les principes Karpathy sont étroits — ils gouvernent comment les changements de code se font, pas ce qu'est le projet, pas quels outils sont utilisés, pas quelles sont tes conventions de domaine. Empilés au-dessus d'un CLAUDE.md de projet solide, c'est un upgrade net. Empilés à la place d'un, ils laissent Claude sans contexte de domaine et tu détesteras le résultat.
Un exemple concret tiré de ma propre stack : le pipeline de ce blog utilise le skill Claude de SEO programmatique que j'ai construit plus tôt pour l'optimisation on-page automatisée. Ce skill vit au-dessus de la section Karpathy dans mon CLAUDE.md parce que c'est une règle de domaine — il définit ce qui est écrit. Les principes Karpathy sont en dessous parce que ce sont des méta-règles — ils définissent comment le code derrière ce skill est édité quand je le refactorise. Préoccupations séparées, sections séparées, aucune collision.
Mon verdict tranché — où ça gagne, où ça perd
Je t'épargne la version diplomatique. Voici la prise de position directe après une semaine d'usage :
Où ça gagne — et ça gagne fort : les quatre modes d'échec exacts qui ont fait passer le coding assisté par IA de « incroyable » à « frustrant » sur l'année écoulée. Hypothèses silencieuses. Sur-ingénierie. Drive-by refactors. Finition aux vibes « je crois que j'ai fini ». Les quatre sont maintenant mesurablement moins fréquents dans mes sessions. L'incident du null check de 214 lignes du mardi matin ne s'est plus reproduit depuis que je l'ai installé. La taille moyenne de mes diffs pour les petites tâches de correction de bug a baissé significativement — le schéma constant sur les trois projets, c'est à peu près un tiers du nombre de lignes pour la même tâche, sans aucune perte de justesse.
Le principe Goal-Driven Execution est le sleeper. Il a l'air du plus ennuyeux des quatre, mais c'est celui qui change le plus ton workflow. Une fois que Claude commence à énoncer ses critères de vérification en amont, tu arrêtes d'écrire des prompts comme « ajoute de la validation » et tu commences à écrire des prompts comme « ajoute la validation pour les emails vides — succès = le cas de test X passe ». Ce seul changement m'a rendu mesurablement meilleur comme prompteur, ce qui est un effet secondaire bizarre à obtenir en installant le fichier markdown de quelqu'un d'autre.
Où c'est limité : quatre principes ne remplacent pas la connaissance de domaine. Claude avec les guidelines Karpathy chargées ne sait toujours pas que ta codebase Laravel utilise des form requests au lieu de validation inline, ni que ton projet React utilise des server components partout, ni que ton API renvoie du snake_case sur ce seul endpoint pour des raisons de legacy. Les principes empêchent Claude d'aggraver les choses — ils ne rendent pas Claude plus malin sur ta stack spécifique. Il te faut toujours un CLAUDE.md spécifique au projet. Il te faut toujours des skills. Il te faut toujours de bons prompts.
Là où ça m'agace activement : pour les tâches triviales, les principes ajoutent de la friction. Demander à Claude de renommer une variable me vaut maintenant parfois une confirmation de trois lignes sur le scope avant que le renommage se fasse. Les guidelines elles-mêmes reconnaissent ce point (« les guidelines biaisent vers la prudence plutôt que la vitesse — utile pour le travail non trivial tout en gardant du jugement pour les tâches simples »), mais en pratique, le modèle ne distingue pas toujours. J'ai développé l'habitude personnelle d'ajouter « changement trivial unique, pas besoin de vérification » aux prompts où je sais que le scope est de deux caractères. Ça marche. Mais c'est un contournement, pas une solution.
Installe-le si : tu écris du vrai code pour de vrais projets, tu travailles quotidiennement avec des assistants IA, et tu as été mordu par du scope creep, des hypothèses silencieuses ou des drive-by refactors dans le dernier mois. La barre de valeur est assez basse ici pour que quiconque expédie du code en prod devrait déjà l'avoir installé.
Passe ton chemin si : tu utilises Claude Code purement pour du prototypage jetable, du travail de spike, ou du vibe-coding où la vitesse compte plus que la discipline de scope. Les guidelines te gêneront. Elles ne sont pas conçues pour le mode que Karpathy lui-même a décrit comme « se laisser complètement aller aux vibes, embrasser les exponentielles, et oublier que le code existe même ». Elles sont conçues pour le mode qu'il a décrit plus tard — celui où tu es « lent, défensif, prudent, paranoïaque » à propos du code qui te tient vraiment à cœur.
Pour le pipeline de ce blog et tout projet client que je livre actuellement, elles sont dedans. Pour l'expérimentation du week-end, elles sont dehors. C'est la ligne de partage honnête.
Avant et après — le null check revisité
Laisse-moi boucler la boucle que j'ai ouverte en haut de ce post.
J'ai relancé la tâche du mardi matin après avoir installé les guidelines. Même codebase, même fichier, même ligne, même prompt : « Corrige le null check à la ligne 138 de UserService.php — $user->profile->avatar doit retomber sur une valeur par défaut si le profile est null. »
Avant les guidelines (représentatif de ce qui s'était passé la première fois) :
- Diff de 214 lignes
- Nouvelle constante de classe
DEFAULT_AVATAR - Méthode renommée de
getAvatar()enresolveAvatar()pour « plus de clarté » - Quatre correctifs null-coalesce sans rapport dans des méthodes que je n'avais pas mentionnées
- Un commentaire en bloc expliquant pourquoi l'approche de l'auteur d'origine était sous-optimale
- Le vrai correctif du null check, correct, à la ligne 138, entouré de tout ce qui précède
Après les guidelines (relancé sur une branche fraîche depuis le même état de départ) :
- Diff d'une ligne
$user->profile?->avatar ?? asset('images/default-avatar.png')à la ligne 138- Un message séparé à la fin : « J'ai remarqué quatre autres endroits dans ce fichier où
->profile->est accédé sans null check. Même pattern, méthodes différentes. Tu veux que je m'en occupe dans un commit séparé, ou je les laisse ? »
Correctif d'une ligne. Remontée explicite du problème adjacent. Aucun refactor livré en silence. Le modèle voyait toujours les problèmes adjacents — c'est la même intelligence — mais les guidelines ont converti la réponse de « laisse-moi tout gérer » à « laisse-moi signaler et à toi de décider ».
C'est toute la proposition de valeur dans un seul avant/après. Le modèle ne devient pas plus con. Il devient discipliné.
Il y a une raison pour laquelle le repo a franchi les 71k étoiles en moins d'un mois. Chaque ingénieur en activité a une version de cette histoire du mardi matin, et chacun d'entre nous a voulu un moyen de l'arrêter sans écrire des system prompts de 50 lignes pour essayer d'expliquer, avec nos propres mots, ce que signifie « pas de drive-by refactor ». Les principes Karpathy le font en quatre sections nommées, avec une formulation assez tranchante pour que Claude les suive réellement, pour le prix d'une seule commande curl. C'est un deal que je prends à chaque fois.
Maintenant, la seule question qui vaille, c'est celle que tu devrais te poser en fermant cet onglet : quand est-ce que ton assistant IA a fait un changement trois fois plus gros que ce que tu avais demandé, pour la dernière fois ? Si la réponse est « cette semaine », tu sais déjà quoi faire ensuite.
Questions fréquentes
Qu'est-ce que le plugin Karpathy CLAUDE.md skills ?
Le plugin Karpathy CLAUDE.md skills est un unique fichier CLAUDE.md (plus un manifeste de plugin, un dossier skill et un dossier de règles Cursor) qui charge quatre principes de comportement de code dans Claude Code, dérivés des observations publiques d'Andrej Karpathy sur les pièges du coding LLM. Il est sous licence MIT, livré sur github.com/forrestchang/andrej-karpathy-skills, et il a atteint 71,5k étoiles uniquement par le bouche-à-oreille.
Quels sont les quatre principes Karpathy pour Claude Code ?
Les quatre principes sont Think Before Coding (faire émerger les hypothèses, demander quand il y a doute), Simplicity First (code minimum qui résout le problème, pas de fonctionnalités spéculatives), Surgical Changes (ne toucher qu'à ce qu'il faut, pas de drive-by refactors) et Goal-Driven Execution (définir des critères de succès vérifiables, boucler jusqu'à vérification). Voir le détail mot pour mot plus haut pour les listes complètes.
Comment j'installe le CLAUDE.md Karpathy dans un projet existant ?
Lance curl -o .karpathy-skills-temp.md https://raw.githubusercontent.com/forrestchang/andrej-karpathy-skills/main/CLAUDE.md, puis ajoute-le à ton CLAUDE.md existant comme une nouvelle section « Coding Behavior » en bas. N'écrase jamais un CLAUDE.md existant — les règles spécifiques au projet doivent rester au-dessus de la section Karpathy pour l'emporter en cas de conflit. Le workflow de merge complet est documenté plus haut.
Est-ce que ça remplace les skills ou superpowers de Claude Code ?
Non. Les principes Karpathy sont des méta-règles sur comment les changements de code se font — ils ne connaissent pas ta stack, tes conventions ni ton domaine. Empile-les au-dessus de ton CLAUDE.md de projet existant, de tes skills et de tes autres systèmes de comportement. Ils complètent, ils ne remplacent pas. Si tu installes ça comme seule config, Claude sera discipliné mais aveugle au domaine.
Comment je vérifie que les principes Karpathy sont réellement chargés ?
Lance un check en trois étapes : (1) demande à Claude de lister les principes de comportement de code dans son contexte et confirme que les quatre noms Karpathy apparaissent, (2) donne-lui une petite tâche de correction de bug et vérifie que le diff reste chirurgical, (3) donne-lui un piège au scope creep (« corrige X, tant que tu y es fais aussi Y ») et confirme qu'il sépare les tâches avec des critères de vérification au lieu de les écraser ensemble. Si une étape échoue, l'install n'a pas pris.
Travaillons ensemble
Tu cherches à construire des systèmes IA, à automatiser des workflows ou à faire passer à l'échelle ton infra tech ? Ça me ferait plaisir de t'aider.
- Fiverr (builds et intégrations sur mesure) : fiverr.com/s/EgxYmWD
- Portfolio : mejba.me
- Ramlit Limited (solutions entreprise) : ramlit.com
- ColorPark (design et branding) : colorpark.io
- xCyberSecurity (services de sécurité) : xcybersecurity.io



